Linux Kernel Memory Allocation
1. 簡介
Linux kernel 的記憶體分配機制稱作 slab allocation,根據實作細節的不同又能分成 SLUB 與 SLAB。一般常見 PC 安裝的 Linux Distribution 作業系統如 Ubuntu 或 Debian 都是使用 SLUB。
接下來會透過分析版本 6.6.31 原始碼來了解 SLUB 的是如何實作,而擷取出來的原始碼會省略掉不重要的部分,並不代表完整的結構或 function。
2. 結構
2.1. Overview
以宏觀來看,SLUB 可以拆成三個部分,分別為:cache、slab 以及 object。
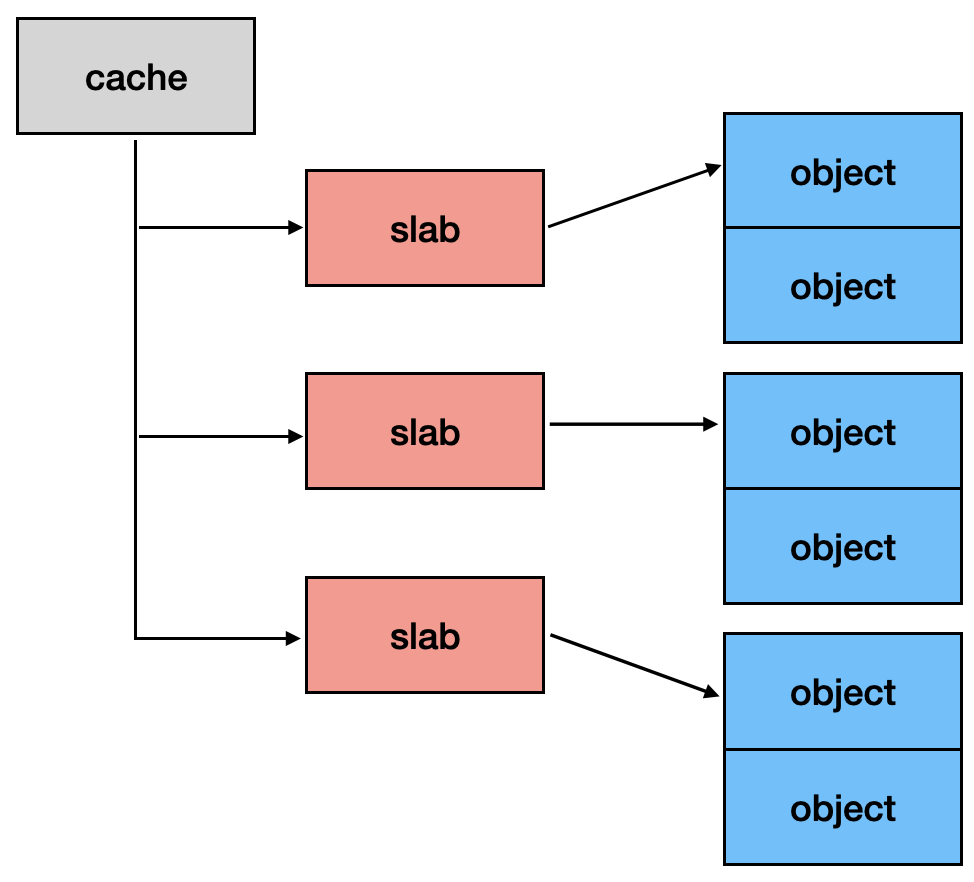
回傳給外部使用的記憶體區塊稱作 object。這些 object 都是從一塊連續的記憶體區塊切割出來的,稱作 slab。如果當前 slab 不夠用,kernel 還會再分配新的 slab,而這些 slab 都是統一由 cache 來管理。
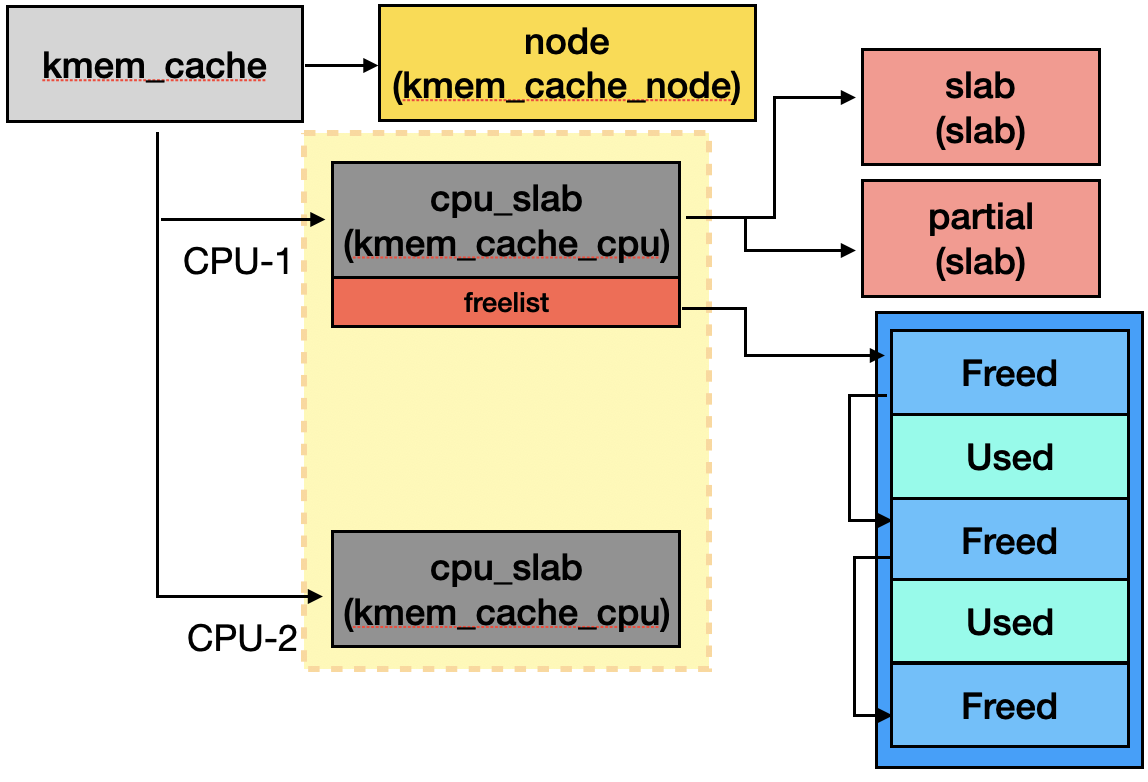
Cache 對應到 Linux kernel 的結構為 struct kmem_cache:
// include/linux/slub_def.h
struct kmem_cache {
#ifndef CONFIG_SLUB_TINY
struct kmem_cache_cpu __percpu *cpu_slab;
#endif
// [...]
