Linux Kernel Heap Spraying Over A Network Connection
1. 簡介
在 Linux 做 LPE 時,攻擊者有很多方式可以做 heap spraying,但如果情境為 RCE,可能就沒有這麼容易,因此想透過該篇文章了解網卡裝置處理封包請求的方式,也順便探討是否能透過網路服務來 spray 一些與網路相關的結構。
接下來會以 Linux kernel 版本 6.6.32 來分析,VM 使用的 NIC driver 為 e1000e。此外,下方提到的程式碼片段都會刪減一些相較不重要的部分,因此並非完整的執行邏輯。
2. Receive
E1000 在初始化時會註冊 napi (New API) interface 的 polling callback,將硬體裝置的 receive buffer 包裝成物件並清空 (clean)。其中在 MTU 小於 1500 以下時,clean callback 為 function e1000_clean()。
static int e1000_clean(struct napi_struct *napi, int budget)
{
struct e1000_adapter *adapter = container_of(napi, struct e1000_adapter,
napi);
int tx_clean_complete = 0, work_done = 0;
tx_clean_complete = e1000_clean_tx_irq(adapter, &adapter->tx_ring[0]);
adapter->clean_rx(adapter, &adapter->rx_ring[0], &work_done, budget);
// [...]
}
e1000_clean() 會呼叫 e1000_clean_rx_irq(),把資料包成 struvt sk_buff (後續以 skb 代稱) 並送到上層的網路協議。當封包 payload 大小小於 256 時由 e1000_copybreak() [1] 分配 skb,否則由 napi_build_skb() 分配 [2]。當取得 skb 後,會呼叫 e1000_receive_skb() 將 skb 複製到 receive queue。
static bool e1000_clean_rx_irq(struct e1000_adapter *adapter,
struct e1000_rx_ring *rx_ring,
int *work_done, int work_to_do)
{
// [...]
length = le16_to_cpu(rx_desc->length);
data = buffer_info->rxbuf.data;
skb = e1000_copybreak(adapter, buffer_info, length, data); // [1]
if (!skb) {
unsigned int frag_len = e1000_frag_len(adapter);
skb = napi_build_skb(data - E1000_HEADROOM, frag_len); // [2]
skb_reserve(skb, E1000_HEADROOM);
buffer_info->dma = 0;
buffer_info->rxbuf.data = NULL;
}
// [...]
if (buffer_info->rxbuf.data == NULL)
skb_put(skb, length);
else /* copybreak skb */
skb_trim(skb, length); // 移除超過 length 的資料
e1000_receive_skb(adapter, status, rx_desc->special, skb);
// [...]
}
e1000_copybreak() 會呼叫 e1000_alloc_rx_skb() 分配 skb [3],並呼叫 skb_put_data() 將 receive buffer 的資料複製到 skb。
static struct sk_buff *e1000_copybreak(struct e1000_adapter *adapter,
struct e1000_rx_buffer *buffer_info,
u32 length, const void *data)
{
struct sk_buff *skb;
if (length > copybreak) // 256
return NULL;
skb = e1000_alloc_rx_skb(adapter, length); // [3]
skb_put_data(skb, data, length);
return skb;
}
e1000_alloc_rx_skb() 底層會呼叫到 __napi_alloc_skb()。該 function 會先分配一個 1k (fragment) 的 data buffer 存資料 [4],之後呼叫 __napi_build_skb() 分配且初始化 skb。
struct sk_buff *__napi_alloc_skb(struct napi_struct *napi, unsigned int len,
gfp_t gfp_mask)
{
// [...]
if (/*...*/) {
len = SZ_1K;
data = page_frag_alloc_1k(&nc->page_small, gfp_mask); // [4]
} // [...]
skb = __napi_build_skb(data, len);
// [...]
