Linux Kernel Use Pipe Object to Do Data-Only Attack
在 Linux kernel exploit 中常看到與 pipe object 相關的利用手法,像是以 Dirty Pipe 為靈感的 pipe-primitive,或者是 2024 BHUSA 發表的 PageJack。該篇文章會先追 v6.6.42 pipe object 的建立與釋放流程,再來會介紹 Dirty Dipe 的成因,最後分析 pipe-based 的攻擊技巧:pipe-primitive 以及 PageJack。
1. Introduction
Pipe Create
pipe[] 的建立是透過 syscall pipe [1] 或是 pipe2 [2],兩者只差在後者可以傳入參數 flags,前者為預設參數 0,不過兩者都會呼叫 do_pipe2() 來建立 pipe object。
SYSCALL_DEFINE1(pipe, int __user *, fildes) // [1]
{
return do_pipe2(fildes, 0);
}
SYSCALL_DEFINE2(pipe2, int __user *, fildes, int, flags) // [2]
{
return do_pipe2(fildes, flags);
}
Function do_pipe2() 會再呼叫 __do_pipe_flags(),而該 function 先建立 pipe file pair [3],並 install 到兩個沒有在使用的 fd [4, 5]。
static int __do_pipe_flags(int *fd, struct file **files, int flags)
{
// [...]
error = create_pipe_files(files, flags); // [3]
// [...]
error = get_unused_fd_flags(flags); // [4]
// [...]
error = get_unused_fd_flags(flags); // [5]
// [...]
}
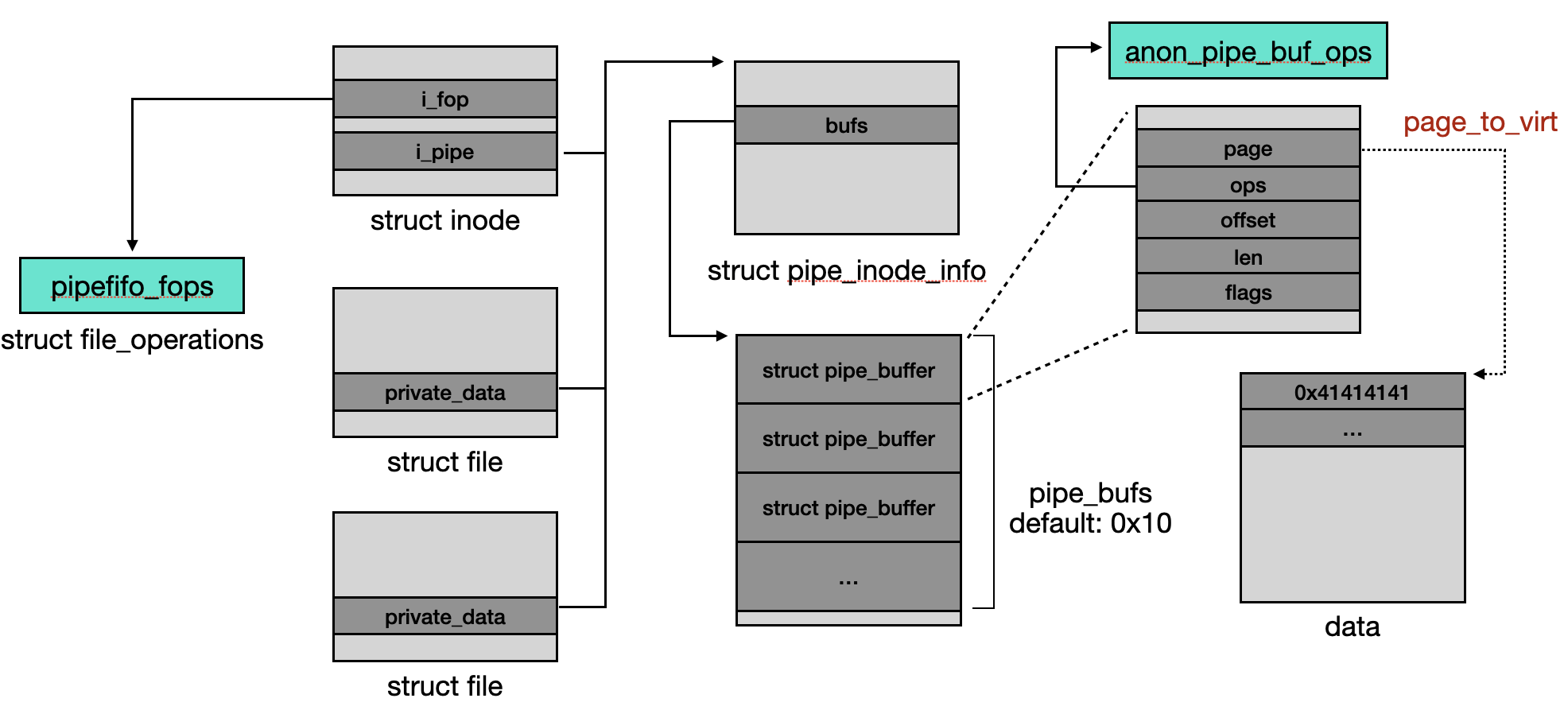
create_pipe_files() 會建立 default struct pipe_inode_info object [6],其中 inode 的 operation pointer inode->i_fop 指向 &pipefifo_fops。之後會呼叫 alloc_file_pseudo() 分配一個 write-only 的 file object [7],底層還會分配與 path / dentry 相關的 object。由於 pipe 是雙向的,會再用 alloc_file_clone() clone 一個 read-only 的 [8],而這兩個 file object 的 private 指向同一個 object,也就是 inode->i_pipe (struct pipe_inode_info) [9]。
int create_pipe_files(struct file **res, int flags)
{
struct inode *inode = get_pipe_inode(); // [6]
// [...]
