Linux RCU Internal
The Linux kernel implements the RCU mechanism to reduce the need for locks, allowing developers to simply refer to the documentation and call RCU APIs for lock-free performance gains. This raises an intriguing question: How can merely invoking RCU APIs yield such powerful results, and how does the Linux kernel’s RCU actually work?
In this article, I will first provide a brief introduction to RCU. Then, I will reference the official documentation to explain how to use the RCU APIs. Finally, I will delve into the implementation.
1. RCU Overview
Most are generated by ChatGPT
RCU (Read-Copy Update) is a synchronization mechanism in the Linux kernel designed for efficient read operations in multi-processor environments, allowing updates without degrading read performance. The primary goal of RCU is to address data synchronization challenges in multi-threaded scenarios, particularly in situations where frequent reads and infrequent updates occur. RCU provides a more efficient solution compared to traditional locking mechanisms in these cases.
Core Concepts
- Read-Write Separation:
- RCU separates read and update operations. Read operations are lock-free, allowing multiple threads to execute them concurrently without waiting, thereby significantly improving read efficiency.
- Update operations are slightly more complex and typically involve three steps: creating new data (copy), switching the pointer to the new data (update), and deferring the deletion of old data (defer delete).
- Memory Consistency:
- When read and update operations occur simultaneously, RCU ensures that the data seen by read operations is stable and usable, preventing reads from accessing data that is being modified or deleted.
- Grace Period:
- After data is updated, RCU does not immediately delete the old data. Instead, it waits for all threads potentially reading the data to complete their read operations. This waiting period is known as the “grace period.”
- Only after all read operations have finished is the old data truly released.
Because readers are allowed to access old objects under the RCU mechanism, the code must ensure that no issues arise when a reader accesses outdated data.
2. How to Use RCU API
The official documentation, “What is RCU? – ‘Read, Copy, Update’”, provides a detailed description of the RCU mechanism and its usage. This section will explain the APIs and the example code provided in the documentation.
Although the documentation mentions there are five core RCU APIs, I think it would be easier to understand if we categorize them into the following two groups:
- (reader)
rcu_read_lock()/rcu_read_unlock() - (writer)
synchronize_rcu()/call_rcu()
The first group of RCU APIs is used by the read-side to mark the critical section where the reader accesses the shared data. The second group of RCU APIs is used by the write-side and will only proceed after all readers have exited the critical section.
The write-side RCU APIs can further be divided into two modes: synchronous and asynchronous. In the synchronous mode, writers must wait for all existing readers to finish before making changes visible. In contrast, the asynchronous mode allows writers to proceed without waiting for readers to complete their operations.
Synchronous
In the example code, we assume that multiple CPUs may concurrently access the global object gbl_foo.
struct foo {
int a;
char b;
long c;
};
struct foo __rcu *gbl_foo;
For the read-side (reader), to ensure safe data access, simply invoke rcu_read_lock() [1] before accessing the data, and then call rcu_read_unlock() [2] after finishing, to indicate that the reader has exited the critical section.
int foo_get_a(void)
{
int retval;
rcu_read_lock(); // [1]
retval = rcu_dereference(gbl_foo)->a;
rcu_read_unlock(); // [2]
return retval;
}
The write-side (writer) operations are a little bit complex. When updating the data, the writer must use a lock [3, 4] because RCU cannot handle concurrent writers. After updating, the writer calls synchronize_rcu() [5] to wait until all readers have exited their critical sections, and then it can safely release the old object.
DEFINE_SPINLOCK(foo_mutex);
void foo_update_a(int new_a)
{
struct foo *new_fp;
struct foo *old_fp;
new_fp = kmalloc(sizeof(*new_fp), GFP_KERNEL);
spin_lock(&foo_mutex); // [3]
old_fp = rcu_dereference_protected(gbl_foo, lockdep_is_held(&foo_mutex));
*new_fp = *old_fp;
new_fp->a = new_a;
rcu_assign_pointer(gbl_foo, new_fp);
spin_unlock(&foo_mutex); // [4]
synchronize_rcu(); // [5]
kfree(old_fp);
}
Asynchronous
In the previous scenario, when synchronize_rcu() is called, the writer needs to wait for all readers to finish before proceeding, which can impact performance in some situation.
To address it, the asynchronous RCU delegates the task of waiting for readers and releasing resources to other kthread workers. The writer only needs to define a callback function for resource cleanup and register the RCU callback using the call_rcu() API. This allows the writer to continue without being blocked.
struct foo {
int a;
char b;
long c;
+ struct rcu_head rcu;
};
- synchronize_rcu();
- kfree(old_fp);
+ call_rcu(&old_fp->rcu, foo_reclaim);
The RCU callback is invoked once all readers have exited the critical section, allowing the release of old objects.
void foo_reclaim(struct rcu_head *rp)
{
struct foo *fp = container_of(rp, struct foo, rcu);
kfree(fp);
}
3. The Veil of Linux RCU
Why a few simple API calls are sufficient to safely access data under the protection of the RCU mechanism? How exactly is the RCU mechanism implemented in the Linux kernel? In this section, we will delve into the source code to uncover the mysteries behind the Linux RCU mechanism.