skb->head_frag = 1;
}
正常情況 __napi_build_skb() 會從 cache skbuff_head_cache 回傳一個 object 出來,之後呼叫 __build_skb_around() 來初始化 skb 內的成員,包含 struct skb_shared_info [5]。
static struct sk_buff *__napi_build_skb(void *data, unsigned int frag_size)
{
struct sk_buff *skb;
skb = napi_skb_cache_get();
memset(skb, 0, offsetof(struct sk_buff, tail));
__build_skb_around(skb, data, frag_size); // [5]
return skb;
}
napi_build_skb() 處理大於 256 的 payload,最後也是呼叫 __napi_build_skb() [6] 來處理。
struct sk_buff *napi_build_skb(void *data, unsigned int frag_size)
{
struct sk_buff *skb = __napi_build_skb(data, frag_size); // [6]
skb->head_frag = 1;
return skb;
}
兩者的差別在於,如果發現 payload 小於 256 時,會使用 page_frag_alloc_1k() 分配的 buffer 來放資料;反之,當大於 256 時,則是直接用 receive buffer 的記憶體區塊 buffer_info->rxbuf.data。
e1000_receive_skb() 底層呼叫到 gro_normal_one(),將 skb 新增到 rx list [1],並且以一個 batch 為單位發送出去,不過預設 gro_normal_batch 會是 0。
static inline void gro_normal_one(struct napi_struct *napi, struct sk_buff *skb, int segs)
{
list_add_tail(&skb->list, &napi->rx_list); // [1]
napi->rx_count += segs;
if (napi->rx_count >= READ_ONCE(gro_normal_batch))
gro_normal_list(napi);
}
gro_normal_list() 會先呼叫 netif_receive_skb_list_internal(),一路執行到 __netif_receive_skb_list_ptype()。因為並呼叫 packet type 是 IPv4,因此最後會呼叫 ip_packet_type 的 list callback function ip_list_rcv() [2]。
static inline void __netif_receive_skb_list_ptype(struct list_head *head,
struct packet_type *pt_prev,
struct net_device *orig_dev)
{
struct sk_buff *skb, *next;
if (!pt_prev)
return;
if (list_empty(head))
return;
if (pt_prev->list_func != NULL)
INDIRECT_CALL_INET(pt_prev->list_func, ipv6_list_rcv,
ip_list_rcv, head, pt_prev, orig_dev); // [2]
// [...]
}
ip_list_rcv() 接收一個 skb list,並對每個 skb 做 IP header 的檢查,最後呼叫 ip_sublist_rcv_finish()。該 function 一樣接收一個 skb list,unlink 後呼叫 deliver callback [3]。如果 destination 是 local 的話,就會呼叫 ip_local_deliver() 把封包送到更高的 protocol layers。
static void ip_sublist_rcv_finish(struct list_head *head)
{
struct sk_buff *skb, *next;
list_for_each_entry_safe(skb, next, head, list) {
skb_list_del_init(skb);
dst_input(skb); // [3]
}
}
ip_local_deliver() 會在上 RCU lock 後呼叫 ip_protocol_deliver_rcu(),該 function 會在呼叫對應 protocol 的 handler。舉例來說,如果請求為 TCP,就會由 tcp_protocol->handler(),也就是 tcp_v4_rcv() 來處理 [4]。
void ip_protocol_deliver_rcu(struct net *net, struct sk_buff *skb, int protocol)
{
const struct net_protocol *ipprot;
int raw, ret;
ipprot = rcu_dereference(inet_protos[protocol]);
if (ipprot) {
// [...]
ret = INDIRECT_CALL_2(ipprot->handler, tcp_v4_rcv, udp_rcv,
skb); // [4]
// [...]
}
}
tcp_v4_rcv() 則是會做 TCP 的檢查,並執行一些 hook 處理,像是 filter handler [5]。做完檢查後,最後會呼叫 tcp_v4_do_rcv() 做處理。
int tcp_v4_rcv(struct sk_buff *skb)
{
// [...]
if (tcp_filter(sk, skb)) { // [5]
drop_reason = SKB_DROP_REASON_SOCKET_FILTER;
goto discard_and_relse;
}
// [...]
if (sk->sk_state == TCP_LISTEN) {
ret = tcp_v4_do_rcv(sk, skb);
goto put_and_return;
}
// [...]
if (!sock_owned_by_user(sk)) {
ret = tcp_v4_do_rcv(sk, skb);
}
}
當 tcp_v4_do_rcv() 發現 socket state 為 TCP_ESTABLISHED,代表連線已經建立,呼叫 tcp_rcv_established()。
tcp_rcv_established() 會再執行到 tcp_ack() [6] 處理 ACK 請求,之後呼叫 tcp_data_queue() enqueue skb 到 socket 的 receive queue [7]。
void tcp_rcv_established(struct sock *sk, struct sk_buff *skb)
{
// [...]
if (len <= tcp_header_len) {
// [...]
} else {
// [...]
if ((int)skb->truesize > sk->sk_forward_alloc)
goto step5;
// [...]