f = alloc_file_pseudo(inode, pipe_mnt, "", // [7]
O_WRONLY | (flags & (O_NONBLOCK | O_DIRECT)),
&pipefifo_fops);
// [...]
f->private_data = inode->i_pipe; // [9]
// [...]
res[0] = alloc_file_clone(f, O_RDONLY | (flags & O_NONBLOCK),
&pipefifo_fops); // [8]
// [...]
res[0]->private_data = inode->i_pipe; // [9]
// [...]
}
pipe_inode_info object 是由 alloc_pipe_info() 分配與初始化,預設會分配 16 個 struct pipe_buffer object [10],而每個 object 大小為 40,因此會落在 kmalloc-cg-1k (大小 0x280)。這個 pipe buffer array 被設計成是一個 ring buffer,且 head 與 tail 都會被初始化成 0。
struct pipe_inode_info *alloc_pipe_info(void)
{
struct pipe_inode_info *pipe;
unsigned long pipe_bufs = PIPE_DEF_BUFFERS; // 0x10
struct user_struct *user = get_current_user();
unsigned long user_bufs;
unsigned int max_size = READ_ONCE(pipe_max_size); // 0x100000
pipe = kzalloc(sizeof(struct pipe_inode_info), GFP_KERNEL_ACCOUNT);
if (pipe_bufs * PAGE_SIZE > max_size && !capable(CAP_SYS_RESOURCE))
pipe_bufs = max_size >> PAGE_SHIFT;
user_bufs = account_pipe_buffers(user, 0, pipe_bufs);
// [...]
pipe->bufs = kcalloc(pipe_bufs, sizeof(struct pipe_buffer), // [10]
GFP_KERNEL_ACCOUNT);
if (pipe->bufs) {
// [...]
pipe->max_usage = pipe_bufs;
pipe->ring_size = pipe_bufs;
// [...]
return pipe;
}
}
Pipe Write
對 pipe fd 的寫入會由 pipe_write() 來處理。當該 function 發現 pipe 沒有可以用的 page 時,會分配一個 page [1],並 assgin 給 head pipe_buffer [2],最後把資料複製到該 page 內 [3]。pipe->head 為從哪邊開始寫,而 pipe->tail 是從哪邊開始讀。
static ssize_t
pipe_write(struct kiocb *iocb, struct iov_iter *from)
{
// [...]
for (;;) {
// [...]
head = pipe->head;
if (!pipe_full(head, pipe->tail, pipe->max_usage)) {
unsigned int mask = pipe->ring_size - 1;
struct pipe_buffer *buf;
struct page *page = pipe->tmp_page;
int copied;
if (!page) {
page = alloc_page(GFP_HIGHUSER | __GFP_ACCOUNT); // [1]
pipe->tmp_page = page;
}
// [...]
buf = &pipe->bufs[head & mask]; // [2]
buf->page = page;
buf->ops = &anon_pipe_buf_ops;
buf->offset = 0;
buf->len = 0;
// [...]
copied = copy_page_from_iter(page, 0, PAGE_SIZE, from); // [3]
// [...]
}
}
}
Splice
Syscall splice 允許使用者可以不需要經過 kernel space,在兩個 file 之間傳送資料,但其中一個 (source or destination) 需要是 pipe object。
一開始會由 syscall handler 處理請求,在更新 input [1] / output [2] struct file object 的 refcnt 後呼叫 __do_splice() [3]。
SYSCALL_DEFINE6(splice, int, fd_in, loff_t __user *, off_in,
int, fd_out, loff_t __user *, off_out,
size_t, len, unsigned int, flags)
{
struct fd in, out;
// [...]