The entire RCU implementation can be devided into five components, which are as follows:
- Read-side
- Write-side
- Timer interrupt
- GP kthread “rcu_preempt”
- Preemptive RCU
The relationships between some of the core RCU objects and their fields are as follows:
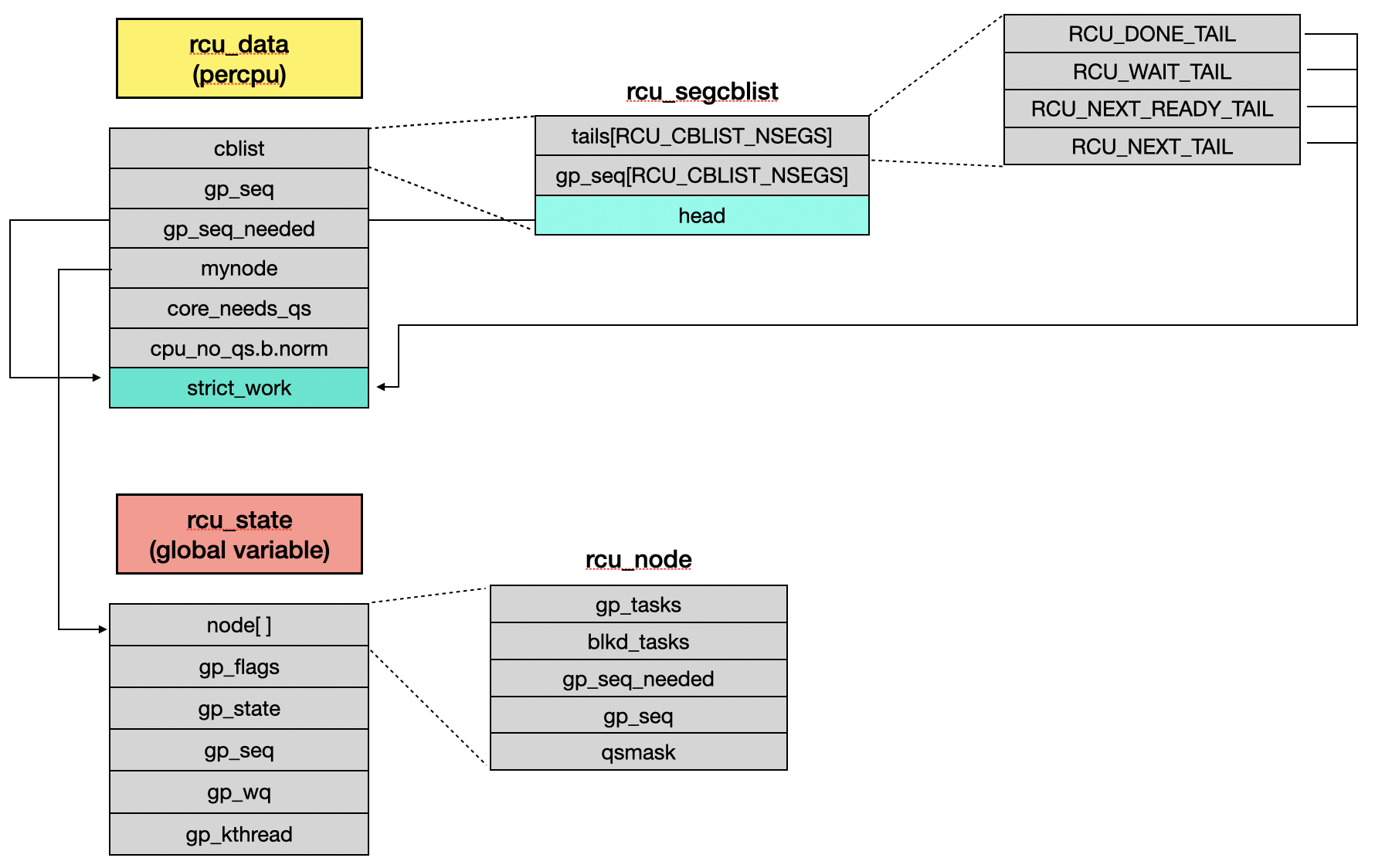
3.1 Read-side
Read Lock
The read-side calls rcu_read_lock() to ensure that data is not released during the read operation.
// include/linux/rcupdate.h
static __always_inline void rcu_read_lock(void)
{
__rcu_read_lock();
// [...]
}
There are two __rcu_read_lock() definitions in the kernel. The general version, defined in rcupdate.h, calls preempt_disable() to prevent the task from being preempted.
// include/linux/rcupdate.h
static inline void __rcu_read_lock(void)
{
preempt_disable();
}
// include/linux/preempt.h
#define preempt_disable() \
do \
{ \
preempt_count_inc(); \
barrier(); \
} while (0)
In Tree RCU, __rcu_read_lock() invokes rcu_preempt_read_enter() to increment current->rcu_read_lock_nesting by one.
// kernel/rcu/tree_plugin.h
void __rcu_read_lock(void)
{
rcu_preempt_read_enter();
barrier();
}
// kernel/rcu/tree_plugin.h
static void rcu_preempt_read_enter(void)
{
WRITE_ONCE(current->rcu_read_lock_nesting, READ_ONCE(current->rcu_read_lock_nesting) + 1);
}
The difference between the two is that: general RCU does not support preemption, whereas the Tree RCU implementation does (CONFIG_PREEMPT_RCU=y).
Read Unlock
The reader will call rcu_read_unlock() to release the lock after completing the read operation.
// include/linux/rcupdate.h
static inline void rcu_read_unlock(void)
{
// [...]
__rcu_read_unlock();
}
In general RCU, __rcu_read_unlock() calls preempt_enable() to re-enable preemption.
// include/linux/rcupdate.h
static inline void __rcu_read_unlock(void)
{
preempt_enable();
}
In Tree RCU, __rcu_read_unlock() invokes rcu_preempt_read_exit() to decrement current->rcu_read_lock_nesting by one, and if special handling is required, it executes rcu_read_unlock_special().
// kernel/rcu/tree_plugin.h
void __rcu_read_unlock(void)
{
// [...]
struct task_struct *t = current;
if (rcu_preempt_read_exit() == 0) {
if (unlikely(READ_ONCE(t->rcu_read_unlock_special.s)))
rcu_read_unlock_special(t);
}
// [...]
}
// kernel/rcu/tree_plugin.h
static int rcu_preempt_read_exit(void)
{
int ret = READ_ONCE(current->rcu_read_lock_nesting) - 1;
WRITE_ONCE(current->rcu_read_lock_nesting, ret);
return ret;
}
3.2 Write-side
Synchronous Mode
After a writer updates the data, it will call synchronize_rcu() to wait for readers holding the old data to finish executing.
// kernel/rcu/tree.c
void synchronize_rcu(void)
{
// [...]
if (!rcu_blocking_is_gp()) { // [1]
if (rcu_gp_is_expedited())
synchronize_rcu_expedited();
else
wait_rcu_gp(call_rcu_hurry); // [2]
return;
}
// [...]
}
Once the kernel is initialized, the RCU scheduler state (rcu_scheduler_active) remains running (RCU_SCHEDULER_RUNNING), causing rcu_blocking_is_gp() to return false [1]. In most cases, the RCU grace period not need be expedited, so wait_rcu_gp() will be executed [2].
// kernel/rcu/tree.c
static int rcu_blocking_is_gp(void)
{
if (rcu_scheduler_active != RCU_SCHEDULER_INACTIVE) {
// [...]
return false;
}
return true;
}
The function wait_rcu_gp() calls __wait_rcu_gp(), and when certain conditions are met, it executes the callbacks of the elements in the crcu_array[] parameter [3]. After that, the writer will be blocked while waiting for the state change of the completion object [4].
// include/linux/rcupdate_wait.h
#define wait_rcu_gp(...) _wait_rcu_gp(false, TASK_UNINTERRUPTIBLE, __VA_ARGS__)
#define _wait_rcu_gp(checktiny, state, ...) \
do \
{ \
call_rcu_func_t __crcu_array[] = {__VA_ARGS__}; \
struct rcu_synchronize __rs_array[ARRAY_SIZE(__crcu_array)]; \
__wait_rcu_gp(checktiny, state, ARRAY_SIZE(__crcu_array), __crcu_array, __rs_array); \
} while (0)
// kernel/rcu/update.c
void __wait_rcu_gp(bool checktiny, int n, call_rcu_func_t *crcu_array,
struct rcu_synchronize *rs_array)
{
int i;
int j;
for (i = 0; i < n; i++) {
// [...]
for (j = 0; j < i; j++)
if (crcu_array[j] == crcu_array[i])
break;
if (j == i) {
init_rcu_head_on_stack(&rs_array[i].head);
init_completion(&rs_array[i].completion);
(crcu_array[i])(&rs_array[i].head, wakeme_after_rcu); // [3]
}
}
for (i = 0; i < n; i++) {
// [...]
for (j = 0; j < i; j++)
if (crcu_array[j] == crcu_array[i])
break;
if (j == i) {
wait_for_completion(&rs_array[i].completion); // [4]
destroy_rcu_head_on_stack(&rs_array[i].head);
}
}
}
Then call_rcu_hurry() calls __call_rcu_common() to enqueue the RCU callback function wakeme_after_rcu().