}
step5:
reason = tcp_ack(sk, skb, FLAG_SLOWPATH | FLAG_UPDATE_TS_RECENT); // [6]
if ((int)reason < 0) {
reason = -reason;
goto discard;
}
// [...]
tcp_data_queue(sk, skb); // [7]
}
tcp_data_queue() 會呼叫 tcp_queue_rcv(),而 tcp_queue_rcv() 在 enqueue 之前會嘗試與之前的 skb merge [8]。若判斷不需要 merge,就會 enqueue 到 socket object 的 sk_receive_queue 當中。
static int __must_check tcp_queue_rcv(struct sock *sk, struct sk_buff *skb,
bool *fragstolen)
{
int eaten;
struct sk_buff *tail = skb_peek_tail(&sk->sk_receive_queue);
eaten = (tail &&
tcp_try_coalesce(sk, tail,
skb, fragstolen)) ? 1 : 0; // [8]
tcp_rcv_nxt_update(tcp_sk(sk), TCP_SKB_CB(skb)->end_seq);
if (!eaten) {
__skb_queue_tail(&sk->sk_receive_queue, skb); // [9]
skb_set_owner_r(skb, sk);
}
return eaten;
}
3. Release
每個 packet 都會對應到一個 skb 並且執行到 tcp_queue_rcv(),但如果 tcp_queue_rcv() 認為當前的 skb 可以與前一個合併 [1],就會在複製資料與更新結構後,將這次的 skb 釋放掉 [2]。
static void tcp_data_queue(struct sock *sk, struct sk_buff *skb)
{
// [...]
eaten = tcp_queue_rcv(sk, skb, &fragstolen); // [1]
// [...]
if (eaten > 0)
kfree_skb_partial(skb, fragstolen); // [2]
// [...]
}
kfree_skb_partial() 會根據傳入的參數來決定釋放的方式,如果目標 skb 原本是 list head 就執行額外的處理 [3]。
void kfree_skb_partial(struct sk_buff *skb, bool head_stolen)
{
if (head_stolen) {
skb_release_head_state(skb); // [3]
kmem_cache_free(skbuff_cache, skb);
} else {
__kfree_skb(skb);
}
}
由此可知能否 spraying 成功的關鍵在於 tcp_try_coalesce()。當 TCP sequence number 不同時 [4] 或硬體為 TLS 裝置 [5] 能馬上知道不需要做 coalesce,最後會再由 skb_try_coalesce() 做檢查 [6]。
static bool tcp_try_coalesce(struct sock *sk,
struct sk_buff *to,
struct sk_buff *from,
bool *fragstolen)
{
int delta;
*fragstolen = false;
if (TCP_SKB_CB(from)->seq != TCP_SKB_CB(to)->end_seq) // [4]
return false;
if (from->decrypted != to->decrypted) // [5]
return false;
if (!skb_try_coalesce(to, from, fragstolen, &delta)) // [6]
return false;
// [...]
return true;
}
skb_try_coalesce() 在下面幾個情況會認為不用合併 skb,像是 skb 透過 skb_clone() 分配 [7]、要被 merge 的兩個 skb 其中一個使用 zero copy [8]、已經有太多 fragment [9]、 以及其他等等更複雜的情況。不過在檢查合併的條件之前,如果 kernel 發現前一個 skb 還有空間 [10],就會直接 coalesce。
bool skb_try_coalesce(struct sk_buff *to, struct sk_buff *from,
bool *fragstolen, int *delta_truesize)
{
struct skb_shared_info *to_shinfo, *from_shinfo;
int i, delta, len = from->len;
*fragstolen = false;
if (skb_cloned(to)) // [7]
return false;
if (len <= skb_tailroom(to)) { // [10]
skb_copy_bits(from, 0, skb_put(to, len), len);
*delta_truesize = 0;
return true;
}
// [...]
if (skb_zcopy(to) || skb_zcopy(from)) // [8]
return false;
if (skb_headlen(from) != 0) {
// [...]
if (to_shinfo->nr_frags +
from_shinfo->nr_frags >= MAX_SKB_FRAGS) // [9]
return false;
// [...]
} else {
if (to_shinfo->nr_frags +
from_shinfo->nr_frags > MAX_SKB_FRAGS) // [9]
return false;
// [...]