struct kmem_cache_node *node[MAX_NUMNODES];
};
struct kmem_cache 在每個 CPU 都會維護一份 struct kmem_cache_cpu,會紀錄正在使用中與使用完的 slab,此外 struct kmem_cache 也會用 struct kmem_cache_node 紀錄 node level 的 slab 使用狀況。
// include/linux/slub_def.h
struct kmem_cache_cpu {
// [...]
union {
// {...
void *freelist;
// ...}
};
struct slab *slab; /* The slab from which we are allocating */
#ifdef CONFIG_SLUB_CPU_PARTIAL
struct slab *partial; /* Partially allocated frozen slabs */
#endif
// [...]
};
struct kmem_cache_cpu 的結構成員 slab 會指向該 CPU 正在使用的 struct slab,而 partial 則是指向先前使用到的 struct slab。
Slab 對應到結構 struct slab,其成員 freelist 指向第一塊 freed object,slab_cache 則是指向管理他的 struct kmem_cache。
// mm/slab.h
struct slab {
// [...]
struct kmem_cache *slab_cache;
union {
// {...
void *freelist;
// ...}
};
// [...]
};
值得注意的是,正在使用的 struct slab 其 freelist 會直接傳給 struct kmem_cache_cpu 的 freelist 來使用,因此會是 NULL。
Freed object 使用單向 linked list 串起來,而 kernel 在存取 freed object 時會使用結構 freeptr_t,其成員 v 指向下一個 freed object。
// mm/slub.c
typedef struct { unsigned long v; } freeptr_t;
2.2. General cache
Kernel 初始化時會新增不同大小與類型的 general cache,作為預設記憶體分配使用的 cache。這些 cache 會存於全域變數 kmalloc_caches。
// mm/slab_common.c
struct kmem_cache *
kmalloc_caches[NR_KMALLOC_TYPES][KMALLOC_SHIFT_HIGH + 1];
其中 NR_KMALLOC_TYPES 由 object 的類型決定。預設 kernel config 編譯出來會有 3 種類型,分別為 KMALLOC_NORMAL、KMALLOC_RECLAIM 以及 KMALLOC_DMA。
// include/linux/slab.h
enum kmalloc_cache_type {
KMALLOC_NORMAL,
KMALLOC_CGROUP = 0,
KMALLOC_RANDOM_START = 0,
KMALLOC_RANDOM_END = 0,
KMALLOC_RECLAIM,
KMALLOC_DMA,
NR_KMALLOC_TYPES
}
如果 object 類型為 KMALLOC_RECLAIM,kernel 會在記憶體不足時回收 (reclaim) 這些 object。若 object 類型為 KMALLOC_DMA,代表可以被 DMA-capable 的裝置存取。
相同類型的 object 可能會有不同的大小,考慮到存取速度與實作複雜度,kernel 將大小拆成 KMALLOC_SHIFT_HIGH + 1 種,分別由不同的 cache 來管理。預設 KMALLOC_SHIFT_HIGH + 1 的值會是 14,分別對應到的大小可以參考 function __kmalloc_index()。
// include/linux/slab.h
static __always_inline unsigned int __kmalloc_index(size_t size,
bool size_is_constant)
{
if (!size)
return 0;
// [...]
if (KMALLOC_MIN_SIZE <= 32 && size > 64 && size <= 96)
return 1;
if (KMALLOC_MIN_SIZE <= 64 && size > 128 && size <= 192)
return 2;
if (size <= 8) return 3;
if (size <= 16) return 4;
if (size <= 32) return 5;
if (size <= 64) return 6;
if (size <= 128) return 7;
if (size <= 256) return 8;
if (size <= 512) return 9;
if (size <= 1024) return 10;
if (size <= 2 * 1024) return 11;
if (size <= 4 * 1024) return 12;
if (size <= 8 * 1024) return 13;
// [...]
}
除了前兩個 cache 大小外都是 2 ^ n,且最高到 2 ^ 13,也就是 0x2000。同一個 cache 仍可能包含不同大小的 object,可以參考下列公式:
| Index | Size |
|---|---|
| 0 | 0 |
| 1 | 65~96 |
| 2 | 129~192 |
| n | 2 ^ (n-1) + 1 ~ 2 ^ n |
這些 cache 會在 init function create_kmalloc_caches() 被建立與初始化。
void __init create_kmalloc_caches(slab_flags_t flags)
{
int i;
enum kmalloc_cache_type type;
for (type = KMALLOC_NORMAL; type < NR_KMALLOC_TYPES; type++) {
for (i = KMALLOC_SHIFT_LOW; i <= KMALLOC_SHIFT_HIGH; i++) {
if (!kmalloc_caches[type][i])
new_kmalloc_cache(i, type, flags);
if (KMALLOC_MIN_SIZE <= 32 && i == 6 &&
!kmalloc_caches[type][1])
new_kmalloc_cache(1, type, flags);
if (KMALLOC_MIN_SIZE <= 64 && i == 7 &&
!kmalloc_caches[type][2])
new_kmalloc_cache(2, type, flags);
}
}
// [...]