// kernel/rcu/tree.c
void call_rcu_hurry(struct rcu_head *head, rcu_callback_t func)
{
__call_rcu_common(head, func, false);
}
The RCU callback function wakeme_after_rcu() simply marks the rcu->completion object as complete. Once marked as complete, the blocked __wait_rcu_gp() will resume execution.
// kernel/rcu/update.c
void wakeme_after_rcu(struct rcu_head *head)
{
struct rcu_synchronize *rcu;
rcu = container_of(head, struct rcu_synchronize, head);
complete(&rcu->completion);
}
Function __call_rcu_common() initializes the RCU linked list object [5] and calls call_rcu_core() [6].
// kernel/rcu/tree.c
static void
__call_rcu_common(struct rcu_head *head, rcu_callback_t func, bool lazy_in)
{
unsigned long flags;
bool lazy;
struct rcu_data *rdp;
// [...]
head->func = func; // [5]
head->next = NULL;
rdp = this_cpu_ptr(&rcu_data);
// [...]
call_rcu_core(rdp, head, func, flags); // [6]
// [...]
}
call_rcu_core() finally enqueues the RCU callback object (struct rcu_data) into the RCU_NEXT_TAIL list of struct rcu_segcblist object [7], which is located in the PERCPU data rcu_data.
// kernel/rcu/tree.c
static void call_rcu_core(struct rcu_data *rdp, struct rcu_head *head,
rcu_callback_t func, unsigned long flags)
{
rcutree_enqueue(rdp, head, func);
// [...]
}
// kernel/rcu/tree.c
static void rcutree_enqueue(struct rcu_data *rdp, struct rcu_head *head, rcu_callback_t func)
{
rcu_segcblist_enqueue(&rdp->cblist, head);
}
// kernel/rcu/rcu_segcblist.c
void rcu_segcblist_enqueue(struct rcu_segcblist *rsclp,
struct rcu_head *rhp)
{
rcu_segcblist_inc_len(rsclp);
rcu_segcblist_inc_seglen(rsclp, RCU_NEXT_TAIL);
rhp->next = NULL;
WRITE_ONCE(*rsclp->tails[RCU_NEXT_TAIL], rhp); // [7]
WRITE_ONCE(rsclp->tails[RCU_NEXT_TAIL], &rhp->next);
}
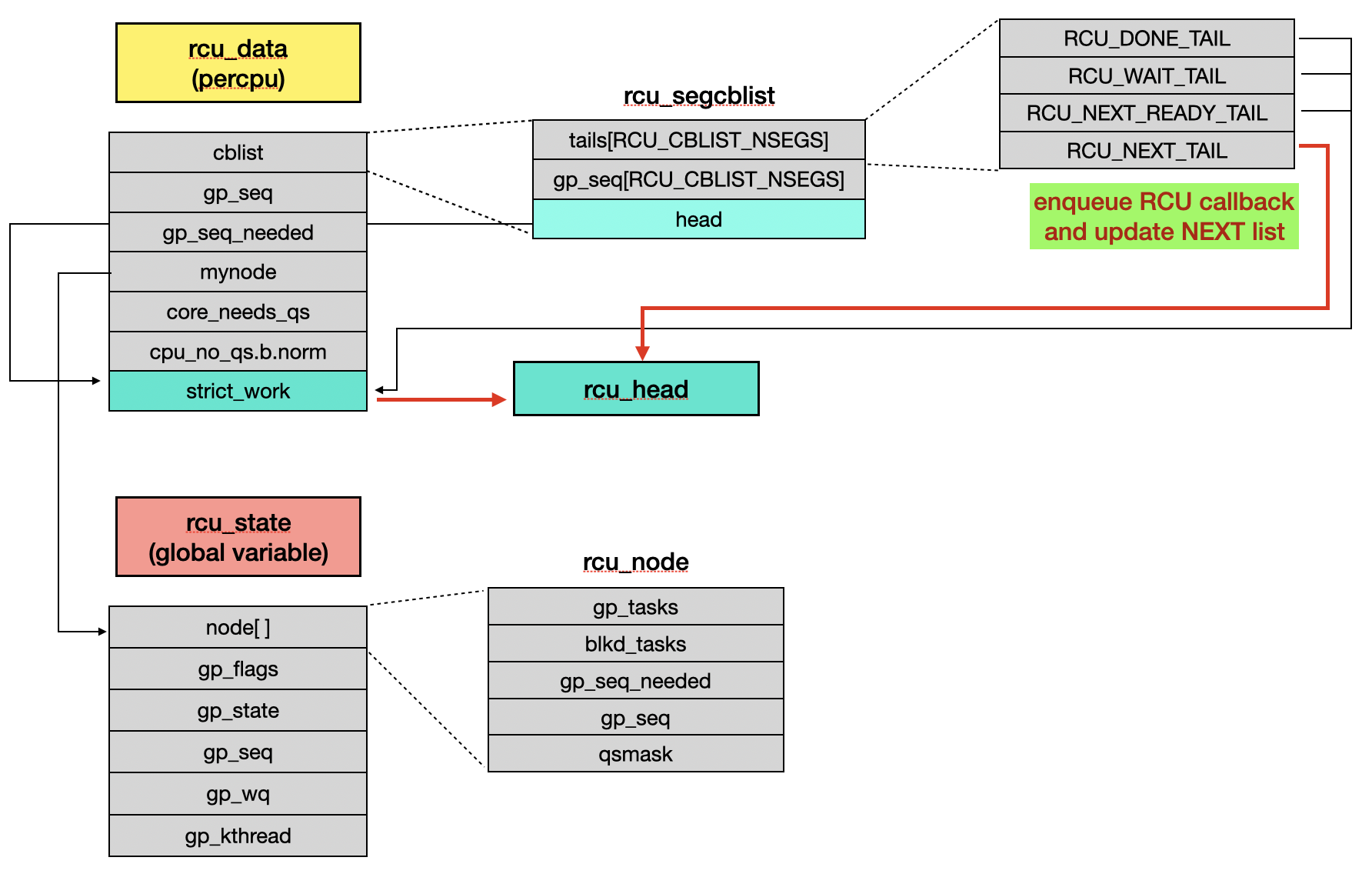
Asynchronous Mode
If the updater does not need to wait for readers to complete before proceeding, it can directly call call_rcu() to release resources asynchronously. Function call_rcu() is a wrapper function for __call_rcu_common(), which was discussed earlier, but the callback function can be customized now.
// kernel/rcu/tree.c
void call_rcu(struct rcu_head *head, rcu_callback_t func)
{
__call_rcu_common(head, func, enable_rcu_lazy);
}
In a nutshell, the difference between synchronize_rcu() and call_rcu() is that the former calls wait_for_completion() to wait for the RCU callback wakeme_after_rcu() to be invoked, while the latter does not require any waiting.
