An Interesting Cache Coherence Vulnerability in the Mali GPU Driver
CVE-2023-4272, reported by Google researcher Jann Horn, is a very interesting vulnerability in the Mali GPU driver. It involves insufficient cache invalidation, allowing an attacker to read stale data from main memory (DRAM). This is a powerful issue because the stale data may contain sensitive information, depending on previous memory usage. Moreover, the root cause of this vulnerability is quite fascinating!
I’m grateful for the report and for the author’s friendly answers to my questions, which helped me learn more about caching. In this post, I’ll share some of my thoughts and notes on this vulnerability, hoping it can be a helpful reference for others who, like me, are interested in this kind of bug but not yet very familiar with it.
P.S. Readers without a background in the Mali GPU driver should still be able to follow along.
1. Mali Background
1.1. Importing Buffer from User
Users can open the /dev/mali device and use ioctl calls to interact with the Mali GPU driver. The driver supports importing user-provided buffers, which means a user can first create anonymous memory and later import it as backing memory for the GPU. It is done by ioctl command KBASE_IOCTL_MEM_IMPORT, and the execution flow with some comments is as follows:
// The fops of /dev/mali
static const struct file_operations kbase_fops = {
// [...]
.unlocked_ioctl = kbase_ioctl, // <--------------
// [...]
};
static long kbase_ioctl(struct file *filp, unsigned int cmd, unsigned long arg)
{
// [...]
switch (cmd) {
// [...]
case KBASE_IOCTL_MEM_IMPORT:
KBASE_HANDLE_IOCTL_INOUT(KBASE_IOCTL_MEM_IMPORT,
kbase_api_mem_import, // <--------------
union kbase_ioctl_mem_import,
kctx);
break;
// [...]
}
}
static int kbase_api_mem_import(struct kbase_context *kctx,
union kbase_ioctl_mem_import *import /* user-controlled */)
{
// [...]
ret = kbase_mem_import(kctx, // <--------------
import->in.type,
u64_to_user_ptr(import->in.phandle),
import->in.padding,
/* ... */);
// [...]
}
int kbase_mem_import(struct kbase_context *kctx, enum base_mem_import_type type,
void __user *phandle, u32 padding, u64 *gpu_va, u64 *va_pages,
u64 *flags)
{
// [...]
switch (type) {
case BASE_MEM_IMPORT_TYPE_USER_BUFFER:
// [...]
reg = kbase_mem_from_user_buffer(kctx, // <--------------
(unsigned long)uptr, user_buffer.length,
va_pages, flags);
// [...]
}
// [...]
}
The function kbase_mem_from_user_buffer() is called internally. It first allocates a region object (struct kbase_va_region) [1], and then an allocation object (struct kbase_mem_phy_alloc) to track memory usage status [2]. The nr_pages field [3] records how many pages have been imported, while the pages field stores the imported pages [4], which can be lazily initialized when the pages are actually mapped.
To ensure the user-provided address is valid, the function calls get_user_pages() to fault in the pages and install the corresponding PTEs [5]. Finally, the nents field, which tracks the number of mapped pages, is set to zero at this stage [6].
static struct kbase_va_region *kbase_mem_from_user_buffer(
struct kbase_context *kctx, unsigned long address,
unsigned long size, u64 *va_pages, u64 *flags)
{
// [...]
reg = kbase_alloc_free_region(rbtree, 0, *va_pages, zone); // [1]
reg->gpu_alloc = kbase_alloc_create( // [2]
kctx, *va_pages, KBASE_MEM_TYPE_IMPORTED_USER_BUF,
BASE_MEM_GROUP_DEFAULT);
reg->cpu_alloc = kbase_mem_phy_alloc_get(reg->gpu_alloc);
// [...]
user_buf = ®->gpu_alloc->imported.user_buf;
// [...]
user_buf->nr_pages = *va_pages; // [3]
// [...]
user_buf->pages = kmalloc_array(*va_pages, // [4]
sizeof(struct page *), GFP_KERNEL);
// [...]
faulted_pages = // [5]
get_user_pages(address, *va_pages, write ? FOLL_WRITE : 0, pages /* NULL */, NULL);
// [...]
reg->gpu_alloc->nents = 0; // [6]
// [...]
return reg;
}
1.2. Mapping the Imported Buffer
After importing buffers from user space, the kernel returns a GPU virtual address to the user for memory mapping. The user can then map it by invoking the SYS_mmap system call, using the GPU virtual address as the page offset parameter. The mmap handler looks up the corresponding region object (struct kbase_va_region) based on the page offset [1], and returns the region object that was previously allocated in kbase_mem_from_user_buffer().
static const struct file_operations kbase_fops = {
// [...]