in = fdget(fd_in); // [1]
if (in.file) {
out = fdget(fd_out); // [2]
if (out.file) {
error = __do_splice(in.file, off_in, out.file, off_out, // [3]
len, flags);
fdput(out);
}
fdput(in);
}
return error;
}
__do_splice() 會走到 do_splice(),並根據 source 與 destination 的不同呼叫不同 function:
| CASE | INPUT FILE | OUTPUT FILE | HANDLER |
|---|---|---|---|
| 1 | pipe file | pipe file | splice_pipe_to_pipe() |
| 2 | pipe file | normal file | do_splice_from() |
| 3 | normal file | pipe file | splice_file_to_pipe() |
| 4 | normal file | normal file | -EINVAL |
Case1
Input file 為 pipe file,output file 為 pipe file,呼叫 splice_pipe_to_pipe()。資料從 input pipe 的 tail pipe_buffer 讀出 [1],寫到 output pipe 的 head pipe_buffer [2],不過在此之前會先 prepare pipe,確保 input pipe [3] 有資料,以及 output pipe 有空間 [4]。
複製時分成兩種情況處理,分別為:複製的大小超過 [5] 或小於 [6] 當前 input buffer 的大小。如果超過的話,input pipe 的 tail pipe_buffer 會直接複製給 output buffer 的 head pipe_buffer,並把 pipe_buffer ops 更新成 NULL [7]。小於的話,output pipe_buffer 會 reference 到 pipe_buffer 的 page object [8]。這邊省略了一些 metadata 的更新,像是 head、tail 或是 length 等等。
static int splice_pipe_to_pipe(struct pipe_inode_info *ipipe,
struct pipe_inode_info *opipe,
size_t len, unsigned int flags)
{
ret = ipipe_prep(ipipe, flags); // [3]
ret = opipe_prep(opipe, flags); // [4]
// [...]
i_tail = ipipe->tail;
i_mask = ipipe->ring_size - 1; // [1]
o_head = opipe->head;
o_mask = opipe->ring_size - 1; // [2]
// [...]
do {
ibuf = &ipipe->bufs[i_tail & i_mask];
obuf = &opipe->bufs[o_head & o_mask];
// [...]
if (len >= ibuf->len) { // [5]
*obuf = *ibuf;
ibuf->ops = NULL; // [7]
// update metadata ...
} else { // [6]
pipe_buf_get(ipipe, ibuf); // [8]
*obuf = *ibuf;
// update metadata ...
}
ret += o_len;
len -= o_len;
} while (len);
}
Case2
Input file 為 pipe file,output file 為 normal file,呼叫 do_splice_from()。
do_splice_from() 會再呼叫 file operation 的 .splice_write,大部分會是 iter_file_splice_write()。
static long do_splice_from(struct pipe_inode_info *pipe, struct file *out,
loff_t *ppos, size_t len, unsigned int flags)
{
// [...]
return out->f_op->splice_write(pipe, out, ppos, len, flags);
}
iter_file_splice_write() 負責從 pipe 讀資料寫到 output file,一開始會先建立一個用於寫入資料的 IO vector (struct bio_vec) array [1],之後根據要複製的大小來初始化 vector array [2],data page 就拿 pipe_buffer 的 page [3]。初始化後會再呼叫 iov_iter_bvec() 取得 IO iterator [4],最後呼叫 VFS API vfs_iter_write() 複製資料 [5]。如果 vfs_iter_write() 在非錯誤的情況下有回傳值,就代表有成功讀到資料,之後遍歷並更新 pipe_buffer 的 metadata,過程中也會釋放掉使用完的 pipe_buffer [6]。
ssize_t
iter_file_splice_write(struct pipe_inode_info *pipe, struct file *out,
loff_t *ppos, size_t len, unsigned int flags)
{
struct splice_desc sd = {
.total_len = len,
.flags = flags,
.pos = *ppos,
.u.file = out,
};
int nbufs = pipe->max_usage;
struct bio_vec *array = kcalloc(nbufs, sizeof(struct bio_vec), // [1]
GFP_KERNEL);
// [...]
while (sd.total_len) {
struct iov_iter from;
unsigned int head, tail, mask;
size_t left;
int n;
// [...]
head = pipe->head;
tail = pipe->tail;
mask = pipe->ring_size - 1;
left = sd.total_len;
for (n = 0; !pipe_empty(head, tail) && left && n < nbufs; tail++) {
struct pipe_buffer *buf = &pipe->bufs[tail & mask];
size_t this_len = buf->len;
this_len = min(this_len, left);
ret = pipe_buf_confirm(pipe, buf);
bvec_set_page(&array[n], buf->page, this_len, // [3]
buf->offset);
left -= this_len;
n++;
}
iov_iter_bvec(&from, ITER_SOURCE, array, n, sd.total_len - left); // [4]
ret = vfs_iter_write(out, &from, &sd.pos, 0); // [5]
// [...]