3.3 Timer Interrupt
The invocation of the RCU callback is influenced by both the timer interrupt and the “rcu_preempt” kthread. The simplified flow is as follows:
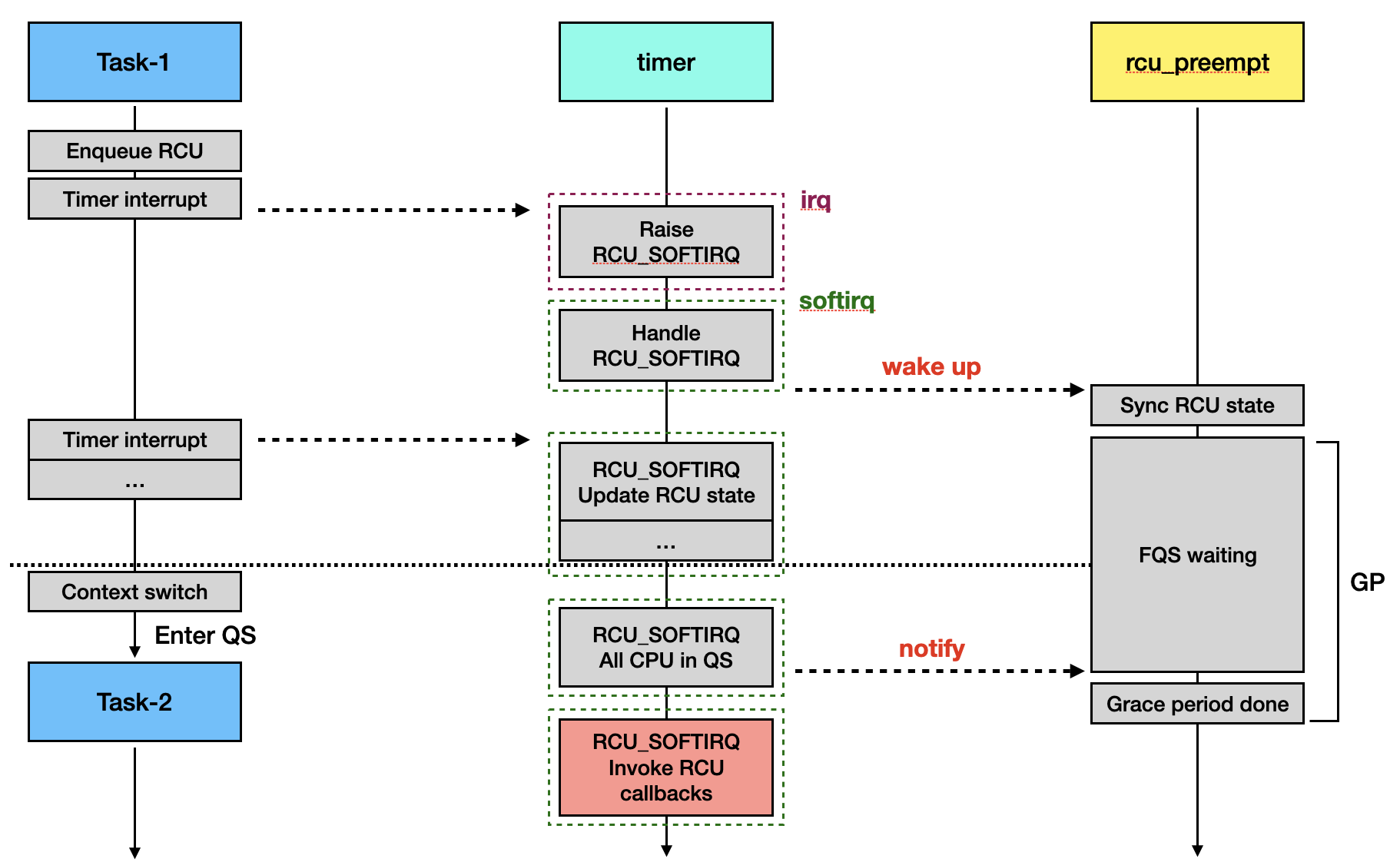
Timer Raise RCU_SOFTIRQ
When a local timer interrupt occurs, it calls asm_sysvec_apic_timer_interrupt(), which then calls sysvec_apic_timer_interrupt().
// arch/x86/include/asm/idtentry.h
DECLARE_IDTENTRY_SYSVEC(LOCAL_TIMER_VECTOR, sysvec_apic_timer_interrupt);
// arch/x86/kernel/apic/apic.c
DEFINE_IDTENTRY_SYSVEC(sysvec_apic_timer_interrupt)
{
// [...]
local_apic_timer_interrupt();
// [...]
}
Below are the macros related to SYSVEC:
// arch/x86/include/asm/idtentry.h
#define DEFINE_IDTENTRY_SYSVEC(func) \
static void __##func(struct pt_regs *regs); \
\
static __always_inline void instr_##func(struct pt_regs *regs) \
{ \
kvm_set_cpu_l1tf_flush_l1d(); \
run_sysvec_on_irqstack_cond(__##func, regs); \
} \
\
__visible noinstr void func(struct pt_regs *regs) \
{ \
irqentry_state_t state = irqentry_enter(regs); \
\
instrumentation_begin(); \
instr_##func(regs); \
instrumentation_end(); \
irqentry_exit(regs, state); \
} \
\
void fred_##func(struct pt_regs *regs) \
{ \
instr_##func(regs); \
} \
\
static noinline void __##func(struct pt_regs *regs)
#define run_sysvec_on_irqstack_cond(func, regs) \
{ \
irq_enter_rcu(); \
func(regs); \
irq_exit_rcu(); \
}
Let’s expand the macros and keep only the essential parts.
__visible noinstr void sysvec_apic_timer_interrupt(struct pt_regs *regs)
{
irqentry_state_t state = irqentry_enter(regs);
instr_sysvec_apic_timer_interrupt(regs);
irqentry_exit(regs, state);
}
static __always_inline void instr_sysvec_apic_timer_interrupt(struct pt_regs *regs)
{
irq_enter_rcu();
__sysvec_apic_timer_interrupt(regs);
irq_exit_rcu();
}
static noinline void __sysvec_apic_timer_interrupt(struct pt_regs *regs)
{
// [...]
local_apic_timer_interrupt();
// [...]
}
We will focus on the execution flow of instr_sysvec_apic_timer_interrupt().
Function irq_enter_rcu() increments the PERCPU data preempt_count by one.
// kernel/softirq.c
void irq_enter_rcu(void)
{
__irq_enter_raw();
// [...]
}
// include/linux/hardirq.h
#define __irq_enter_raw() \
do \
{ \
preempt_count_add(HARDIRQ_OFFSET); \
} while (0)
// kernel/sched/core.c
void preempt_count_add(int val)
{
__preempt_count_add(val);
// [...]
}
// arch/x86/include/asm/preempt.h
static __always_inline void __preempt_count_add(int val)
{
raw_cpu_add_4(pcpu_hot.preempt_count, val);
}
The __sysvec_apic_timer_interrupt() calls the __hrtimer_run_queues() to invoke timer handler tick_sched_handle() internally, which eventually calls rcu_sched_clock_irq().
// kernel/time/hrtimer.c
static void __hrtimer_run_queues(struct hrtimer_cpu_base *cpu_base, ktime_t now,
unsigned long flags, unsigned int active_mask)
{
// [...]
while ((node = timerqueue_getnext(&base->active))) {
struct hrtimer *timer;
timer = container_of(node, struct hrtimer, node);
__run_hrtimer(cpu_base, base, timer, &basenow, flags); // <------------
}
// [...]