}
// [...]
return true;
}
4. 猜想
我們能從 tcp_try_coalesce() 的實作得知,如果可以透過發送與預期不同 TCP sequence 的 packet,就會在 tcp_try_coalesce() 一開始的檢查被判斷成不做 coalesce,這樣就可以透過遠端連線來 spraying struct sk_buff 與 data buffer。
5. 實驗
將 server 執行在 VM 當中,並透過 host network formwarding 的方式與 server 互動。下方為執行 VM 的腳本:
qemu-system-x86_64 \
-m 1G \
-smp 1 \
-nographic \
-monitor /dev/null \
-kernel ./arch/x86_64/boot/bzImage \
-append "console=ttyS0 nokaslr pti=on quiet" \
-cpu qemu64,+smep,+smap \
-initrd ./rootfs.cpio \
-netdev user,id=mynet0,hostfwd=tcp::1337-:1337 \
-device e1000,netdev=mynet0 \
-s
嘗試 1 - BPF
安裝 bcc:
sudo apt-get install bpfcc-tools linux-headers-$(uname -r)
寫 BPF program 來 hook TCP request 並改變 sequence number,最後修好 checksum 後送出。下方的 bpf program 假設 server port 聽在 1337。
#!/usr/bin/python3
from bcc import BPF
bpf_program = '''
#include <linux/if_ether.h>
#include <linux/ip.h>
#include <linux/tcp.h>
int modify_tcp_seq(struct xdp_md *ctx) {
void *data_end = (void *)(long)ctx->data_end;
void *data = (void *)(long)ctx->data;
struct ethhdr *eth = data;
if ((void *)ð[1] > data_end)
return XDP_PASS;
if (eth->h_proto != htons(ETH_P_IP))
return XDP_PASS;
struct iphdr *iph = data + sizeof(*eth);
if ((void *)&iph[1] > data_end)
return XDP_PASS;
if (iph->protocol != IPPROTO_TCP)
return XDP_PASS;
struct tcphdr *tcph = data + sizeof(*eth) + sizeof(*iph);
if ((void *)&tcph[1] > data_end)
return XDP_PASS;
if (ntohs(tcph->dest) != 1337)
return XDP_PASS;
__u32 new_seq = bpf_htonl(bpf_ntohl(tcph->seq) - (bpf_get_prandom_u32() % 0x1000));
__u32 new_check;
{
uint32_t sum = ~ntohs(tcph->check) & 0xffff;
sum -= (ntohs(tcph->seq >> 16) & 0xffff);
sum -= (ntohs(tcph->seq & 0xffff) & 0xffff);
sum += (ntohs(new_seq >> 16) & 0xffff);
sum += (ntohs(new_seq & 0xffff) & 0xffff);
sum = (sum & 0xffff) + (sum >> 16);
new_check = htons(~sum);
}
tcph->check = new_check;
tcph->seq = new_seq;
return XDP_PASS;
}
'''
bpf = BPF(text=bpf_program)
fn = bpf.load_func("modify_tcp_seq", BPF.XDP)
bpf.attach_xdp("lo", fn, 0)
try:
bpf.trace_print()
except KeyboardInterrupt:
pass
bpf.remove_xdp("lo", 0)
不過使用這個方式會因為直接 reuse kernel 的 TCP stack 的關係,讓 kernel 收不到 server 回傳的 ACK 而不斷重送,導致剩下的 TCP packet 都會一直卡在 queue 送不出去。
嘗試 2 - Scapy
透過 Scapy 我們可以控制整個 TCP 互動的流程,這樣就不會被 kernel 影響。不過在建置執行環境時會踩到一些雷,下方提供問題以及相對應的解法:
- Loopback device 沒有辦法正常的 handshake
- https://stackoverflow.com/a/41449990
- https://github.com/secdev/scapy/blob/master/doc/scapy/troubleshooting.rst#i-cant-ping-127001-or-1-scapy-does-not-work-with-127001-or-1-on-the-loopback-interface
- Kernel 會因為發現 server 並沒有開啟 packet 指定的 source port 而自動回傳 RST
- https://stackoverflow.com/a/9154940
- https://github.com/secdev/scapy/blob/master/doc/scapy/troubleshooting.rst#my-tcp-connections-are-reset-by-scapy-or-by-my-kernel
- iptables command
sudo iptables -A OUTPUT -d 127.0.0.1 -p tcp --dport 1337 --tcp-flags RST RST -j DROP