tail = pipe->tail;
while (ret) {
struct pipe_buffer *buf = &pipe->bufs[tail & mask];
if (ret >= buf->len) {
ret -= buf->len;
buf->len = 0;
pipe_buf_release(pipe, buf); // [6]
tail++;
pipe->tail = tail;
if (pipe->files)
sd.need_wakeup = true;
} else {
buf->offset += ret;
buf->len -= ret;
ret = 0;
}
}
}
// [...]
return ret;
}
pipe_buf_release() 用來回收資料已經被讀完的 pipe_buffer,清空 buf->ops 後呼叫 ops object pipe_buf_operations 的 release handler (.release)。
static inline void pipe_buf_release(struct pipe_inode_info *pipe,
struct pipe_buffer *buf)
{
const struct pipe_buf_operations *ops = buf->ops;
buf->ops = NULL;
ops->release(pipe, buf);
}
struct pipe_buffer 的 ops 會指向 anon_pipe_buf_ops,其 release handler 為 anon_pipe_buf_release()。該 function 會更新 data page 的 refcnt 並嘗試釋放 [7],但如果提前發現 refcnt 為 1 並且沒有 temp page 可以用 [8] 時,會直接將其用做 temp page。
static void anon_pipe_buf_release(struct pipe_inode_info *pipe,
struct pipe_buffer *buf)
{
struct page *page = buf->page;
if (page_count(page) == 1 && !pipe->tmp_page) // [8]
pipe->tmp_page = page;
else
put_page(page); // [7]
}
Case3
Input file 為 normal file,output file 為 pipe file,呼叫 splice_file_to_pipe()。
在檢查完 input file position 以及 length 後,會呼叫 file operation 的 .splice_read,其大多會是 copy_splice_read() 或 filemap_splice_read()。
long vfs_splice_read(struct file *in, loff_t *ppos,
struct pipe_inode_info *pipe, size_t len,
unsigned int flags)
{
// [...]
return in->f_op->splice_read(in, ppos, pipe, len, flags);
}
copy_splice_read() 會先把資料從 input file 讀出,再寫到 pipe 內。檔案大小通常沒有限制,pipe 卻會有上限,因此該 function 一開始會先調整要複製的資料大小,避免超過 pipe 的資料量上限 [1]。為了從檔案讀資料出來,會先建一個 IO vector (struct bio_vec) array [2],再來會呼叫 alloc_pages_bulk_array() 建立 npages 個 order-0 的 data page object (struct page *) [3],最後呼叫 call_read_iter() 把資料寫到 data page 內 [4]。不過 file 也不一定有這麼多資料,所以需要把多分配的 page object 給釋放掉 [5]。後續只需要初始化 pipe_buffer 並複製 file content 的 page object 給 member .page 即可 [6]。
ssize_t copy_splice_read(struct file *in, loff_t *ppos,
struct pipe_inode_info *pipe,
size_t len, unsigned int flags)
{
struct iov_iter to;
struct bio_vec *bv;
struct kiocb kiocb;
struct page **pages;
ssize_t ret;
size_t used, npages, chunk, remain, keep = 0;
int i;
// [1]
used = pipe_occupancy(pipe->head, pipe->tail);
npages = max_t(ssize_t, pipe->max_usage - used, 0);
len = min_t(size_t, len, npages * PAGE_SIZE);
npages = DIV_ROUND_UP(len, PAGE_SIZE);
bv = kzalloc(array_size(npages, sizeof(bv[0])) + // [2]
array_size(npages, sizeof(struct page *)), GFP_KERNEL);
pages = (struct page **)(bv + npages);
npages = alloc_pages_bulk_array(GFP_USER, npages, pages); // [3]
// [...]
ret = call_read_iter(in, &kiocb, &to); // [4]
keep = DIV_ROUND_UP(ret, PAGE_SIZE);
// [...]
if (keep < npages)
release_pages(pages + keep, npages - keep); // [5]
remain = ret;
for (i = 0; i < keep; i++) {
struct pipe_buffer *buf = pipe_head_buf(pipe);
chunk = min_t(size_t, remain, PAGE_SIZE);
*buf = (struct pipe_buffer) {
.ops = &default_pipe_buf_ops,
.page = bv[i].bv_page, // [6]
.offset = 0,
.len = chunk,
};
pipe->head++;
remain -= chunk;
}
// [...]
return ret;
}
filemap_splice_read() 會先把 struct kiocb object [1] 跟 input file object bind 在一起,而 struct kiocb 是一個被用來處理 kernel space 與硬體裝置之間 IO 操作的 object。之後 filemap_splice_read() 會算出 target pipe 還有多少 page 可以用 [2],並呼叫 filemap_get_pages() 取得 struct folio_batch object [3],folio object 可以想成是一個 page object group,由一或多個 page object 組成。最後呼叫 splice_folio_into_pipe(),把 file content 複製到 pipe buffer 內 [4]。
ssize_t filemap_splice_read(struct file *in, loff_t *ppos,
struct pipe_inode_info *pipe,
size_t len, unsigned int flags)
{
struct folio_batch fbatch;
struct kiocb iocb;
size_t total_spliced = 0, used, npages;
loff_t isize, end_offset;
bool writably_mapped;
int i, error = 0;
// [...]