}
// kernel/time/hrtimer.c
static void __run_hrtimer(struct hrtimer_cpu_base *cpu_base,
struct hrtimer_clock_base *base,
struct hrtimer *timer, ktime_t *now,
unsigned long flags) __must_hold(&cpu_base->lock)
{
enum hrtimer_restart (*fn)(struct hrtimer *);
// [...]
fn = timer->function;
restart = fn(timer); // <------------
// [...]
}
// kernel/time/tick-sched.c
static enum hrtimer_restart tick_nohz_handler(struct hrtimer *timer)
{
struct pt_regs *regs = get_irq_regs();
// [...]
if (regs)
tick_sched_handle(ts, regs); // <------------
// [...]
}
// kernel/time/tick-sched.c
static void tick_sched_handle(struct tick_sched *ts, struct pt_regs *regs)
{
// [...]
update_process_times(user_mode(regs)); // <------------
// [...]
}
// kernel/time/timer.c
void update_process_times(int user_tick)
{
// [...]
rcu_sched_clock_irq(user_tick); // <------------
// [...]
}
Function rcu_sched_clock_irq() calls invoke_rcu_core() when it detects the RCU is pending, issuing the RCU_SOFTIRQ request.
// kernel/rcu/tree.c
void rcu_sched_clock_irq(int user)
{
// [...]
if (rcu_pending(user))
invoke_rcu_core();
// [...]
}
// kernel/rcu/tree.c
static void invoke_rcu_core(void)
{
// [...]
if (use_softirq)
raise_softirq(RCU_SOFTIRQ);
// [...]
}
rcu_pending() checks whether there is any RCU-related work pending on the current CPU. It returns 1 if there is work to be done, otherwise it returns 0. Those cases for returning 1 are:
- The kernel is currently waiting for QS from this CPU [1].
- The callback list contains entries that are ready to be executed (in the
RCU_DONE_TAILlist) [2]. - This CPU needs a new grace period because of non-empty
RCU_NEXT_READY_TAILlist [3]. - The last grace period has completed or started [4].
// kernel/rcu/tree.c
static int rcu_pending(int user)
{
bool gp_in_progress;
struct rcu_data *rdp = this_cpu_ptr(&rcu_data);
// [...]
gp_in_progress = rcu_gp_in_progress();
if (rdp->core_needs_qs && !rdp->cpu_no_qs.b.norm && gp_in_progress) // [1]
return 1;
if (rcu_segcblist_ready_cbs(&rdp->cblist)) // [2]
return 1;
if (!gp_in_progress && rcu_segcblist_restempty(&rdp->cblist, RCU_NEXT_READY_TAIL)) // [3]
return 1;
if (rcu_seq_current(&rnp->gp_seq) != rdp->gp_seq) // [4]
return 1;
// [...]
}
// kernel/rcu/tree.c
static int rcu_gp_in_progress(void)
{
return rcu_seq_state(rcu_seq_current(&rcu_state.gp_seq));
}
// kernel/rcu/rcu.h
static inline int rcu_seq_state(unsigned long s)
{
return s & RCU_SEQ_STATE_MASK /* 0b11 */;
}
// kernel/rcu/rcu_segcblist.c
bool rcu_segcblist_ready_cbs(struct rcu_segcblist *rsclp)
{
return &rsclp->head != READ_ONCE(rsclp->tails[RCU_DONE_TAIL]);
}
// include/linux/rcu_segcblist.h
#define RCU_DONE_TAIL 0
After call_rcu(), the RCU_NEXT_READY_TAIL list is no longer empty, matching case 3.
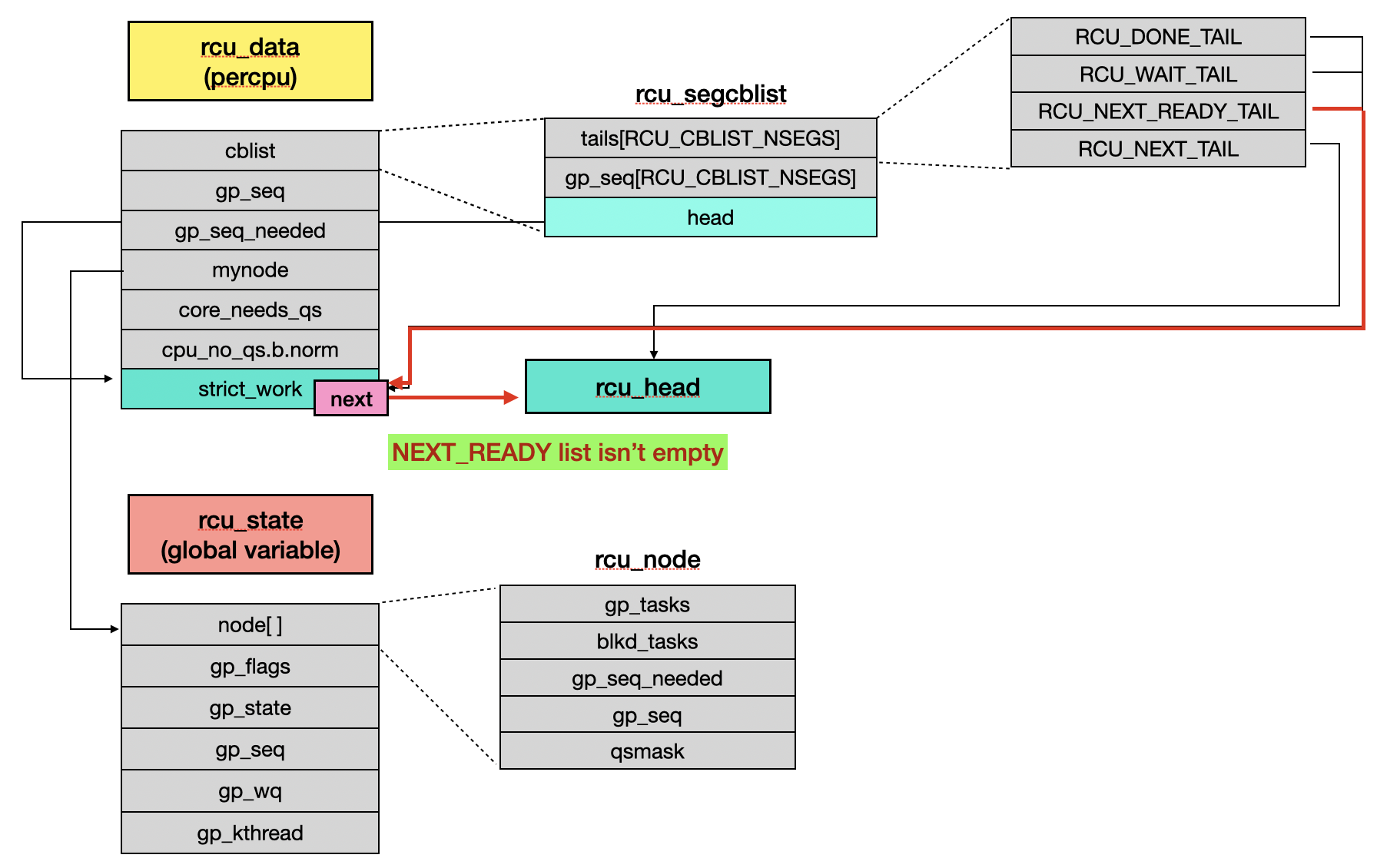
During the kernel booting, rcu_init() is called to initialize RCU. This function registers the action handler for RCU_SOFTIRQ as rcu_core_si(), which just calls rcu_core().