成功建置環境後,接下來就可以直接透過 scapy 發送 raw pakcet 跟 server 互動。假設在 handshake 後 client 會先跟 server 交換一次資料,然後 server 就會 hang 住不呼叫 recv() 相關的 function 收封包。首先發送 SYN [1] 與 ACK [2] 做三項交握,之後發送 8 個 “A” [3] 並接收 server 回傳的資料 [4]。最後在發送一個正常的封包後 [5] 不斷送 sequence 不相同的封包 [6]。
from scapy.all import *
import random
conf.L3socket = L3RawSocket
target_ip = "127.0.0.1"
target_port = 1337
src_port = random.randint(1338, 65535)
# [1]
syn_packet = IP(dst=target_ip)/TCP(sport=src_port, dport=target_port, flags="S")
syn_ack_response = sr1(syn_packet)
if syn_ack_response and syn_ack_response.haslayer(TCP) and syn_ack_response[TCP].flags == "SA":
# [2]
ack_packet = IP(dst=target_ip)/TCP(sport=src_port, dport=target_port, flags="A", seq=syn_ack_response.ack, ack=syn_ack_response.seq+1)
send(ack_packet)
print("Handshake successful")
else:
print("Handshake failed")
exit(1)
seq = syn_ack_response.ack
ack = syn_ack_response.seq + 1
# [3] 送資料
data_packet = IP(dst=target_ip)/TCP(sport=src_port, dport=target_port, flags="PA", seq=seq, ack=ack)/Raw(load=b"AAAAAAAA")
data_response = sr1(data_packet)
seq += len(data_packet[Raw].load)
# [4] 接收回傳的資料
s = L3RawSocket()
p = s.recv(MTU)
ack = p[TCP].seq + len(p[Raw])
data_packet = IP(dst=target_ip)/TCP(sport=src_port, dport=target_port, flags="A", seq=seq, ack=ack)
send(data_packet)
# [5]
data_packet = IP(dst=target_ip)/TCP(sport=src_port, dport=target_port, flags="PA", seq=seq, ack=ack)/Raw(load=b"A"*0x100)
data_response = sr1(data_packet)
old_seq = seq
seq += len(data_packet[Raw].load)
assert(data_response.ack == seq)
# [6]
while True:
input("bad seq >")
data_packet = IP(dst=target_ip)/TCP(sport=src_port, dport=target_port, flags="PA", seq=seq + 10, ack=ack + 10)/Raw(load=b"A"*0x100)
send(data_packet)
但因為 host 是用 network forwarding 與跑在 VM 內的 server 互動,因此用 Scapy 發送的請求會先過 host kernel network,並被視為異常封包而擋下來,沒辦法轉發到 VM 內。不過如果 target server 是實體機,應該不會有這個問題,不過環境處理上有點小麻煩,加上手邊沒多的機器,因此該測試方法就先擱置。
# ...
-netdev user,id=mynet0,hostfwd=tcp::1337-:1337 \
-device e1000,netdev=mynet0 \
# ...
嘗試 3 - 透過 debugger 手動調整 sequence
透過先前的執行流程分析能得知 function tcp_v4_rcv() 才會開始處理 TCP header,因此斷點在該 function 中間 [1] 並且直接用 debugger 改 TCP sequence。
int tcp_v4_rcv(struct sk_buff *skb)
{
// [...]
th = (const struct tcphdr *)skb->data; // [1]
// [...]
tcp_v4_fill_cb(skb, iph, th);
// [...]
if (!sock_owned_by_user(sk)) {
ret = tcp_v4_do_rcv(sk, skb);
}
// [...]
}
所有與 sequence 的檢查都會在 function tcp_rcv_established() 之後。tcp_rcv_established() 得知 sequence 與預期 (tp->rcv_nxt) 不相符時就會走 slow path,並且透過 slow path 處理的 packet 需要設置 ACK、RST 與 SYN 中至少一個 flag。之後會呼叫 tcp_validate_incoming() [2] 檢查 packet sequence,若沒問題才會繼續往下執行。
void tcp_rcv_established(struct sock *sk, struct sk_buff *skb)
{
if (TCP_SKB_CB(skb)->seq == tp->rcv_nxt && /* ... */) {}
// [...]
slow_path:
// [...]
if (!th->ack && !th->rst && !th->syn) {
reason = SKB_DROP_REASON_TCP_FLAGS;
goto discard;
}
// [...]
if (!tcp_validate_incoming(sk, skb, th, 1)) // [2]
return;
// [...]
tcp_data_queue(sk, skb);
// [...]