.mmap = kbase_mmap, // <--------------
// [...]
};
static int kbase_mmap(struct file *const filp, struct vm_area_struct *const vma)
{
struct kbase_file *const kfile = filp->private_data;
struct kbase_context *const kctx =
kbase_file_get_kctx_if_setup_complete(kfile);
// [...]
return kbase_context_mmap(kctx, vma); // <--------------
}
int kbase_context_mmap(struct kbase_context *const kctx,
struct vm_area_struct *const vma)
{
struct kbase_va_region *reg = NULL;
// [...]
switch (vma->vm_pgoff) {
// [...]
default: {
reg = kbase_region_tracker_find_region_enclosing_address(kctx, // [1]
(u64)vma->vm_pgoff << PAGE_SHIFT);
// some checks
// [...]
}
}
// [...]
err = kbase_cpu_mmap(kctx, reg, vma, kaddr, nr_pages, aligned_offset, // <--------------
free_on_close);
// [...]
}
The function kbase_cpu_mmap() sets the function table of the current VMA to kbase_vm_ops [2], whose page fault handler is kbase_cpu_vm_fault() [3].
static int kbase_cpu_mmap(struct kbase_context *kctx,
struct kbase_va_region *reg,
struct vm_area_struct *vma,
/* ... */)
{
// [...]
map = kzalloc(sizeof(*map), GFP_KERNEL);
// [...]
vma->vm_ops = &kbase_vm_ops; // [2]
vma->vm_private_data = map;
// [...]
map->alloc = kbase_mem_phy_alloc_get(reg->cpu_alloc);
// [...]
}
const struct vm_operations_struct kbase_vm_ops = {
// [...]
.fault = kbase_cpu_vm_fault // [3]
};
1.3. External Resource in Job
The ioctl command KBASE_IOCTL_JOB_SUBMIT is used to submit a job to the GPU. Internally, the function kbase_jd_submit() copies job data from user [1] and calls jd_submit_atom() to submit the job [2].
static long kbase_ioctl(struct file *filp, unsigned int cmd, unsigned long arg)
{
// [...]
switch (cmd) {
// [...]
case KBASE_IOCTL_JOB_SUBMIT:
KBASE_HANDLE_IOCTL_IN(KBASE_IOCTL_JOB_SUBMIT,
kbase_api_job_submit, // <--------------
struct kbase_ioctl_job_submit,
kctx);
break;
// [...]
}
}
static int kbase_api_job_submit(struct kbase_context *kctx,
struct kbase_ioctl_job_submit *submit)
{
return kbase_jd_submit(kctx, u64_to_user_ptr(submit->addr), // <--------------
submit->nr_atoms,
submit->stride, false);
}
int kbase_jd_submit(struct kbase_context *kctx,
void __user *user_addr, u32 nr_atoms, u32 stride,
bool uk6_atom)
{
// [...]
for (i = 0; i < nr_atoms; i++) {
struct base_jd_atom user_atom;
// [...]
copy_from_user(&user_atom, user_addr, stride); // [1]
// [...]
need_to_try_schedule_context |= jd_submit_atom(kctx, &user_atom, // [2]
&user_jc_incr, katom);
}
}
If the job request specifies external resources using the BASE_JD_REQ_EXTERNAL_RESOURCES flag, jd_submit_atom() will invoke kbase_jd_pre_external_resources() [3] to prepare them. This function first copies the metadata of the resources [4], then iterates over the metadata entries [5].
For each entry, it looks up the corresponding region object using the ext_resource field [6], and calls kbase_map_external_resource() with the retrieved object as a parameter [7].
static bool jd_submit_atom(struct kbase_context *const kctx,
const struct base_jd_atom *const user_atom,
const struct base_jd_fragment *const user_jc_incr,
struct kbase_jd_atom *const katom)
{
// [...]
if (katom->core_req & BASE_JD_REQ_EXTERNAL_RESOURCES) {
if (kbase_jd_pre_external_resources(katom, user_atom) != 0) { // [3]
katom->event_code = BASE_JD_EVENT_JOB_INVALID;
return kbase_jd_done_nolock(katom, true);
}
}
// [...]