}
2.3. Specified cache
假設某相同結構的 object 會一直不斷使用與釋放,可能會因為與其他 object 一起使用同個 slab 而有效能上的影響,因此 kernel 提供了 specified cache,讓開發人員能為頻繁使用到的結構建一個專屬的 cache。
一般情況下直接呼叫最上層的 function kmem_cache_create() 就能取得初始化後的 struct kmem_cache,像是 kernel 會呼叫 kmem_cache_create("cred_jar"),分配結構 struct cred 專用的 struct kmem_cache。
// kernel/cred.c
void __init cred_init(void)
{
cred_jar = kmem_cache_create("cred_jar", sizeof(struct cred), 0,
SLAB_HWCACHE_ALIGN|SLAB_PANIC|SLAB_ACCOUNT, NULL);
}
kmem_cache_create() 底層會呼叫 create_cache() 來分配 [1] 與初始化 [2]。
// mm/slab_common.c
static struct kmem_cache *create_cache(const char *name,
unsigned int object_size, unsigned int align,
slab_flags_t flags, unsigned int useroffset,
unsigned int usersize, void (*ctor)(void *),
struct kmem_cache *root_cache)
{
struct kmem_cache *s;
int err;
// [...]
s = kmem_cache_zalloc(kmem_cache, GFP_KERNEL); // [1]
s->name = name;
s->size = s->object_size = object_size;
s->align = align;
s->ctor = ctor;
err = __kmem_cache_create(s, flags); // [2]
s->refcount = 1;
list_add(&s->list, &slab_caches);
return s;
}
3. 分配記憶體
在開始看程式碼的處理前,可以先參考論文 PSPRAY: Timing Side-Channel based Linux Kernel Heap Exploitation Technique 裡面的一張圖,圖中清楚呈現了記憶體分配的整個過程。
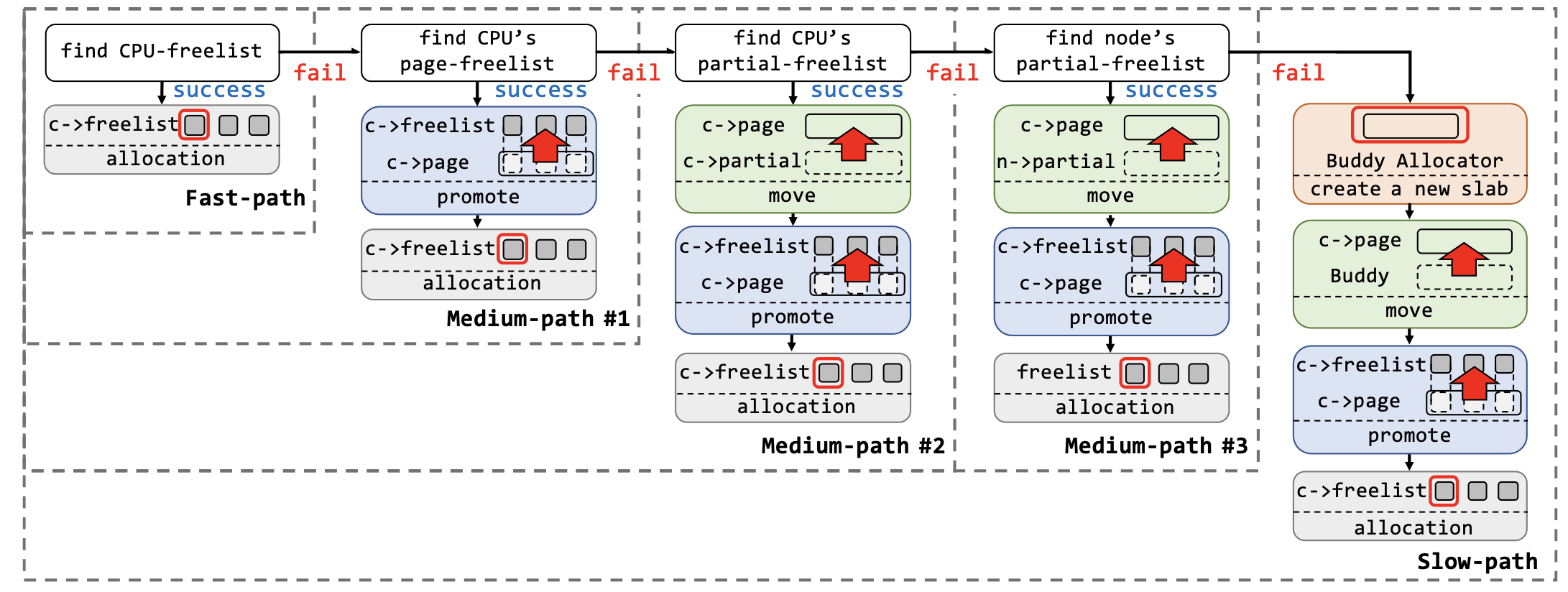
Kernel 主要提供兩個 function 來分配記憶體,分別為:
kmalloc(memory_size, flags)- 使用 general cachekmem_cache_alloc(kmem_cache)- 使用 specified cache
3.1. kmalloc
kmalloc() 為 __kmalloc() 的 wrapper function,底層會走到 __do_kmalloc_node()。該 function 會先判斷 size 是否小於 KMALLOC_MAX_CACHE_SIZE (0x2000),如果是的話就先取出對應類型與大小的 general cache [2],並從該 cache 分配一塊記憶體。
// mm/slab_common.c
void *__do_kmalloc_node(size_t size, gfp_t flags, int node, unsigned long caller)
{
struct kmem_cache *s;
void *ret;
if (unlikely(size > KMALLOC_MAX_CACHE_SIZE)) { // [1]
// [...]
return ret;
}
s = kmalloc_slab(size, flags, caller); // [2]
ret = __kmem_cache_alloc_node(s, flags, node, size, caller); // [3]
// [...]
return ret;
}
使用哪個 type 的 cache 取決於傳入的 flags:
KMALLOC_DMA- flag 中包含__GFP_DMA,並且 kernel 需啟用CONFIG_ZONE_DMAKMALLOC_RECLAIM- flag 中包含__GFP_RECLAIMABLEKMALLOC_NORMAL- 其他
而 __kmem_cache_alloc_node() 則是 slab_alloc_node() 的 wrapper function。
// mm/slub.c
void *__kmem_cache_alloc_node(struct kmem_cache *s, gfp_t gfpflags,
int node, size_t orig_size,
unsigned long caller)
{
return slab_alloc_node(s, NULL, gfpflags, node,
caller, orig_size);
}
由於另一種分配方式 kmem_cache_alloc() 最後也是走 slab_alloc_node(),在此就不多做介紹。
3.2. kmem_cache_alloc
kmem_cache_alloc() 指定了使用哪一個 cache 來做分配,底層會呼叫到 __slab_alloc_node()。該 function 會先檢查當前 CPU 是否有 freed object 可以用 [1],有的話就直接走 fast path,取出 freed object 後更新 freelist [2]。如果沒有 freed object 可以使用,就會走 slow path,呼叫 __slab_alloc() [3]。
// mm/slub.c
static __always_inline void *__slab_alloc_node(struct kmem_cache *s,
gfp_t gfpflags, int node, unsigned long addr, size_t orig_size)
{
struct kmem_cache_cpu *c;
struct slab *slab;
unsigned long tid;
void *object;
// [...]