// kernel/rcu/tree.c
void __init rcu_init(void)
{
// [...]
if (use_softirq)
open_softirq(RCU_SOFTIRQ, rcu_core_si);
// [...]
}
// kernel/softirq.c
void open_softirq(int nr, void (*action)(struct softirq_action *))
{
softirq_vec[nr].action = action;
}
// kernel/rcu/tree.c
static void rcu_core_si(struct softirq_action *h)
{
rcu_core();
}
After __sysvec_apic_timer_interrupt() returns, irq_exit_rcu() is executed. It updates the hardirq preempt count [1] and checks for any pending softirqs [2] and, if present, calls invoke_softirq() to handle them.
// kernel/softirq.c
void irq_exit_rcu(void)
{
__irq_exit_rcu();
}
// kernel/softirq.c
static inline void __irq_exit_rcu(void)
{
// [...]
preempt_count_sub(HARDIRQ_OFFSET);
if (!in_interrupt() && local_softirq_pending()) // [2]
invoke_softirq();
// [...]
}
Function invoke_softirq() calls __do_softirq(), which then invokes the corresponding softirq action handler [3].
// kernel/softirq.c
static inline void invoke_softirq(void)
{
if (!force_irqthreads() || !__this_cpu_read(ksoftirqd)) {
__do_softirq();
}
// [...]
}
// kernel/softirq.c
asmlinkage __visible void __softirq_entry __do_softirq(void)
{
struct softirq_action *h;
// [...]
while ((softirq_bit = ffs(pending))) {
// [...]
h->action(h); // [3]
// [...]
}
}
If __do_softirq() detects that the IRQ value is RCU_SOFTIRQ, it will call the action handler rcu_core_si().
RCU_SOFTIRQ handler
When the softirq handler receives RCU_SOFTIRQ, it executes rcu_core() internally. This function first checks the current CPU’s quiescent state (QS) [1], then checks if the RCU grace period has started [2]. If the grace period has not started and the callback list RCU_NEXT_READY_TAIL is not empty, it calls rcu_accelerate_cbs_unlocked() [3]. Finally, rcu_core() checks if there are any callbacks in the list that have completed their grace period, and if so, it invokes rcu_do_batch().
// kernel/rcu/tree.c
static __latent_entropy void rcu_core(void)
{
unsigned long flags;
struct rcu_data *rdp = raw_cpu_ptr(&rcu_data);
struct rcu_node *rnp = rdp->mynode;
// [...]
rcu_check_quiescent_state(rdp); // [1]
// [...]
if (!rcu_gp_in_progress()) { // [2]
if (!rcu_segcblist_restempty(&rdp->cblist, RCU_NEXT_READY_TAIL))
rcu_accelerate_cbs_unlocked(rnp, rdp); // [3]
}
// [...]
if (rcu_segcblist_ready_cbs(&rdp->cblist) && /* ... */) {
rcu_do_batch(rdp); // [4]
// [...]
}
}
static inline bool rcu_segcblist_restempty(struct rcu_segcblist *rsclp, int seg)
{
return !READ_ONCE(*READ_ONCE(rsclp->tails[seg]));
}
rcu_check_quiescent_state() calls rcu_report_qs_rnp() when the CPU reaches a quiescent state (QS) to update the RCU state and QS mask. It also wakes up the GP kthread “rcu_preempt” in the end of function rcu_report_qs_rsp().
// kernel/rcu/tree.c
static void
rcu_check_quiescent_state(struct rcu_data *rdp)
{
// not need QS
if (!rdp->core_needs_qs)
return;
// CPU is waiting for QS
if (rdp->cpu_no_qs.b.norm)
return;
// [...]
rcu_report_qs_rdp(rdp);
}
// kernel/rcu/tree.c
static void
rcu_report_qs_rdp(struct rcu_data *rdp)
{
// [...]
rdp->core_needs_qs = false;
// [...]
rcu_report_qs_rnp(mask, rnp, rnp->gp_seq, flags);
}
static void rcu_report_qs_rnp(unsigned long mask, struct rcu_node *rnp,
unsigned long gps, unsigned long flags)
{
// [...]
WRITE_ONCE(rnp->qsmask, rnp->qsmask & ~mask)
// [...]
rcu_report_qs_rsp(flags);
}
// kernel/rcu/tree.c
static void rcu_report_qs_rsp(unsigned long flags)
{
WRITE_ONCE(rcu_state.gp_flags, rcu_state.gp_flags | RCU_GP_FLAG_FQS);
rcu_gp_kthread_wake();
}
rcu_accelerate_cbs_unlocked() first takes a snapshot of the sequence and compares it with rdp->gp_seq_needed. If the snapshot sequence is greater, it then calls rcu_segcblist_accelerate() [5].
However, on the first call, the snapshot sequence is usually greater, so rcu_segcblist_accelerate() is not executed. Next, it calls rcu_accelerate_cbs() [6] to set the grace period state and wakes up the RCU preempt thread using rcu_gp_kthread_wake() [7].
// kernel/rcu/tree.c
static void rcu_accelerate_cbs_unlocked(struct rcu_node *rnp,
struct rcu_data *rdp)
{
unsigned long c;
bool needwake;
c = rcu_seq_snap(&rcu_state.gp_seq);
if (/* ... */ ULONG_CMP_GE(rdp->gp_seq_needed, c)) {
(void)rcu_segcblist_accelerate(&rdp->cblist, c); // [5]
return;
}
// [...]
needwake = rcu_accelerate_cbs(rnp, rdp); // [6]
if (needwake)
rcu_gp_kthread_wake(); // [7]
}
// kernel/rcu/rcu.h
static inline unsigned long rcu_seq_snap(unsigned long *sp)
{
unsigned long s;
s = (READ_ONCE(*sp) + 2 * RCU_SEQ_STATE_MASK /* 3 */ + 1) & ~RCU_SEQ_STATE_MASK;
return s;
}
rcu_accelerate_cbs() calls rcu_seq_snap() to calculate the sequence number for the end of the grace period [8], which will be gp_seq plus 4. It then calls rcu_segcblist_accelerate() to update callback list.
// kernel/rcu/tree.c
static bool rcu_accelerate_cbs(struct rcu_node *rnp, struct rcu_data *rdp)
{
if (!rcu_segcblist_pend_cbs(&rdp->cblist))
return false;
// [...]
gp_seq_req = rcu_seq_snap(&rcu_state.gp_seq); // [8]
if (rcu_segcblist_accelerate(&rdp->cblist, gp_seq_req))
ret = rcu_start_this_gp(rnp, rdp, gp_seq_req);
// [...]
}
// kernel/rcu/rcu_segcblist.c
bool rcu_segcblist_pend_cbs(struct rcu_segcblist *rsclp)
{
return !rcu_segcblist_restempty(rsclp, RCU_DONE_TAIL);
}
rcu_start_this_gp() uses the previously calculated sequence number to update the grace period sequence number of the RCU node [9] and sets the flag to RCU_GP_FLAG_INIT [10]. The root RCU node (rnp_start) passed to this function is rdp->mynode, which is also &rcu_state.node[0].