}
static int kbase_jd_pre_external_resources(struct kbase_jd_atom *katom, const struct base_jd_atom *user_atom)
{
// [...]
input_extres = kmalloc_array(katom->nr_extres, sizeof(*input_extres), GFP_KERNEL);
// [...]
copy_from_user(input_extres,
get_compat_pointer(katom->kctx, user_atom->extres_list),
sizeof(*input_extres) * katom->nr_extres); // [4]
for (res_no = 0; res_no < katom->nr_extres; res_no++) {
struct base_external_resource *user_res = &input_extres[res_no]; // [5]
// [...]
reg = kbase_region_tracker_find_region_enclosing_address(
katom->kctx, user_res->ext_resource & ~BASE_EXT_RES_ACCESS_EXCLUSIVE); // [6]
// [...]
err = kbase_map_external_resource(katom->kctx, reg, current->mm); // [7]
// [...]
}
}
If the backing memory of the region consists of imported user buffers [8], the function kbase_jd_user_buf_map() is called to handle the mapping.
int kbase_map_external_resource(struct kbase_context *kctx, struct kbase_va_region *reg,
struct mm_struct *locked_mm)
{
// [...]
switch (reg->gpu_alloc->type) {
case KBASE_MEM_TYPE_IMPORTED_USER_BUF: { // [8]
// [...]
err = kbase_jd_user_buf_map(kctx, reg);
// [...]
}
// [...]
}
}
kbase_jd_user_buf_map() first calls kbase_jd_user_buf_pin_pages() to load page objects [9] and update the number of mapped pages, stored in alloc->nents [10]. It then calls dma_map_page() to perform DMA (Direct Memory Access) mapping on a specific memory region within the page. This memory region is configured during user buffer import, and its start address [11] and size [12] may not be page-aligned.
The returned DMA address is stored in the allocation object [13], and kbase_mmu_insert_pages() is subsequently called to establish the GPU’s memory mapping [14] by inserting PTEs into the MMU table.
static int kbase_jd_user_buf_map(struct kbase_context *kctx,
struct kbase_va_region *reg)
{
err = kbase_jd_user_buf_pin_pages(kctx, reg);
// [..]
address = alloc->imported.user_buf.address; // [11]
offset_within_page = address & ~PAGE_MASK;
remaining_size = alloc->imported.user_buf.size; // [12]
// [..]
for (i = 0; i < pinned_pages; i++) {
unsigned long map_size =
MIN(PAGE_SIZE - offset_within_page, remaining_size);
dma_addr_t dma_addr = dma_map_page(dev, pages[i],
offset_within_page, map_size,
DMA_BIDIRECTIONAL);
// [...]
alloc->imported.user_buf.dma_addrs[i] = dma_addr; // [13]
pa[i] = as_tagged(page_to_phys(pages[i]));
remaining_size -= map_size;
offset_within_page = 0;
}
err = kbase_mmu_insert_pages(kctx->kbdev, &kctx->mmu, reg->start_pfn, pa, // [14]
kbase_reg_current_backed_size(reg), reg->flags & gwt_mask,
kctx->as_nr, alloc->group_id, mmu_sync_info, NULL, true);
// [...]
return 0;
}
int kbase_jd_user_buf_pin_pages(struct kbase_context *kctx,
struct kbase_va_region *reg)
{
// [...]
struct kbase_mem_phy_alloc *alloc = reg->gpu_alloc;
struct page **pages = alloc->imported.user_buf.pages;
// [...]
pinned_pages = pin_user_pages_remote(mm, address, alloc->imported.user_buf.nr_pages, // [9]
write ? FOLL_WRITE : 0, pages, NULL, NULL);
alloc->nents = pinned_pages; // [10]
// [...]
}
2. ARM Cache Background
2.1. Cache Mechanism
I’m no CPU architecture expert, but I tried to dig into the official docs and make sense of things as best I could.
In the ARM Cortex-A (ARMv7-A) Series Programmer’s Guide, the Caches section provides a clear introduction to the ARM cache mechanism.