c = raw_cpu_ptr(s->cpu_slab);
tid = READ_ONCE(c->tid);
object = c->freelist;
slab = c->slab;
if (!USE_LOCKLESS_FAST_PATH() ||
unlikely(!object || !slab || !node_match(slab, node))) { // [1]
object = __slab_alloc(s, gfpflags, node, addr, c, orig_size); // [3]
} else {
void *next_object = get_freepointer_safe(s, object);
if (unlikely(!__update_cpu_freelist_fast(s, object, next_object, tid))) { // [2]
// [...]
goto redo;
}
prefetch_freepointer(s, next_object);
}
return object;
}
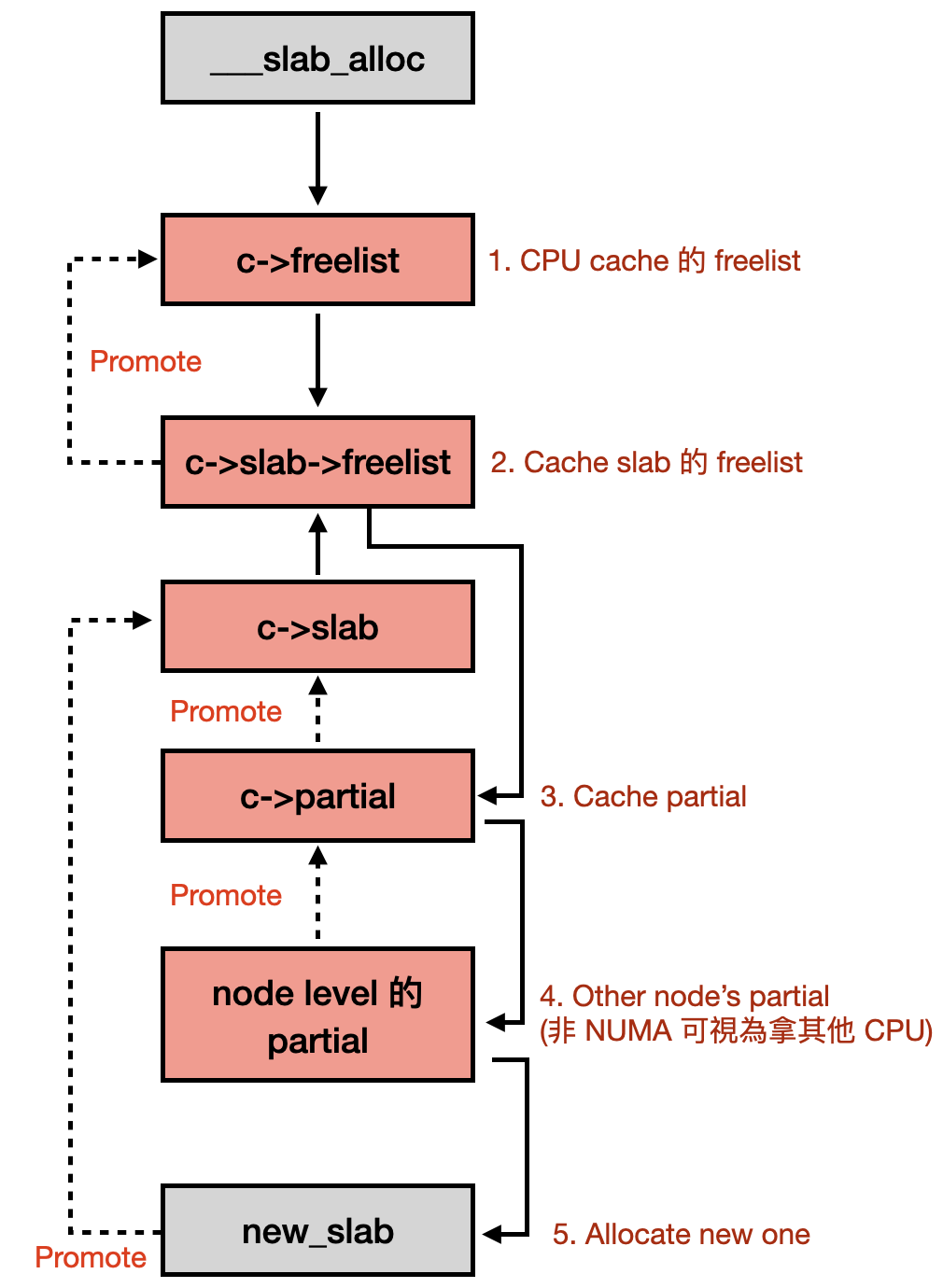
__slab_alloc() 為 ___slab_alloc() 的 wrapper function。___slab_alloc() 會先檢查 CPU freelist [4],再檢查 c->slab->freelist [5]。當 c->slab->freelist 都為空,代表目前 cache 正在使用的 slab 已經用完了,因此需要分配一個新的 slab。
// mm/slub.c
static void *___slab_alloc(struct kmem_cache *s, gfp_t gfpflags, int node,
unsigned long addr, struct kmem_cache_cpu *c, unsigned int orig_size)
{
void *freelist;
struct slab *slab;
unsigned long flags;
struct partial_context pc;
slab = READ_ONCE(c->slab);
// [...]
freelist = c->freelist; // [4]
if (freelist)
goto load_freelist;
freelist = get_freelist(s, slab); // [5]
if (!freelist) {
c->slab = NULL;
c->tid = next_tid(c->tid);
// [...]
goto new_slab;
}
// [...]