init_sync_kiocb(&iocb, in); // [1]
len = min_t(size_t, len, npages * PAGE_SIZE); // [2]
do {
// [...]
iocb.ki_pos = *ppos;
error = filemap_get_pages(&iocb, len, &fbatch, true); // [3]
// [...]
isize = i_size_read(in->f_mapping->host);
end_offset = min_t(loff_t, isize, *ppos + len);
for (i = 0; i < folio_batch_count(&fbatch); i++) {
struct folio *folio = fbatch.folios[i];
size_t n;
// [...]
n = min_t(loff_t, len, isize - *ppos);
n = splice_folio_into_pipe(pipe, folio, *ppos, n); // [4]
len -= n;
total_spliced += n;
*ppos += n;
in->f_ra.prev_pos = *ppos;
if (pipe_full(pipe->head, pipe->tail, pipe->max_usage))
goto out;
}
// [...]
} while (len);
// [...]
}
splice_folio_into_pipe() 則會在把 folio 內的 subpages [5] 複製到 pipe object 且更新 refcnt [6],也就代表此 pipe object 與 file object 共用 struct page。這些包含 file content 並且定期與 device sync 的 page 又稱作 cached file page。
size_t splice_folio_into_pipe(struct pipe_inode_info *pipe,
struct folio *folio, loff_t fpos, size_t size)
{
struct page *page;
size_t spliced = 0, offset = offset_in_folio(folio, fpos);
page = folio_page(folio, offset / PAGE_SIZE);
size = min(size, folio_size(folio) - offset);
offset %= PAGE_SIZE;
while (spliced < size &&
!pipe_full(pipe->head, pipe->tail, pipe->max_usage)) {
struct pipe_buffer *buf = pipe_head_buf(pipe);
size_t part = min_t(size_t, PAGE_SIZE - offset, size - spliced);
*buf = (struct pipe_buffer) {
.ops = &page_cache_pipe_buf_ops,
.page = page, // [5]
.offset = offset,
.len = part,
};
folio_get(folio); // [6]
pipe->head++;
page++;
spliced += part;
offset = 0;
}
// [...]
}
Case4
Input file 為 normal file,output file 為 pipe file,splice 不支援這種處理,因此會回傳錯誤 -EINVAL。
Pipe Release
在釋放一個 pipe file object 時,會呼叫 fops 的 .release handle,也就是 function pipe_release()。
const struct file_operations pipefifo_fops = {
// [...]
.release = pipe_release,
};
pipe_release() 先更新 metadata readers / writers,而後呼叫 put_pipe_info()。
static int
pipe_release(struct inode *inode, struct file *file)
{
struct pipe_inode_info *pipe = file->private_data;
__pipe_lock(pipe);
if (file->f_mode & FMODE_READ)
pipe->readers--;
if (file->f_mode & FMODE_WRITE)
pipe->writers--;
// [...]
__pipe_unlock(pipe);
put_pipe_info(inode, pipe);
return 0;
}
因為一組 pipe 有兩個 file object,需要等到 pipe->files == 0 時才能確保沒有 file ref 到該 struct pipe_inode_info object [1],此時就可以呼叫 free_pipe_info() 釋放 object [2]。
static void put_pipe_info(struct inode *inode, struct pipe_inode_info *pipe)
{
int kill = 0;
spin_lock(&inode->i_lock);
if (!--pipe->files) { // [1]
inode->i_pipe = NULL;
kill = 1;
}
spin_unlock(&inode->i_lock);
if (kill)
free_pipe_info(pipe); // [2]
}
- [1]
pipe->files初始值會是 2,也就是 read / write file 各一個
pipefifo_fops.open 指向 fifo_open(),該 function 會在 sys_open 一個 pipe 時會被呼叫,並且根據 inode 是否存在來更新 files、reader 與 writer count,可以參考下方範例程式碼來觸發 fifo_open()。
int main()
{
int fds[2];
pipe(fds);
open("/proc/self/fd/3", O_RDONLY); // trigger
return 0;
}
free_pipe_info() 會遍歷每個 pipe_buffer object [3],若 buf->ops != NULL 就呼叫 pipe_buf_release() 釋放 pipe_buffer 的 data page [4]。最後釋放整個 array 以及 pipe object。
void free_pipe_info(struct pipe_inode_info *pipe)
{
unsigned int i;
// [...]
for (i = 0; i < pipe->ring_size; i++) { // [3]
struct pipe_buffer *buf = pipe->bufs + i;
if (buf->ops)
pipe_buf_release(pipe, buf); // [4]
}
// [...]