In many ARM processors, accessing DRAM incurs significant overhead. To mitigate this, a cache — a small and fast memory block — is placed between the CPU and the main memory. When the CPU attempts to read or write a particular address, it first checks the cache. If the address is found there, the CPU uses the cached data instead of accessing the main memory.
--------------
| CPU |
-------------- -------------
| Cache | | |
-------------- | |
| | main |
| | memory |
| | |
| | |
| | |
| -------------
| |
--------------------------------------
| Bus |
--------------------------------------
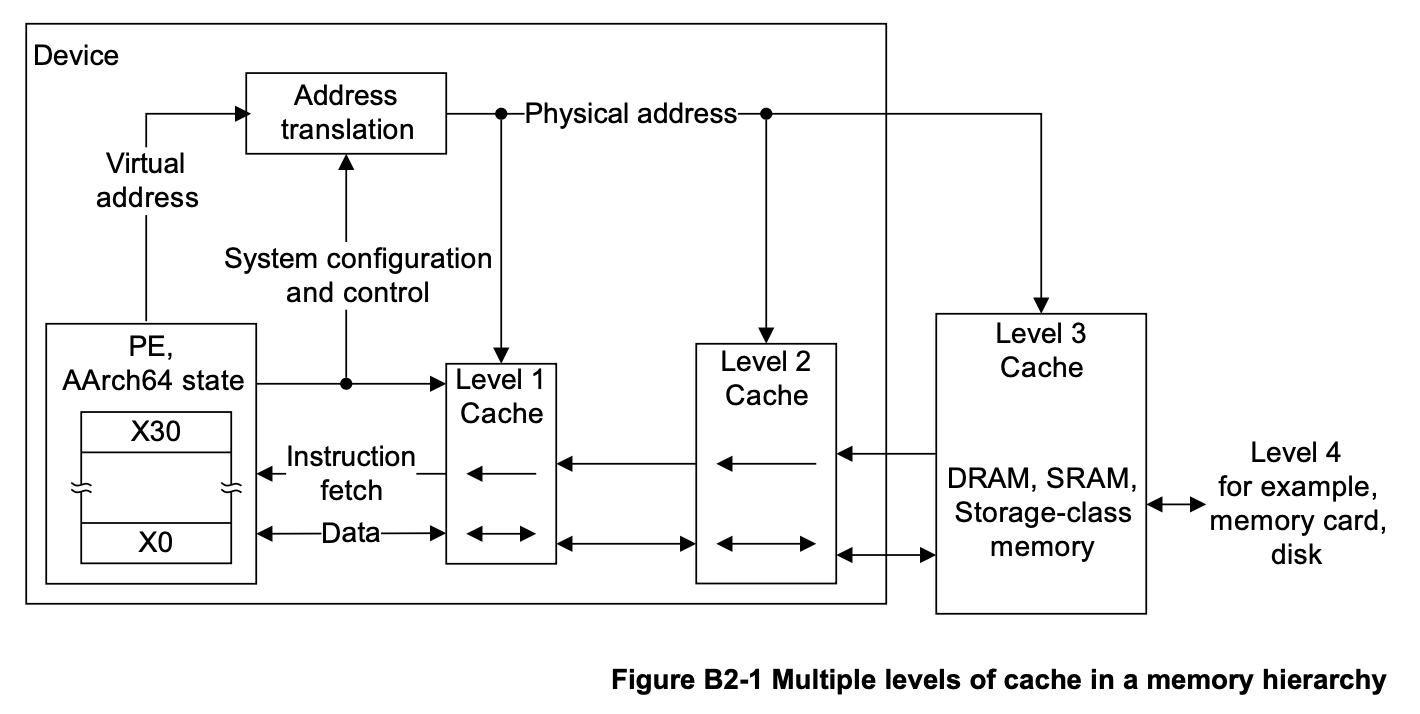
As the Memory hierarchy section says, the cache is further divided into two levels: L1 and L2. The L1 cache is directly connected to the CPU and handles instruction fetches as well as load/store operations. Instructions are cached in the L1 instruction cache (I-cache), while loaded and stored data are cached in the L1 data cache (D-cache).
The L2 cache is larger than the L1 cache but also slower. It is unified, meaning it stores both data and instructions. It also serves as a shared cache for multiple cores and acts as a fallback when data is not found in L1.