}
但為了避免不必要的分配所造成的 overhead,kernel 還是會嘗試使用現有的 slab,因此他會先看 partial slab list 裡面有沒有可以使用的 slab。Partial slab list 包含了所有 “曾經使用完但現在有 freed object” 的 slab [6],若在 partial slab list 當中,就代表 slab 還有 freed object 可以使用。
還是沒有的話,kernel 下一步就會嘗試去拿 node level 的 partial slab list [7]。非 NUMA 架構的話所有 CPU 都在同一個 node 上,因此所有 CPU 都會使用同一個 node partial slab list。再沒有的話,最後就會呼叫 new_slab() 分配一個新的 struct slab [8],並更新到 struct kmem_cache_cpu [9]。
{
// [...]
new_slab:
if (slub_percpu_partial(c)) {
// [...]
slab = c->slab = slub_percpu_partial(c); // [6]
slub_set_percpu_partial(c, slab);
local_unlock_irqrestore(&s->cpu_slab->lock, flags);
stat(s, CPU_PARTIAL_ALLOC);
goto redo;
}
new_objects:
pc.flags = gfpflags;
pc.slab = &slab;
pc.orig_size = orig_size;
freelist = get_partial(s, node, &pc); // [7]
if (freelist)
goto check_new_slab;
slub_put_cpu_ptr(s->cpu_slab);
slab = new_slab(s, gfpflags, node); // [8]
// [...]
freelist = slab->freelist;
slab->freelist = NULL;
slab->inuse = slab->objects;
slab->frozen = 1;
// [...]
retry_load_slab:
c->slab = slab; // [9]
goto load_freelist;
}
雖然 struct slab 剛被分配出來時 slab->freelist 會指向 freed object,但為了加快存取速度,會直接傳給 CPU cache 的 freelist 做使用 [10]。
{
load_freelist:
// [...]
c->freelist = get_freepointer(s, freelist); // [10]
c->tid = next_tid(c->tid);
return freelist;
}
那 new_slab() 是如何分配 struct slab 的? new_slab() 最後會走到 allocate_slab(),該 function 會呼叫 alloc_slab_page() 分配 [1] 並初始化 slab:
// mm/slub.c
static struct slab *allocate_slab(struct kmem_cache *s, gfp_t flags, int node)
{
struct slab *slab;
struct kmem_cache_order_objects oo = s->oo;
gfp_t alloc_gfp;
void *start, *p, *next;
int idx;
bool shuffle;
// [...]
slab = alloc_slab_page(alloc_gfp, node, oo); // [1]
slab->objects = oo_objects(oo);
slab->inuse = 0;
slab->frozen = 0;
slab->slab_cache = s;
// [...]
// [... setup freelist ...]
return slab;
}
alloc_slab_page() 首先根據 cache 紀錄的 object 大小與預期數量來決定要分配的 page order,並向 buddy system 請求分配 struct page [2]。
// mm/slub.c
static inline struct slab *alloc_slab_page(gfp_t flags, int node,
struct kmem_cache_order_objects oo)
{
struct folio *folio;
struct slab *slab;
unsigned int order = oo_order(oo);
// [...]
folio = (struct folio *)alloc_pages(flags, order); // [2]
slab = folio_slab(folio);
__folio_set_slab(folio);
// [...]
return slab;
}
常見 cache 的每個 slab 內 object 數量的對照表:
| Name | Object Count | Per Slab Size |
|---|---|---|
| kmalloc-8 | 512 | 0x1000 |
| kmalloc-16 | 256 | 0x1000 |
| kmalloc-32 | 128 | 0x1000 |
| kmalloc-64 | 64 | 0x1000 |
| kmalloc-96 | 42 | 0x1000 |
| kmalloc-128 | 32 | 0x1000 |
| kmalloc-192 | 21 | 0x1000 |
| kmalloc-256 | 16 | 0x1000 |
| kmalloc-512 | 8 | 0x1000 |
| kmalloc-1k | 8 | 0x2000 |
| kmalloc-2k | 8 | 0x4000 |
| kmalloc-4k | 8 | 0x8000 |
| kmalloc-8k | 4 | 0x8000 |
然而 alloc_slab_page() 的操作乍看之下會覺得怪怪的,alloc_pages() 回傳的是 struct page*,但他會先被 cast 成 struct folio* 使用,再以 struct slab* 回傳給 caller function。
struct folio 將多個 struct page 視為一個 group,又稱作 page group,而 struct slab 則是整個 page group 的 head,也就是第一個 struct page。不是 head 的 page 會使用成員 compound_head 紀錄 head 的位址,並且該位址會 + 1,用來判斷當前 struct page 是否為 head。
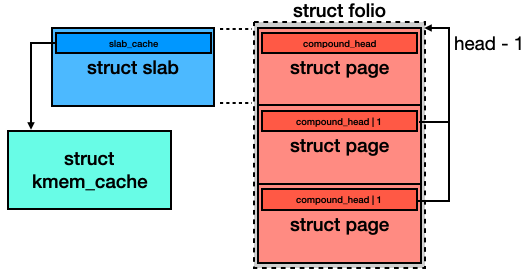
參考 function _compound_head(page) 的處理方式就會很清楚。
// include/linux/page-flags.h
static inline unsigned long _compound_head(const struct page *page)
{
unsigned long head = READ_ONCE(page->compound_head);
if (unlikely(head & 1))
return head - 1;
return page;
}
若將分配的過程畫成簡單的流程圖,大概會長得像:
3.3. 觀察狀態
有幾種方式可以得知當前 SLUB 的狀態:
- OS - 透過 proc pseudo filesystem
cat /proc/slabinfo- 輸出會長得像
# name <active_objs> <num_objs> <objsize> ... [...] kmalloc-512 2012 6128 512 ... kmalloc-256 3913 5152 256 ... kmalloc-128 32959 41920 128 ... [...]
- 輸出會長得像
-
Debugger - 透過
pwndbg的 command-
slab list- 印出所有 cache 的資訊,像是一個 slab 會有多少 object 等等- 範例輸出
Name # Objects Size Obj Size # inuse order ----------------------- ----------- ------ ---------- --------- ------- 9p-fcall-cache 1 131096 131096 131096 6 p9_req_t 25 160 152 152 0 ip6-frags 22 184 184 184 0 [...]