}
如果 packet 是 RST 或 SYN,tcp_validate_incoming() 就會判斷該 packet 要被 drop 掉,但如果是 ACK,還是需要滿足 sequence 在範圍內。一共有兩個限制:end sequence 不能小於 tp->rcv_wup (rcv_nxt on last window update sent) [3],以及 sequence 不能超過預期的 receive sequence + receive windows size [4]。
static enum skb_drop_reason tcp_sequence(const struct tcp_sock *tp,
u32 seq, u32 end_seq)
{
if (before(end_seq, tp->rcv_wup)) // [3]
return SKB_DROP_REASON_TCP_OLD_SEQUENCE;
if (after(seq, tp->rcv_nxt + tcp_receive_window(tp))) // [4]
return SKB_DROP_REASON_TCP_INVALID_SEQUENCE;
return SKB_NOT_DROPPED_YET;
}
當上述條件滿足,就會接著執行到 tcp_data_queue()。如果 sequence 小於預期 [5],就會執行 tcp_queue_rcv(),反之如果 sequence 大於預期 [6],就會被視為 out-of-order packet,呼叫 tcp_data_queue_ofo() 處理。
static void tcp_data_queue(struct sock *sk, struct sk_buff *skb)
{
if (TCP_SKB_CB(skb)->seq == tp->rcv_nxt) {
queue_and_out:
// [...]
eaten = tcp_queue_rcv(sk, skb, &fragstolen);
// ... 原本的處理邏輯
}
if (!before(TCP_SKB_CB(skb)->seq,
tp->rcv_nxt + tcp_receive_window(tp))) {
// [...]
// drop packet
}
if (before(TCP_SKB_CB(skb)->seq, tp->rcv_nxt)) { // [5]
// [...]
goto queue_and_out;
}
tcp_data_queue_ofo(sk, skb); // [6]
}
tcp_data_queue_ofo() 會把 skb enqueue 到 out of order queue 而非 receive queue [7]。雖然乍看之下這條 path 可以避免 receive queue 的 skb 做 coalesce,但實際上後續執行流程還是會遍歷整個 out of order RB tree 並嘗試合併 overlap 的 skb segment [8],因此發送大於預期的 sequence 可能行不通。
static void tcp_data_queue_ofo(struct sock *sk, struct sk_buff *skb)
{
// [...]
p = &tp->out_of_order_queue.rb_node;
if (RB_EMPTY_ROOT(&tp->out_of_order_queue)) {
// [...]
// 將 skb 存成 root
goto end;
}
if (tcp_ooo_try_coalesce(sk, tp->ooo_last_skb,
skb, &fragstolen)) {
// [...]
// 做 coalesce
}
// [...]
insert:
/* Insert segment into RB tree. */
rb_link_node(&skb->rbnode, parent, p);
rb_insert_color(&skb->rbnode, &tp->out_of_order_queue); // [7]
merge_right:
/* Remove other segments covered by skb. */
while ((skb1 = skb_rb_next(skb)) != NULL) { // [8]
// [...]