The L2 cache actually includes an intergrated SCU (System Controller Unit), which connects the CPUs within a cluster. For more details about L2 memory system, please refer to the About the L2 memory system section.
-------------------
| CPU |
------------------- -------------
| L1 | L1 | | |
| d-cache | i-cache | | |
------------------- | main |
| | memory |
------------------- | |
| L2 Cache | | |
------------------- | |
| -------------
| |
--------------------------------------
| Bus |
--------------------------------------
Page 281 of the Arm Architecture Reference Manual for A-profile architecture illustrates the complete memory hierarchy:
2.2. Non-Cacheable Normal Memory
According to usage, ARM memory can be classified into two types: normal memory and device memory. The former is used in most situations, such as DRAM, while the latter refers to memory-mapped I/O (MMIO) regions.
To determine the memory type and its associated attributes for a given physical address, the AttrIndx[] bits in a page table entry (PTE) specify which attribute in the MAIR_EL1 register should be used.
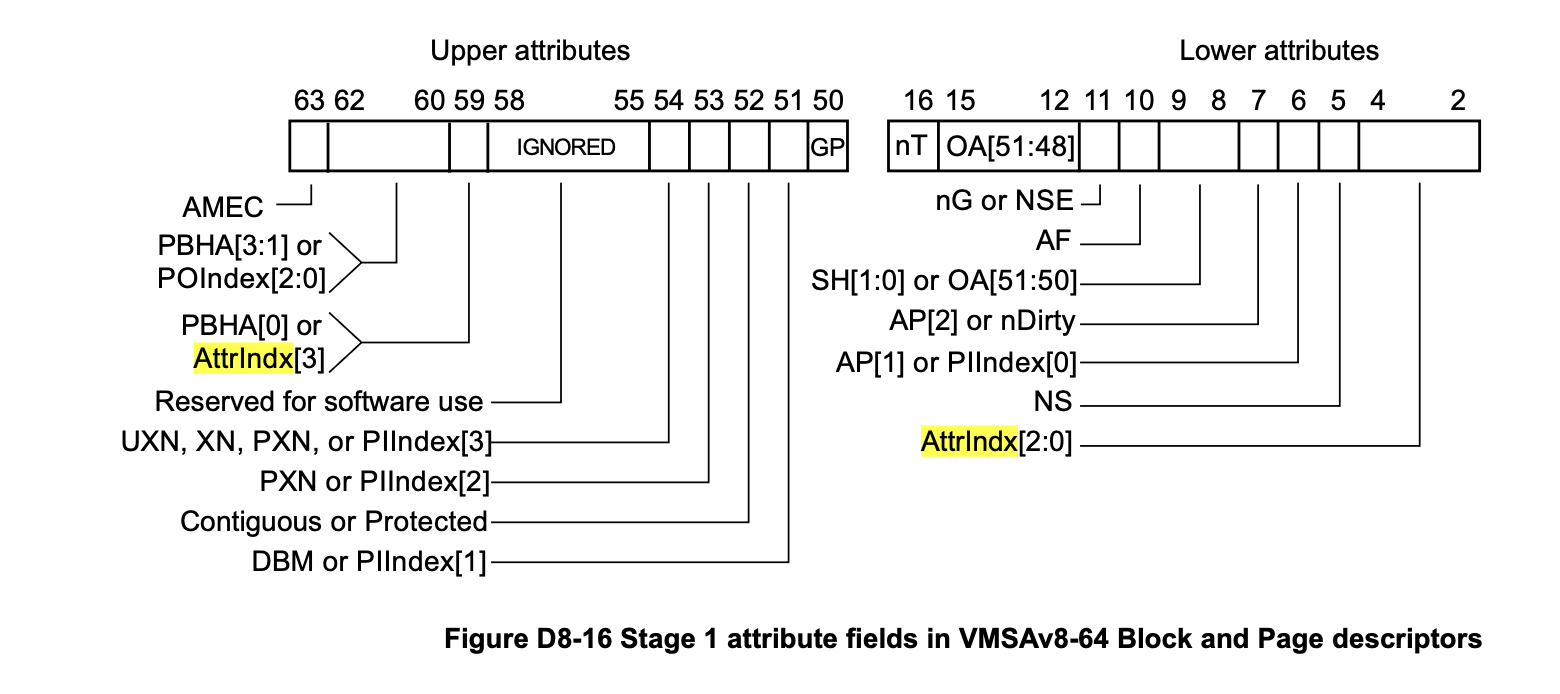
MAIR_EL1 (Memory Attribute Indirection Register, EL1) is a 64-bit register that defines the memory attribute encodings corresponding to the possible values of AttrIndx[] in the page table. It contains up to 8 attribute fields, each describing properties such as memory type, access behavior, and cacheability.