// kernel/rcu/tree.c
static bool rcu_start_this_gp(struct rcu_node *rnp_start, struct rcu_data *rdp,
unsigned long gp_seq_req)
{
struct rcu_node *rnp;
// [...]
for (rnp = rnp_start; 1; rnp = rnp->parent) {
// [...]
WRITE_ONCE(rnp->gp_seq_needed, gp_seq_req); // [9]
// [...]
}
// [...]
WRITE_ONCE(rcu_state.gp_flags, rcu_state.gp_flags | RCU_GP_FLAG_INIT); // [10]
// [...]
}
rcu_gp_kthread_wake() updates the wakeup sequence and wakes up the GP kthread “rcu_preempt” [11] to start the grace period.
static void rcu_gp_kthread_wake(void)
{
struct task_struct *t = READ_ONCE(rcu_state.gp_kthread);
// [...]
WRITE_ONCE(rcu_state.gp_wake_time, jiffies);
WRITE_ONCE(rcu_state.gp_wake_seq, READ_ONCE(rcu_state.gp_seq));
swake_up_one_online(&rcu_state.gp_wq); // [11]
}
The RCU objects will be as follows:
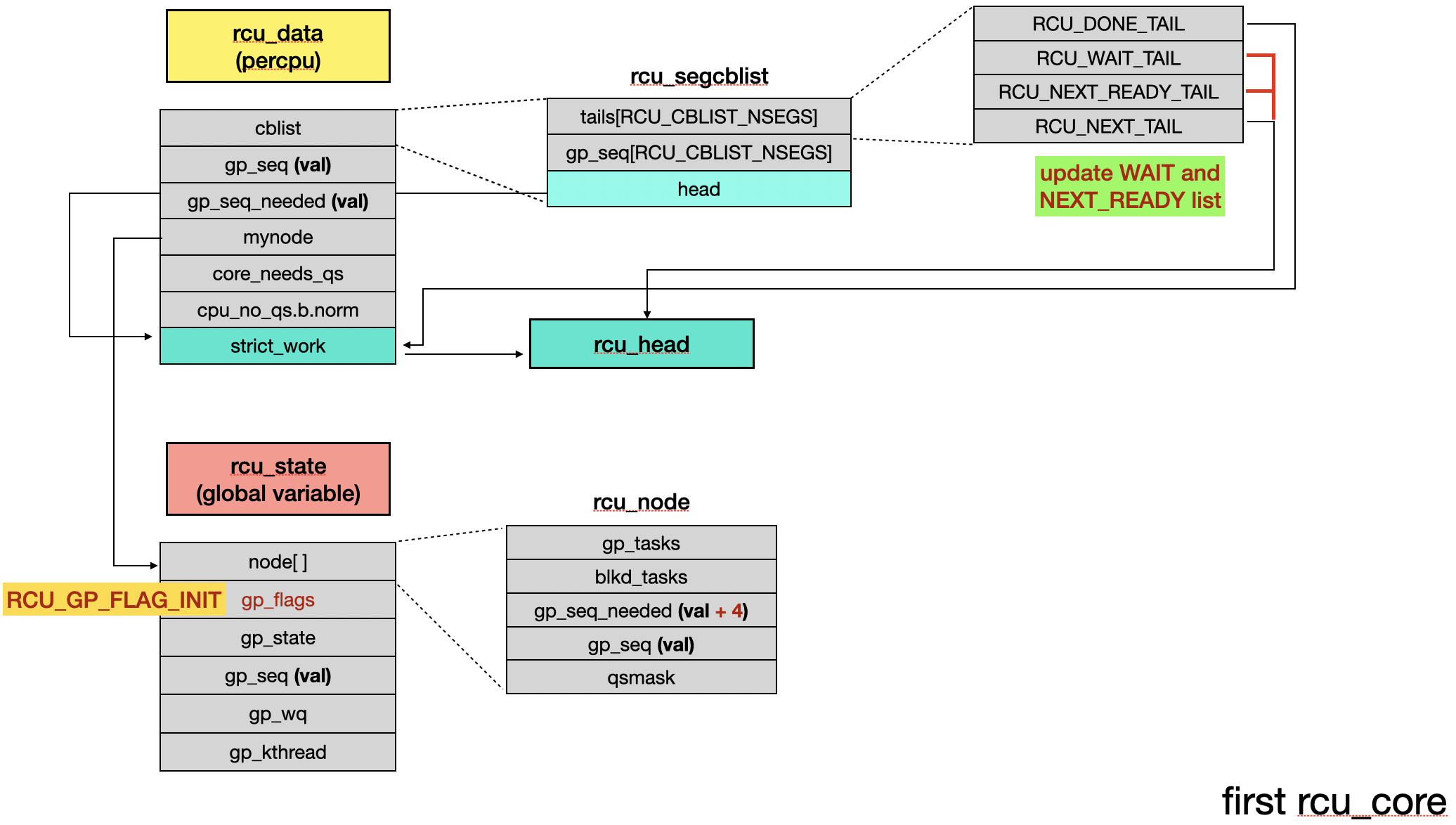
3.4 GP kthread rcu_preempt
The kernel initialization function rcu_spawn_gp_kthread() creates the GP kthread “rcu_preempt”.
// kernel/rcu/tree.c
static int __init rcu_spawn_gp_kthread(void)
{
// [...]
struct task_struct *t;
// [...]
t = kthread_create(rcu_gp_kthread, NULL, "%s", rcu_state.name);
// [...]
}
The rcu_gp_kthread() function initially sets the grace period state to RCU_GP_WAIT_GPS [1] and waits for the grace period flag to be set to RCU_GP_FLAG_INIT [2]. If the flag is successfully set, the gp state is updated to RCU_GP_DONE_GPS, indicating that a grace period request has been received. It then executes rcu_gp_init() to start the grace period [3].
// kernel/rcu/tree.c
static int __noreturn rcu_gp_kthread(void *unused)
{
// [...]
for (;;) {
for (;;) {
WRITE_ONCE(rcu_state.gp_state, RCU_GP_WAIT_GPS); // [1]
swait_event_idle_exclusive(rcu_state.gp_wq, // [2]
READ_ONCE(rcu_state.gp_flags) &
RCU_GP_FLAG_INIT);
WRITE_ONCE(rcu_state.gp_state, RCU_GP_DONE_GPS);
if (rcu_gp_init()) // [3]
break;
// [...]
}
// [...]
}
}
rcu_gp_init() starts by incrementing gp_seq and modifying the gp state. It then calls rcu_preempt_check_blocked_tasks() [4] to check for any blocked tasks. If there are blocked tasks, they are moved to another list, rnp->gp_tasks.
Next, the qsmask is initialized to its initial value [5]. Each bit in this 8-byte field corresponds to the QS status of a CPU. If a bit is set, it indicates that the corresponding CPU has not yet reached a quiescent state.
Subsequently, when the current RCU tree node being accessed is the root node, it executes __note_gp_changes() to sync grace period information to the PERCPU data rcu_data.