// 找出 overlap 的 segment 並移除
}
}
當 sequence 小於預期時,tcp_data_queue() 一樣會呼叫 tcp_queue_rcv() 接收 packet,並且一定程度下可以控制 sequence value,讓 tcp_try_coalesce() 回傳 false 而不跟前一個 skb 做 coalesce。
於是我們得到理論上可以讓 enqueue 的 packet 不會被合併的四個 sequence value 限制:
!before(end_seq, tp->rcv_wup)- end sequence 不能是 old sequence!after(seq, tp->rcv_nxt + tcp_receive_window(tp))- sequence 不能超出 receive windowbefore(TCP_SKB_CB(skb)->seq, tp->rcv_nxt)- sequence 需要小於 kernel 預期收到的TCP_SKB_CB(from)->seq != TCP_SKB_CB(to)->end_seq- sequence 不能是前一個 packet 的 end_seq
tcp_receive_window() 會回傳剩下還能用的 window size。
static inline u32 tcp_receive_window(const struct tcp_sock *tp)
{
/**
* rcv_wup - rcv_nxt on last window update sent
* rcv_nxt - What we want to receive next
* rcv_wnd - Current receiver window
*/
s32 win = tp->rcv_wup + tp->rcv_wnd - tp->rcv_nxt;
if (win < 0)
win = 0;
return (u32) win;
}
關於 TCP Window 可以參考該文章,介紹得非常詳細。一般情況下,存起來的 skb 跟 receive window 的關係大概會長得像下圖,其中 skb1 與 skb2 會被 coalesce 成同一個。
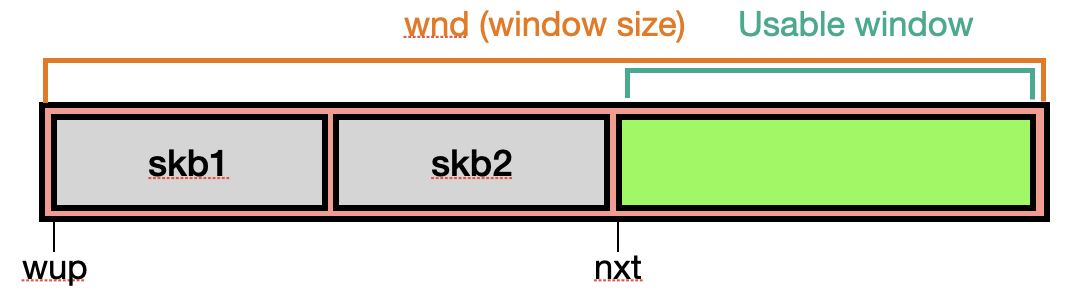
但如果在傳送的過程中故意省略掉一些 sequence,就會變成類似下圖的情況。
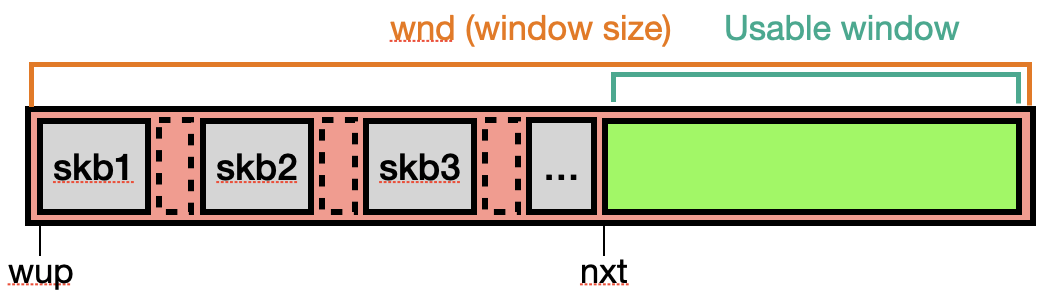
不過這個想法仍屬於猜測階段,還沒實際測試過,因此不保證是個可行的方式。
6. 假設不成立
6.1. UDP
UDP request handler 的進入點為 udp_rcv(),後續會執行到 udp_queue_rcv_skb()。而 UDP 有 GSO (Generic Segmentation Offload) 的機制,但如果沒有啟用或是設定失敗,就會直接由 udp_queue_rcv_one_skb() 處理 [1];反之如果有,就會先呼叫 udp_rcv_segment() 處理 UDP GRO [2]。
static int udp_queue_rcv_skb(struct sock *sk, struct sk_buff *skb)
{
struct sk_buff *next, *segs;
int ret;
if (likely(!udp_unexpected_gso(sk, skb)))
return udp_queue_rcv_one_skb(sk, skb); // [1]
__skb_push(skb, -skb_mac_offset(skb));
segs = udp_rcv_segment(sk, skb, true); // [2]
skb_list_walk_safe(segs, skb, next) {
__skb_pull(skb, skb_transport_offset(skb));
udp_post_segment_fix_csum(skb);
ret = udp_queue_rcv_one_skb(sk, skb);
// [...]