To analyze the root cause of the vulnerability, we need to understand the memory policy “Normal memory, Non-cacheable”. Details of this policy can be found in Section B2.10.1.3: Cacheability attributes for Normal memory of the ARM Architecture Reference Manual.
In general, if a memory location is marked as non-cacheable, writes to that location are visible to all observers accessing the memory system outside the corresponding cache level, without the need for explicit cache maintenance.
For example, when the CPU writes data to a non-cacheable address, the data is immediately written to main memory (RAM). Similarly, when reading from this address, the data is expected to be fetched directly from RAM, rather than through any cache.
3. Root Cause Analysis
Because the DMA mechanism accesses main memory directly, the kernel is responsible for flushing the CPU cache to main memory before installing the PTEs into the GPU’s MMU table.
Let’s go back and take a look at how dma_map_page(), which is called in kbase_jd_user_buf_map(), handles DMA mapping!
dma_map_page() internally calls dma_direct_map_page(). This function first translates the physical address of the page object into a DMA address [1], which the device uses to access main memory. It then checks whether the device is DMA-coherent, meaning that its DMA operations are automatically kept in sync with the CPU caches and main memory.
If the device is not coherent [2], the kernel must flush caches to ensure data consistency before the device accesses the memory. This is why arch_sync_dma_for_device() is called [3].
#define dma_map_page(d, p, o, s, r) dma_map_page_attrs(d, p, o, s, r, 0) // <--------------
dma_addr_t dma_map_page_attrs(struct device *dev, struct page *page,
size_t offset, size_t size, enum dma_data_direction dir,
unsigned long attrs)
{
// [...]
dma_addr_t addr;
// [...]
addr = dma_direct_map_page(dev, page, offset, size, dir, attrs); // <--------------
// [...]
return addr;
}
static inline dma_addr_t dma_direct_map_page(struct device *dev,
struct page *page, unsigned long offset, size_t size,
enum dma_data_direction dir, unsigned long attrs)
{
phys_addr_t phys = page_to_phys(page) + offset;
dma_addr_t dma_addr = phys_to_dma(dev, phys); // [1]
// [...]
if (!dev_is_dma_coherent(dev) && !(attrs & DMA_ATTR_SKIP_CPU_SYNC)) // [2]
arch_sync_dma_for_device(phys, size, dir); // [3]
return dma_addr;
}
For ARM64, the arch_sync_dma_for_device() calls dcache_clean_poc() with a specified memory region [4].
void arch_sync_dma_for_device(phys_addr_t paddr, size_t size,
enum dma_data_direction dir)
{
unsigned long start = (unsigned long)phys_to_virt(paddr);
dcache_clean_poc(start, start + size); // [4]
}
The dcache_clean_poc() function flushes the cache using the cvac instruction, which cleans a data or unified cache line by virtual address to the PoC.
SYM_FUNC_START(__pi_dcache_clean_poc)
dcache_by_line_op cvac, sy, x0, x1, x2, x3
ret
SYM_FUNC_END(__pi_dcache_clean_poc)
SYM_FUNC_ALIAS(dcache_clean_poc, __pi_dcache_clean_poc)
The term PoC stands for “Point of Coherency”, which refers to the point in the memory system where all observers — such as CPUs and DMA devices — see the same data, regardless of whether it comes from the cache or main memory.
However, as the original report describes:
However, when a user buffer is imported that does not begin/end at page boundaries, Mali still installs PTEs on the CPU and GPU that map the entire page, but only calls dma_map_page() on the user-specified range.
The incomplete cache flush may potentially expose stale memory contents from the GPU side, and possibly even from the CPU.
Because dma_map_page() is not guaranteed to flush the entire page, any memory range outside the specified mapping may still contain stale data in the main memory. You might assume that when a page is faulted in, the kernel will zero out the entire page for us — so there’s no need to worry about it. But, that zeroed data may still reside in the CPU cache and has not been flushed to main memory!