kfree(pipe->bufs);
kfree(pipe);
}
- [4]
splice_pipe_to_pipe()在把 input pipe_buffer 的struct page *給 output pipe_buffer 時會把buf->ops更新成 NULL
下方為 pipe object 彼此的關聯圖:
2. Dirty Pipe
Dirty Pipe (CVE-2022-0847) 是一個 kernel 在初始化 struct pipe_buffer 時忘記初始化 member flags 的漏洞。當 flags 的殘留值剛好是 PIPE_BUF_FLAG_CAN_MERGE 時,pipe 就能在特定情境下對一個唯讀檔案的 cached file page 做寫入。Linux 團隊在 v5.16.11 修復了這個漏洞,patch 的方式也很直觀,多初始化 flags 成 0。接下來程式碼會以 fixed 的版本 v5.16.11 來做分析該如何觸發漏洞。
diff --git a/lib/iov_iter.c b/lib/iov_iter.c
index b0e0acdf96c1..6dd5330f7a99 100644
--- a/lib/iov_iter.c
+++ b/lib/iov_iter.c
@@ -414,6 +414,7 @@ static size_t copy_page_to_iter_pipe(struct page *page, size_t offset, size_t by
return 0;
buf->ops = &page_cache_pipe_buf_ops;
+ buf->flags = 0;
get_page(page);
buf->page = page;
buf->offset = offset;
@@ -577,6 +578,7 @@ static size_t push_pipe(struct iov_iter *i, size_t size,
break;
buf->ops = &default_pipe_buf_ops;
+ buf->flags = 0;
buf->page = page;
buf->offset = 0;
buf->len = min_t(ssize_t, left, PAGE_SIZE);
根據 section “1. Introduction”,我們已經知道:
- 寫入 pipe 的操作會需要初始化 pipe_buffer 來儲存資料
- 讀取 pipe 的操作間接釋放了不再使用的 pipe_buffer
pipe->head為從哪邊開始寫pipe->tail是從哪邊開始讀
有漏洞的兩個 function 都有初始化 pipe_buffer 的操作,所以可以推測出與寫資料到 pipe 的行為有關。
那如果 flags 中包含 PIPE_BUF_FLAG_CAN_MERGE,會對檔案有什麼影響?在對一個 pipe 做寫入時會觸發 pipe_write(),該 function 是唯一會根據 buf->flags 是否包含 PIPE_BUF_FLAG_CAN_MERGE 執行不同程式碼的地方 [1]。當 pipe_write() 發現目標 pipe 有正在使用的 pipe_buffer 且裡面有資料 [2],就會嘗試使用上一個 pipe_buffer [3]。
static ssize_t
pipe_write(struct kiocb *iocb, struct iov_iter *from)
{
size_t total_len = iov_iter_count(from);
// [...]
was_empty = pipe_empty(head, pipe->tail);
chars = total_len & (PAGE_SIZE-1);
if (chars && !was_empty) { // [2]
unsigned int mask = pipe->ring_size - 1;
struct pipe_buffer *buf = &pipe->bufs[(head - 1) & mask]; // [3]
int offset = buf->offset + buf->len;
if ((buf->flags & PIPE_BUF_FLAG_CAN_MERGE) && // [1]
offset + chars <= PAGE_SIZE) {
ret = pipe_buf_confirm(pipe, buf);
ret = copy_page_from_iter(buf->page, offset, chars, from);
buf->len += ret;
if (!iov_iter_count(from))
goto out;
}
}
// [...]
}
再來我們要找出哪一種寫入操作會呼叫到 copy_page_to_iter_pipe() 或是 push_pipe()。
舊版 splice 的 Case3 與新版不同,最後會由 do_splice_to() 來呼叫 f_op->splice_read(),並且除了幾個特別的 fs 外,該 handler 只會指向 function generic_file_splice_read()。
static long do_splice_to(struct file *in, loff_t *ppos,
struct pipe_inode_info *pipe, size_t len,
unsigned int flags)
{
// [...]
return in->f_op->splice_read(in, ppos, pipe, len, flags);
}
generic_file_splice_read() 初始化 struct kiocb 後呼叫 call_read_iter(),而 call_read_iter() 是一個 wrapper function,會呼叫 file->f_op->read_iter()。
ssize_t generic_file_splice_read(struct file *in, loff_t *ppos,
struct pipe_inode_info *pipe, size_t len,
unsigned int flags)
{
struct iov_iter to;
struct kiocb kiocb;
unsigned int i_head;
int ret;
iov_iter_pipe(&to, READ, pipe, len);
i_head = to.head;
init_sync_kiocb(&kiocb, in);
kiocb.ki_pos = *ppos;
ret = call_read_iter(in, &kiocb, &to);
// [...]