}
return 0;
}
udp_queue_rcv_one_skb() 會處理 UDP Encapsulation 以及 UDP-lite,但如果是一般的 UDP packet 最後會執行到 __udp_enqueue_schedule_skb()。該 function 檢查 read memory 分配是否超出 receive buffer [3],看 buffer 是否有足夠空間放下 packet [4],最後在更新 buffer size 後 enqueue skb [5]。
int __udp_enqueue_schedule_skb(struct sock *sk, struct sk_buff *skb)
{
struct sk_buff_head *list = &sk->sk_receive_queue;
int rmem, err = -ENOMEM;
spinlock_t *busy = NULL;
int size;
rmem = atomic_read(&sk->sk_rmem_alloc);
if (rmem > sk->sk_rcvbuf) // [3]
goto drop;
// [...]
size = skb->truesize;
rmem = atomic_add_return(size, &sk->sk_rmem_alloc);
if (rmem > (size + (unsigned int)sk->sk_rcvbuf)) // [4]
goto uncharge_drop;
spin_lock(&list->lock);
err = udp_rmem_schedule(sk, size);
// [...]
sk_forward_alloc_add(sk, -size);
sock_skb_set_dropcount(sk, skb);
__skb_queue_tail(list, skb); // [5]
// [...]
return 0;
}
不過到這邊才發現 receiver buffer size 是用 skb->truesize 來更新,也就是 object size 與 data buffer size 的總和。舉例來說,payload 大小為 1 的 packet 其 skb->truesize 會是 1280,等同於 size of skbuff_head_cache (0x100) 加上 buffer size allocated at __napi_alloc_skb() (0x400)。因此一個 socket 所牽扯到的 packet object 最多就只能有 212992 bytes (sysctl_rmem_max) — 也就是 208 KB 的記憶體使用量,並不是指 payload 大小的總和。
6.2. TCP Check
當發現 UDP 有這個檢查時,就覺得 TCP 一定有類似的操作,只是我當初沒有注意到在哪邊處理。
在 tcp_data_queue() 接收 packet 之前,會先檢查 receive buffer 是否有足夠的空間 [1]。
static void tcp_data_queue(struct sock *sk, struct sk_buff *skb)
{
// [...]
if (tcp_try_rmem_schedule(sk, skb, skb->truesize)) { // [1]
inet_csk(sk)->icsk_ack.pending |=
(ICSK_ACK_NOMEM | ICSK_ACK_NOW);
inet_csk_schedule_ack(sk);
sk->sk_data_ready(sk);
if (skb_queue_len(&sk->sk_receive_queue)) {
reason = SKB_DROP_REASON_PROTO_MEM;
NET_INC_STATS(sock_net(sk), LINUX_MIB_TCPRCVQDROP);
goto drop;
}
sk_forced_mem_schedule(sk, skb->truesize);
}
// [...]
eaten = tcp_queue_rcv(sk, skb, &fragstolen);
// [...]
}
tcp_try_rmem_schedule() 會檢查累積分配的記憶體 (sk->sk_rmem_alloc) 是否超出 receive buffer size [2]。如果超過 buffer size,就會 prune receive queue [3] 以及 out-of-order queue [4] 直到有記憶體為止。
static int tcp_try_rmem_schedule(struct sock *sk, struct sk_buff *skb,
unsigned int size)
{
if (atomic_read(&sk->sk_rmem_alloc) > sk->sk_rcvbuf || // [2]
!sk_rmem_schedule(sk, skb, size)) {
if (tcp_prune_queue(sk, skb) < 0) // [3]
return -1;
while (!sk_rmem_schedule(sk, skb, size)) {
if (!tcp_prune_ofo_queue(sk, skb)) // [4]
return -1;
}
}
return 0;
}
每次 tcp_queue_rcv() enqueue 時都會更新 sk->sk_rmem_alloc 以及 sk->sk_forward_alloc [4] [5]。sk->sk_forward_alloc 看名稱會以為是預分配的記憶體的大小,不過實際上並不會額外分配記憶體,而是被用來管理 socket 使用記憶體的狀況 。
static int __must_check tcp_queue_rcv(struct sock *sk, struct sk_buff *skb,
bool *fragstolen)
{
int eaten;
struct sk_buff *tail = skb_peek_tail(&sk->sk_receive_queue);
eaten = (tail &&
tcp_try_coalesce(sk, tail, // [4]
skb, fragstolen)) ? 1 : 0;
// [...]
if (!eaten) {
__skb_queue_tail(&sk->sk_receive_queue, skb);
skb_set_owner_r(skb, sk); // [5]
}
// [...]
}
因此 TCP 紀錄的也是 socket 所有佔掉 memory size,並且一樣會限制 total size 會落在 receive buffer size 之內。
7. 結論
不論使用 UDP、TCP 或是在 TCP 中構造奇怪的 sequence value,每個 socket 最多就只能佔 sysctl_rmem_max 的 memory size,而該變數的值預設會是 208 KB (212992 bytes)。