Later, when a page fault is triggered on a mapped GPU virtual address, the fault handler kbase_cpu_vm_fault() is invoked to handle it. Internally, it installs the PTEs for the mapped pages by calling vmf_insert_pfn_prot() [5]. Note that the PTEs for the memory mapping are the same as those used for the anonymous pages requested from the kernel, but with a different vma->vm_page_prot.
static vm_fault_t kbase_cpu_vm_fault(struct vm_fault *vmf)
{
struct vm_area_struct *vma = vmf->vma;
// [...]
nents = map->alloc->nents;
pages = map->alloc->pages;
// [...]
while (i < nents && (addr < vma->vm_end >> PAGE_SHIFT)) {
ret = mgm_dev->ops.mgm_vmf_insert_pfn_prot(mgm_dev, // [5] - a wrapper of vmf_insert_pfn_prot()
map->alloc->group_id, vma, addr << PAGE_SHIFT,
PFN_DOWN(as_phys_addr_t(pages[i])), vma->vm_page_prot);
// [...]
i++; addr++;
}
// [...]
}
vma->vm_page_prot, known as the page protection flags, provides additional attributes for a PTE. As seen in the insert_pfn() function, it calls pfn_t_pte(), which combines the prot and the physical address (pfn) to create a PTE [6].
vm_fault_t vmf_insert_pfn_prot(struct vm_area_struct *vma, unsigned long addr,
unsigned long pfn, pgprot_t pgprot)
{
// [...]
return insert_pfn(vma, addr, __pfn_to_pfn_t(pfn, PFN_DEV), pgprot, // <--------------
false);
}
static vm_fault_t insert_pfn(struct vm_area_struct *vma, unsigned long addr,
pfn_t pfn, pgprot_t prot, bool mkwrite)
{
// [...]
entry = pte_mkspecial(pfn_t_pte(pfn, prot));
// [...]
set_pte_at(mm, addr, pte, entry); // [6]
// [...]
}
static inline pte_t pte_mkspecial(pte_t pte)
{
return set_pte_bit(pte, __pgprot(PTE_SPECIAL));
}
We previously ignored how kbase_cpu_mmap() configures vma->vm_page_prot, as it was not essential to understanding the fundamentals. However, this detail becomes important for this vulnerability.
If the region does not have the KBASE_REG_CPU_CACHED flag set [7], the PTE will be set to use write-combine memory attributes [8].
static int kbase_cpu_mmap(struct kbase_context *kctx,
struct kbase_va_region *reg,
struct vm_area_struct *vma,
/*...*/)
{
if (!(reg->flags & KBASE_REG_CPU_CACHED) && // [7]
(reg->flags & (KBASE_REG_CPU_WR|KBASE_REG_CPU_RD))) {
// [...]
vma->vm_page_prot = pgprot_writecombine(vma->vm_page_prot); // [8]
}
// [...]
}
On ARM64, write-combine is implemented by setting PTE_ATTRINDX(MT_NORMAL_NC), which designates normal, non-cacheable memory. As a result, both reads and writes to this memory region access main memory directly.
#define pgprot_writecombine(prot) \
__pgprot_modify(prot, PTE_ATTRINDX_MASK, PTE_ATTRINDX(MT_NORMAL_NC) | PTE_PXN | PTE_UXN)
In a nutshell, dma_map_page() only flushes the specified region of the target anonymous page. However, the entire page can later be mapped via a GPU virtual address that treats it as an imported buffer with non-cacheable attributes, which results in stale data being read from the anonymous page.
(page table)
-----------------------------
| PTE (by kbase_cpu_mmap()) | ------
----------------------------- |
| PTE (by fault-in) | |
----------------------------- |
| |
v |
--------------- | directly access main memory
| (cache) | | due to non-cachable attribute
| 0000000000000 | |
--------------- |
(zeroed out when allocating a page) |
|
-------------------------- |
| (main memory) | |
| deadbeefdeadbeefdeadbeef | <--------
--------------------------
4. Summary
I’ve always focused on traditional bug types like UAF and race conditions, and often skipped over hardware-related ones. This vulnerability reminded me not to limit my scope — even if such bugs are harder to find or reason about. Stay curious and keep learning!