- 範例輸出
-
slab info <cache_name>- 印出對應名字的struct kmem_cache資訊- 範例輸出
pwndbg> slab info kmalloc-8 Slab Cache @ 0xffff888002841200 Name: kmalloc-8 Flags: (none) Offset: 0 Size: 8 Align: 8 Object Size: 8 kmem_cache_cpu @ 0xffff88800f224c70 [CPU 0]: Freelist: 0xffff888002a59f88 Active Slab: - Slab @ 0xffff888002a59000 [0xffffea00000a9640]: In-Use: 510/512 Frozen: 1 Freelist: 0x0 Partial Slabs: (none) kmem_cache_node @ 0xffff888002840080 [NUMA node 0]: Partial Slabs: (none)
- 範例輸出
-
slab contains <addr_1> <addr_2> ...- 找出 address 所對應到的struct kmem_cache- 範例輸出
pwndbg> slab contains 0xffff888002a59f88 0xffff888002a59f88 @ kmalloc-8
- 範例輸出
-
-
sysfs - 可以看 cache 的一些設定
/sys/kernel/slab/<cache_name>/cpu_partial- cachecpu_partial的值/sys/kernel/slab/<cache_name>/objs_per_slab- cachecpu_partial_slabs的值/sys/kernel/slab/<cache_name>/min_partial- cachemin_partial的值- …
此外先前介紹結構 struct kmem_cache 時只有提到成員 cpu_cache,該結構還有其他重要的成員:
| Name | Feature |
|---|---|
| size | object size with metadata |
| object_size | object size without metadata |
| oo | order object,紀錄了 per slab 大小與其他資訊 |
| cpu_partial | CPU (kmem_cache_cpu) 中所有 partial slab 最多有幾個 object |
| cpu_partial_slabs | CPU (kmem_cache_cpu) 最多能有幾個 partial slab |
| min_partial | node (kmem_cache_node) 最多能有多少個 partial slab |
4. 釋放記憶體
與分配時的行為相似,主要由兩個 function 來處理:
kfree(object)kmem_cache_free(kmem_cache, object)- object 被釋放到 specified cache
4.1. kfree
該 function 會先取得 object 所對應到的 struct slab [1] 與 struct kmem_cache,之後在呼叫 __kmem_cache_free() 做釋放。
// mm/slab_common.c
void kfree(const void *object)
{
struct folio *folio;
struct slab *slab;
struct kmem_cache *s;
folio = virt_to_folio(object); // [1]
// [...]
slab = folio_slab(folio);
s = slab->slab_cache;
__kmem_cache_free(s, (void *)object, _RET_IP_);
}
virt_to_folio() 做的事情很單純,取得 object 所對應到的 struct page。page_folio() 則是會回傳 struct page 所對應的 compound head。
// include/linux/mm.h
static inline struct folio *virt_to_folio(const void *x)
{
struct page *page = virt_to_page(x);
return page_folio(page);
}
virt_to_page(object) 回傳 VA 所對應到的 struct page*。由於 source code 的處理會 depend on 指令集與一些 define value,操作流程不是這麼直觀,這邊用一段簡單的 C code 會比較好理解:
#define __START_KERNEL_map (0xffffffff80000000)
extern unsigned long phys_base;
extern unsigned long page_offset_base;
extern unsigned long vmemmap_base;
struct page *virt_to_page(unsigned long object) {
unsigned long pfn;
if (object > __START_KERNEL_map)
pfn = (object - __START_KERNEL_map + phys_base) >> 12;
else
pfn = (object - page_offset_base) >> 12;
// sizeof(struct page) == 0x40
return vmemmap_base + sizeof(struct page) * pfn;
}
__kmem_cache_free() 會呼叫到 slab_free(),同時 slab_free() 也會被 kmem_cache_free() 呼叫到,因此留到後面在介紹。
4.2. kmem_cache_free
結構 struct slab 除了有指向第一個 freed object 的成員 freelist 外,也包含了一些紀錄 slab 使用狀況的成員。inuse 紀錄 slab 中正在使用的 object 個數,objects 紀錄能夠使用的 object 個數,frozen 代表 slab 是否能再分配新的 object。
// mm/slab.h
struct slab {
// [...]
union {
struct {
void *freelist; /* first free object */
union {
unsigned long counters;
struct {
unsigned inuse:16;
unsigned objects:15;
unsigned frozen:1;
};
};
};
// [...]
};
};
kmem_cache_free() 會呼叫 slab_free(),而 slab_free() 是 do_slab_free() 的 wrapper function。當要被釋放的 object 所對應到的 slab 與當前 cache 正在使用的 slab 相同時,直接走 fast path [1],把 object 放到 freelist 即可。反之走 slow path,呼叫 __slab_free() 來處理 [2]:
// mm/slub.c
static __always_inline void do_slab_free(struct kmem_cache *s,
struct slab *slab, void *head, void *tail,
int cnt, unsigned long addr)
{
void *tail_obj = tail ? : head;
struct kmem_cache_cpu *c;
unsigned long tid;
void **freelist;
// [...]
c = raw_cpu_ptr(s->cpu_slab);
tid = READ_ONCE(c->tid);
// [...]
if (unlikely(slab != c->slab)) {
__slab_free(s, slab, head, tail_obj, cnt, addr); // [2]
return;
}
if (USE_LOCKLESS_FAST_PATH()) {
freelist = READ_ONCE(c->freelist); // [1]
set_freepointer(s, tail_obj, freelist);
if (unlikely(!__update_cpu_freelist_fast(s, freelist, head, tid))) {
note_cmpxchg_failure("slab_free", s, tid);
goto redo;
}
}
// [...]