return ret;
}
以 ext4 的 struct file_operations 為例,ext4_file_operations.read_iter 為 ext4_file_read_iter(),且該 function 會間接呼叫到 filemap_read()。Function filemap_read() 的行為類似於新版的 function filemap_splice_read(),先初始化 page vector [1] (對應到新版的 folio),並為其建立 pages [2],之後呼叫 copy_page_to_iter() 將 file page data 複製給 pipe object [3]。
ssize_t filemap_read(struct kiocb *iocb, struct iov_iter *iter,
ssize_t already_read)
{
struct file *filp = iocb->ki_filp;
struct file_ra_state *ra = &filp->f_ra;
struct address_space *mapping = filp->f_mapping;
struct inode *inode = mapping->host;
struct pagevec pvec;
int i, error = 0;
bool writably_mapped;
loff_t isize, end_offset;
iov_iter_truncate(iter, inode->i_sb->s_maxbytes);
pagevec_init(&pvec); // [1]
do {
// [...]
error = filemap_get_pages(iocb, iter, &pvec); // [2]
isize = i_size_read(inode);
end_offset = min_t(loff_t, isize, iocb->ki_pos + iter->count);
// [...]
for (i = 0; i < pagevec_count(&pvec); i++) {
struct page *page = pvec.pages[i];
size_t page_size = thp_size(page);
size_t offset = iocb->ki_pos & (page_size - 1);
size_t bytes = min_t(loff_t, end_offset - iocb->ki_pos,
page_size - offset);
size_t copied;
// [...]
copied = copy_page_to_iter(page, offset, bytes, iter); // [3]
// [...]
}
} while (iov_iter_count(iter) && iocb->ki_pos < isize && !error);
// [...]
}
copy_page_to_iter() 會執行到 __copy_page_to_iter(),判斷 IO vector iterator object struct iov_iter 的 type 為 pipe 時會由 copy_page_to_iter_pipe() 處理。能看到 copy_page_to_iter_pipe() 會初始化 pipe_buffer,包含初始化 flags [4] 以及取得 cached page [5],而 Dirty Pipe 的漏洞成因就是沒有執行 [4] 初始化 flags。
static size_t copy_page_to_iter_pipe(struct page *page, size_t offset, size_t bytes,
struct iov_iter *i)
{
struct pipe_inode_info *pipe = i->pipe;
struct pipe_buffer *buf;
unsigned int p_tail = pipe->tail;
unsigned int p_mask = pipe->ring_size - 1;
unsigned int i_head = i->head;
size_t off;
// [...]
off = i->iov_offset;
buf = &pipe->bufs[i_head & p_mask];
// [...]
buf->ops = &page_cache_pipe_buf_ops;
buf->flags = 0; // [4]