stat(s, FREE_FASTPATH);
}
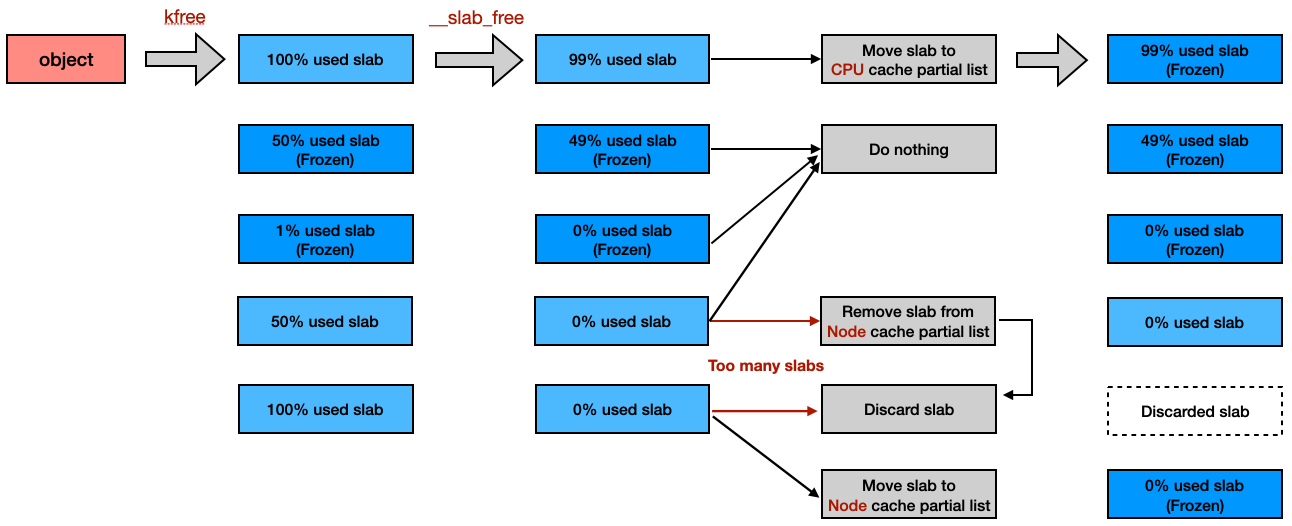
__slab_free() 會 enqueue object 所對應到的 slab 的 freelist [3],並更新正在使用的數量 inuse [4]。過程中如果發現 slab 沒有任何 freed object,就註記 slab 為 frozen [5]。如果更新後發現 new.inuse == 0,代表整個 slab 都是 freed object,則會取得 node cache [6] 並在後續做使用:
// mm/slub.c
static void __slab_free(struct kmem_cache *s, struct slab *slab,
void *head, void *tail, int cnt,
unsigned long addr)
{
void *prior;
int was_frozen;
struct slab new;
unsigned long counters;
struct kmem_cache_node *n = NULL;
unsigned long flags;
// [...]
do {
prior = slab->freelist;
counters = slab->counters;
set_freepointer(s, tail, prior); // [3]
new.counters = counters;
was_frozen = new.frozen;
new.inuse -= cnt; // [4]
if ((!new.inuse || !prior) && !was_frozen) {
if (!prior) {
// [...]
new.frozen = 1; // [5]
} else {
n = get_node(s, slab_nid(slab)); // [6]
// [...]
}
}
} while (!slab_update_freelist(s, slab,
prior, counters,
head, new.counters,
"__slab_free")); // [3]
// [...]
}
當 slab 還有使用中的 object,就會進到這個 condition。若 slab 的狀態第一次變成 frozen,就會被放到 CPU partial slab list 當中 [7],否則直接 return。
{
// [...]
if (likely(!n)) {
if (likely(was_frozen)) {
// do nothing
} else if (new.frozen) { // [7]
put_cpu_partial(s, slab, 1);
}
return;
}
// [...]
}
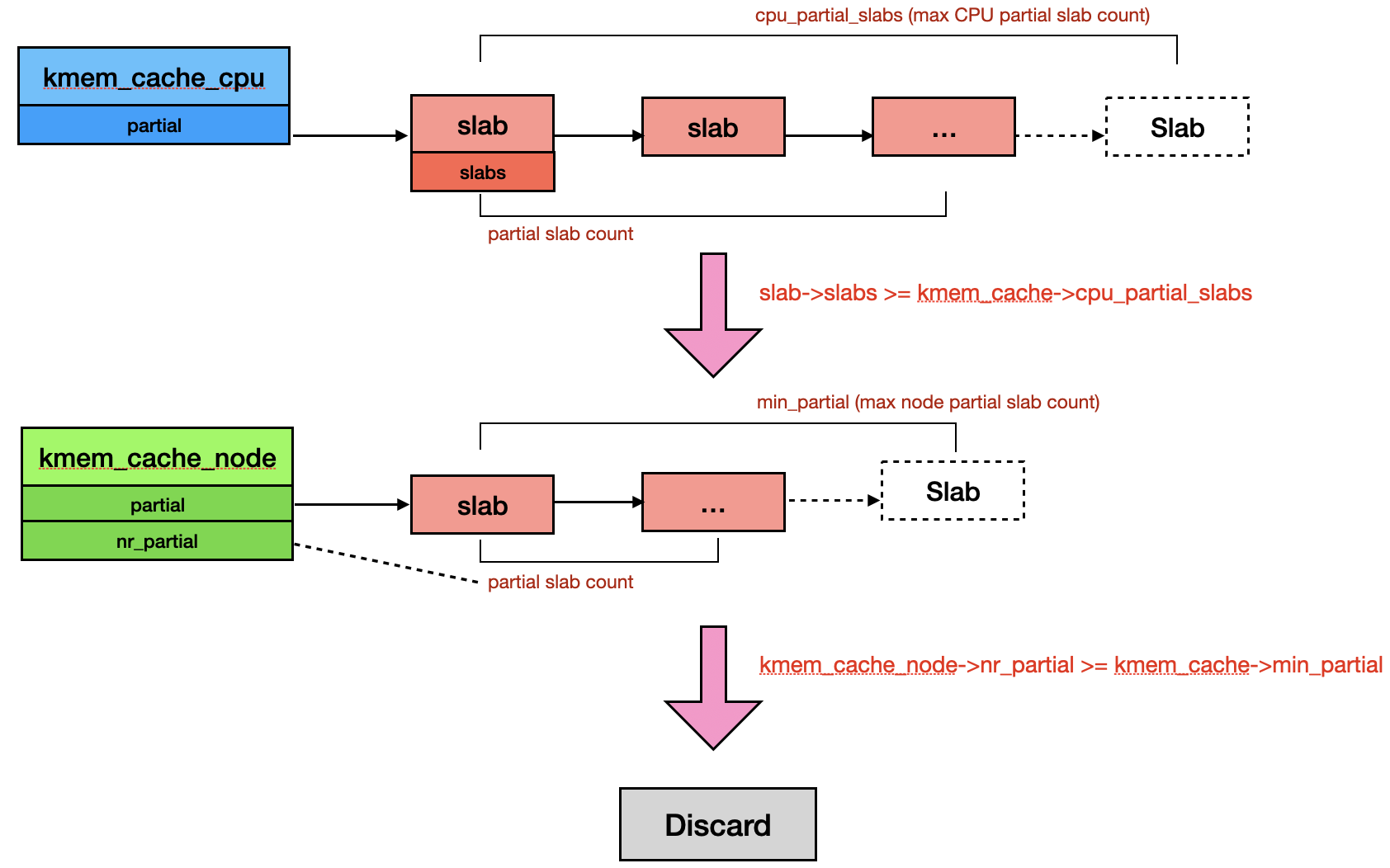
當 slab 都是 freed object 時,會走到下方的處理邏輯。如果發現 node cache 所紀錄的 partial slab 數量 (nr_partial) 超過最大上限 (min_partial),就會呼叫 discard_slab() 釋放該 slab [8]。如果 slab 數量還在範圍內,且不在 partial slab list [9],就會把 slab 放到 node partial slab list。
{
// [...]
if (unlikely(!new.inuse && n->nr_partial >= s->min_partial))
goto slab_empty;
if (unlikely(!prior)) { // [9]
add_partial(n, slab, DEACTIVATE_TO_TAIL); // [10]
}
// [...]
return;
slab_empty:
if (prior) {
remove_partial(n, slab); // [11]
}
// [...]
discard_slab(s, slab); // [8]
}
這邊有兩個要額外注意的地方:
__slab_free()透過prior來判斷該 slab 之前是否就已經在 partial slab list,並以此決定是否要新增至 partial slab list [10],或是從 partial slab list 移除 [11]- 不討論 full list 是因為 full list 只會在 kernel config
CONFIG_SLUB_DEBUG啟用的情況下使用
大致的釋放流程會長得像:
接下來我們看看放入 partial slab list 與 discard slab 的行為。放到 CPU partial slab list 是透過 put_cpu_partial(),該 function 先判斷在釋放前 CPU partial slab list 的 slab 數量 (oldslab->slabs) 是否超過上限 (s->cpu_partial_slabs) [1],如果沒有的話就更新數量,並 insert 到 slab linked list [2]。但若超過上限,就會 unlink 整個舊的 partial slab list,並丟給 __unfreeze_partials() 處理 [3]。
// mm/slub.c
static void put_cpu_partial(struct kmem_cache *s, struct slab *slab, int drain)
{
struct slab *oldslab;
struct slab *slab_to_unfreeze = NULL;
unsigned long flags;
int slabs = 0;
oldslab = this_cpu_read(s->cpu_slab->partial);
if (oldslab) {
if (drain && oldslab->slabs >= s->cpu_partial_slabs) { // [1]
slab_to_unfreeze = oldslab;
oldslab = NULL;
} else {
slabs = oldslab->slabs;
}
}
slabs++;
slab->slabs = slabs;
slab->next = oldslab; // [2]
this_cpu_write(s->cpu_slab->partial, slab);
if (slab_to_unfreeze) {
__unfreeze_partials(s, slab_to_unfreeze); // [3]
}
}
__unfreeze_partials() 在做的事情就是把存在於 CPU 的 partial slab promote 到 node。首先他會遍歷整個 partial slab list,把每個 slab 的 frozen bit 都更新成 0 (unfreeze) [4],之後檢查 slab 是否都是 freed object 以及 node slab 是否超過上限,如果是的話,就會把這些 slab 串起來,最後一個個 discard [5]。反之如果沒有,就直接放到 node 的 partial slab list [6]。
// mm/slub.c
static void __unfreeze_partials(struct kmem_cache *s, struct slab *partial_slab)
{
struct kmem_cache_node *n = NULL, *n2 = NULL;
struct slab *slab, *slab_to_discard = NULL;
unsigned long flags = 0;
while (partial_slab) {
struct slab new;
struct slab old;
slab = partial_slab;
partial_slab = slab->next;
// [...]
do {
old.freelist = slab->freelist;
old.counters = slab->counters;
new.counters = old.counters;
new.freelist = old.freelist;
new.frozen = 0; // [4]
} while (!__slab_update_freelist(s, slab,
old.freelist, old.counters,
new.freelist, new.counters,
"unfreezing slab"));
if (unlikely(!new.inuse && n->nr_partial >= s->min_partial)) {
slab->next = slab_to_discard;
slab_to_discard = slab;
} else {
add_partial(n, slab, DEACTIVATE_TO_TAIL); // [6]
}
}
// [...]
while (slab_to_discard) {
slab = slab_to_discard;
slab_to_discard = slab_to_discard->next;
discard_slab(s, slab); // [5]
}
}
add_partial() 最後走到 __add_partial(),更新數量 (nr_partial) 並 insert slab 到 node 的 partial slab list。
// mm/slub.c
static inline void
__add_partial(struct kmem_cache_node *n, struct slab *slab, int tail)
{
n->nr_partial++;
if (tail == DEACTIVATE_TO_TAIL)
list_add_tail(&slab->slab_list, &n->partial);
else
list_add(&slab->slab_list, &n->partial);
}
discard_slab() 的行為也比想像中簡單,最後會執行到 __free_slab()。該 function 先更新 cache 裡紀錄的 slab 數量後就呼叫 __free_pages() 做釋放。
// mm/slub.c
static void __free_slab(struct kmem_cache *s, struct slab *slab)
{
struct folio *folio = slab_folio(slab);
int order = folio_order(folio);
int pages = 1 << order;
folio->mapping = NULL;
__folio_clear_slab(folio);
unaccount_slab(slab, order, s);
__free_pages(&folio->page, order);
}
透過一張簡單的流程圖,了解 CPU 與 node level 管理 partial slab list 的方式:
5. 大型記憶體的分配與釋放
5.1. 分配
當分配大小超過 general cache 的上限 (8k) 時,會交由 __kmalloc_large_node() 來處理,不過實際上該 function 就只是把請求 forward 給 buddy system 來處理而已。
// mm/slab_common.c
static void *__kmalloc_large_node(size_t size, gfp_t flags, int node)
{
struct page *page;
void *ptr = NULL;
unsigned int order = get_order(size);
// [...]
flags |= __GFP_COMP;
page = alloc_pages_node(node, flags, order);
if (page) {
ptr = page_address(page);
}
// [...]
return ptr;
}
5.2. 釋放
kfree() 在判斷目標記憶體不是由 struct slab 管理後,就會判斷為大塊記憶體並呼叫 free_large_kmalloc() 來處理。因為分配時是由 buddy system 處理,想像得到釋放時也是直接 forward。
// mm/slab_common.c
void free_large_kmalloc(struct folio *folio, void *object)
{
unsigned int order = folio_order(folio);
// [...]
__free_pages(folio_page(folio, 0), order);
}