get_page(page);
buf->page = page; // [5]
// [...]
}
根據上面分析,我們可以根據以下步驟構造出可以寫入 RO file 如 /etc/passwd 的 pipe object:
- 建立一個 pipe object,並填滿所有資料,這樣每個
pipe_buffer->flags都會被設置PIPE_BUF_FLAG_CAN_MERGE - 把資料讀出來,雖然 data page 會被釋放掉,但是 flags 不會被清空
- 開啟 RO file 如 /etc/passwd 並作為 syscall splice 的參數 input file,新建立的 pipe_buffer 其 flags 會因為沒初始化仍是
PIPE_BUF_FLAG_CAN_MERGE - 向 pipe 寫入資料,此時
pipe_write()會以為是可以被 merge 的struct page,而對 cached file page 寫入資料,但其實是寫到 RO file 內
當構造完利用情境時,struct pipe_buffer 與 struct file 之間的結構關係圖會長得像下方圖示:
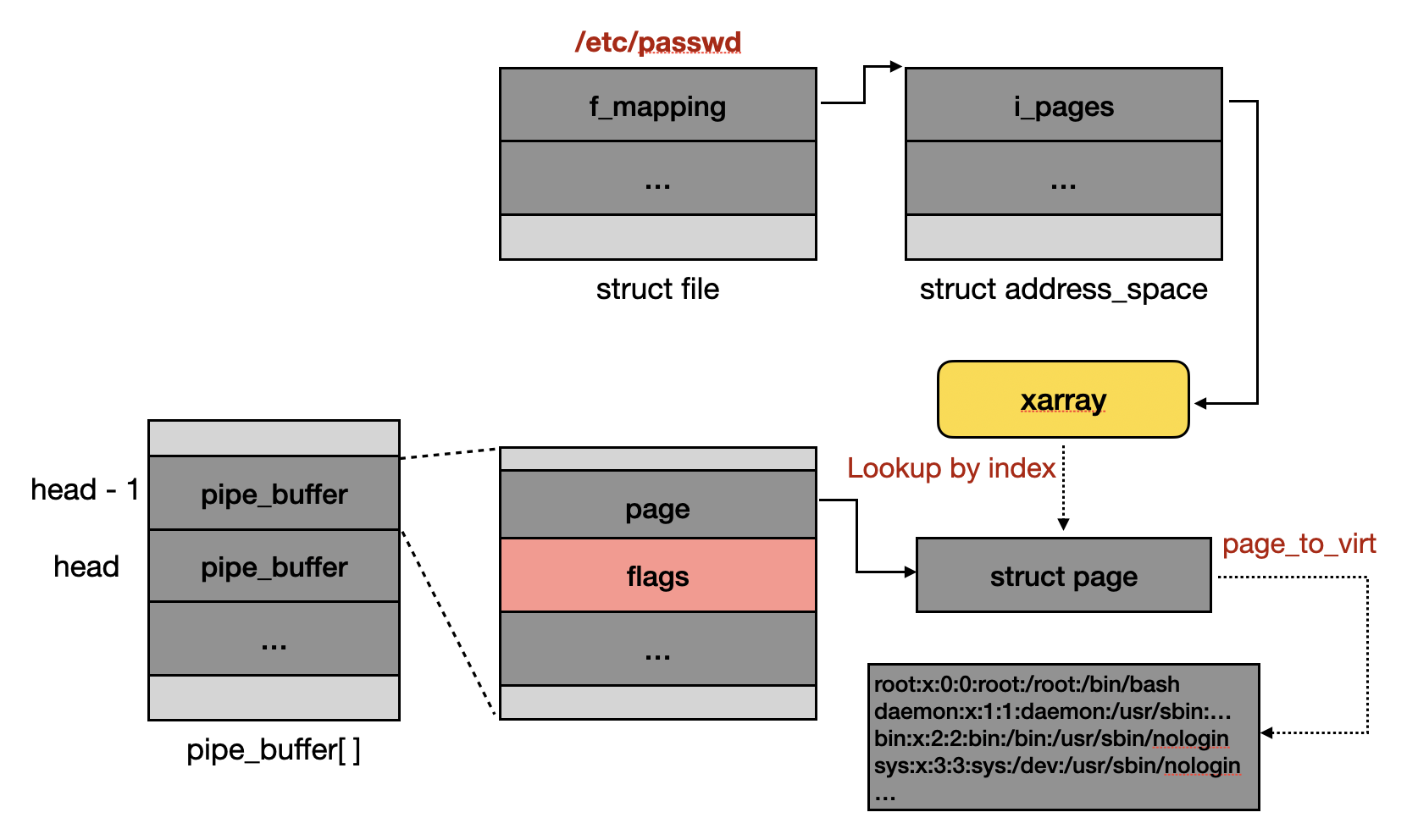
其中 struct page 到 virtual address 的轉換方式如下:
unsigned long page_to_virt(struct page *page) {
unsigned int pfn = ((void *)page - vmemmap_base) / sizeof(struct page) /* 0x40 */;
return (pfn << 12) + page_offset_base;
}
vmemmap_base 在 KASLR 關閉的情況下會在 0xffffea0000000000,而 page_offset_base 則是 0xffff888000000000,可以參考官方文件。
# [...]
ffff888000000000 | -119.5 TB | ffffc87fffffffff | 64 TB | direct mapping of all physical memory (page_offset_base)
# [...]
ffffea0000000000 | -22 TB | ffffeaffffffffff | 1 TB | virtual memory map (vmemmap_base)
3. Pipe-Primitive
研究員 veritas501 基於該漏洞的利用方式,提出一種在 “kmalloc-cg-1k” 底下 UAF 或 OOB write 的利用方式,也就是想辦法設置目標 pipe_buffer 的 flags 成 PIPE_BUF_FLAG_CAN_MERGE。
pipe_buffer->flags |= PIPE_BUF_FLAG_CAN_MERGE;
但此利用方式有一個限制:在 OOB write 到 struct pipe_buffer -> flags 之前會先蓋到兩個 pointer member,其中 struct page *page 會指向我們要寫的位置,
struct pipe_buffer {
struct page *page;
unsigned int offset, len;
const struct pipe_buf_operations *ops;
unsigned int flags;
unsigned long private;
};
所以 OOB write 或 UAF primitive 不能蓋到前面 8 bytes,否則沒有辦法利用成功。
4. PageJack
BHUSA 2024 中發表了一個新的 pipe_buffer 利用方式,稱作 PageJack。其原理解決了 (?) Pipe-Primitive 利用方式的缺點,一樣是蓋 struct pipe_buffer,但該手法用的是 partial overwrite struct page *,使得兩個 page object 重疊,藉此構造出 struct page UAF。
因為 struct page 是由 buddy system 來 maintain,不局限在 slab-cache 的限制,因此只要能透過 spray 大量 kernel object,讓具有 privilege 的 object (struct cred or struct file) 拿跟 UAF 同一塊 page,就可以直接改 privilege member 做 data-only attack。