// kernel/rcu/tree.c
static noinline_for_stack bool rcu_gp_init(void)
{
unsigned long flags;
unsigned long oldmask;
unsigned long mask;
struct rcu_data *rdp;
struct rcu_node *rnp = rcu_get_root(); // &rcu_state.node[0]
// [...]
rcu_seq_start(&rcu_state.gp_seq);
WRITE_ONCE(rcu_state.gp_state, RCU_GP_INIT);
// [...]
rcu_for_each_node_breadth_first(rnp) {
// [...]
rcu_preempt_check_blocked_tasks(rnp); // [4]
rnp->qsmask = rnp->qsmaskinit; // [5]
WRITE_ONCE(rnp->gp_seq, rcu_state.gp_seq);
if (rnp == rdp->mynode)
(void)__note_gp_changes(rnp, rdp);
// [...]
}
WRITE_ONCE(rcu_state.gp_state, RCU_GP_INIT);
return true;
}
// kernel/rcu/tree_plugin.h
static void rcu_preempt_check_blocked_tasks(struct rcu_node *rnp)
{
struct task_struct *t;
if (rcu_preempt_has_tasks(rnp) &&
(rnp->qsmaskinit || rnp->wait_blkd_tasks)) {
WRITE_ONCE(rnp->gp_tasks, rnp->blkd_tasks.next);
// [...]
}
}
// kernel/rcu/tree_plugin.h
static bool rcu_preempt_has_tasks(struct rcu_node *rnp)
{
return !list_empty(&rnp->blkd_tasks);
}
The __note_gp_changes() function is executed not only at the beginning but also during the cleanup phase. During its first execution, it calls rcu_seq_completed_gp() to compare RCU node sequence numbers with rcu_data. If the numbers are different, the function returns false and continues to the next step [6]. Then, rcu_seq_new_gp() checks whether it is a new grace period by comparing the sequence numbers, returning true if it is and updating the QS-related fields to true [7]. Subsequently, it synchronizes the gp_seq and gp_seq_needed of the RCU node with the rcu_data [8].
// kernel/rcu/tree.c
static bool __note_gp_changes(struct rcu_node *rnp, struct rcu_data *rdp)
{
bool ret = false;
bool need_qs;
// [...]
if (rcu_seq_completed_gp(rdp->gp_seq, rnp->gp_seq)) {
// [...]
} else {
// [6]
// [...]
}
// there is a new grace period
if (rcu_seq_new_gp(rdp->gp_seq, rnp->gp_seq)) {
need_qs = !!(rnp->qsmask & rdp->grpmask);
rdp->cpu_no_qs.b.norm = need_qs; // [7]
rdp->core_needs_qs = need_qs; // [7]
// [...]
}
rdp->gp_seq = rnp->gp_seq; // [8]
if (ULONG_CMP_LT(rdp->gp_seq_needed, rnp->gp_seq_needed))
WRITE_ONCE(rdp->gp_seq_needed, rnp->gp_seq_needed);
// [...]
}
// kernel/rcu/rcu.h
static inline bool rcu_seq_completed_gp(unsigned long old, unsigned long new)
{
return ULONG_CMP_LT(old, new & ~RCU_SEQ_STATE_MASK);
}
// kernel/rcu/rcu.h
static inline bool rcu_seq_new_gp(unsigned long old, unsigned long new)
{
return ULONG_CMP_LT((old + RCU_SEQ_STATE_MASK) & ~RCU_SEQ_STATE_MASK,
new);
}
The RCU objects have some updates:
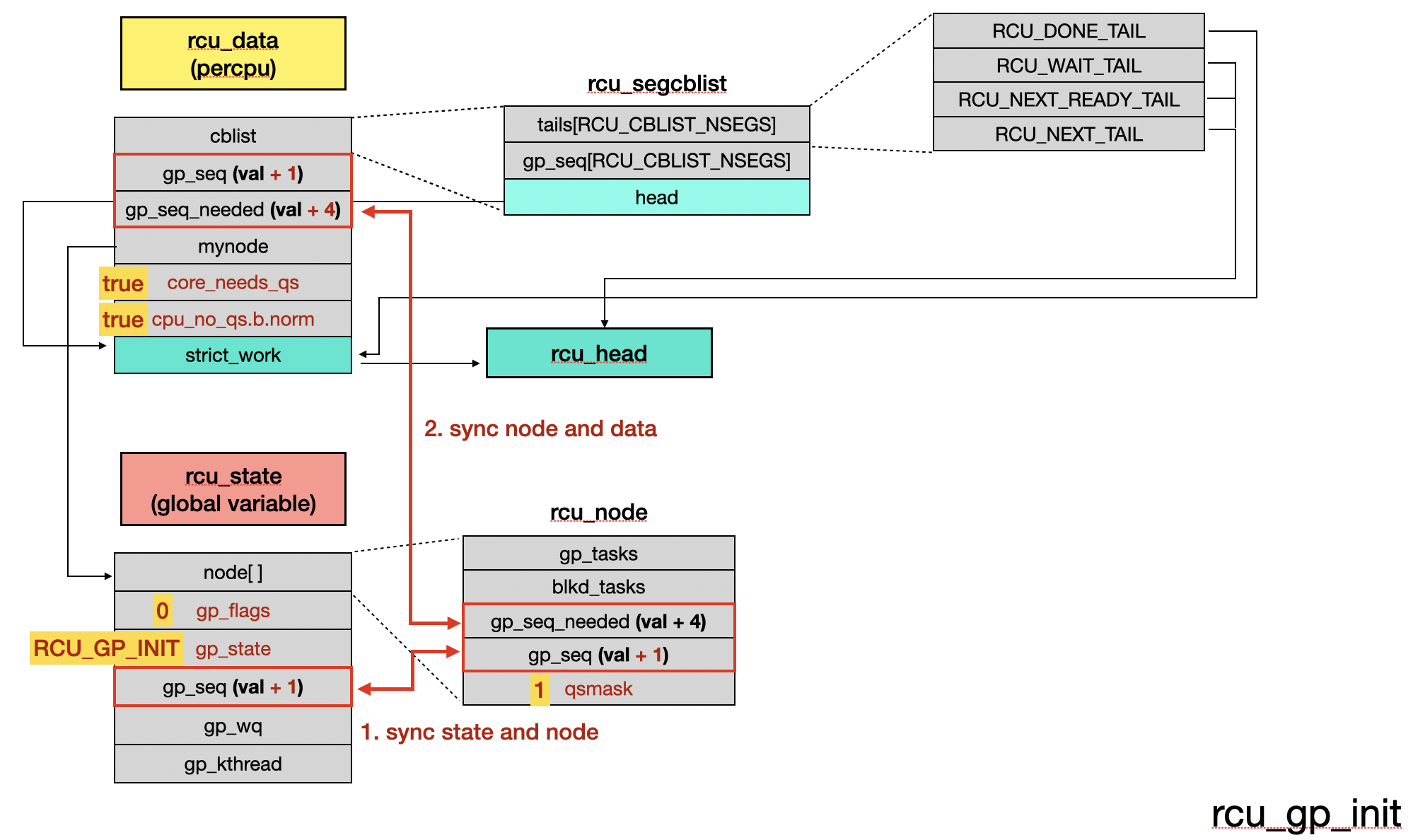
After rcu_gp_kthread() completes rcu_gp_init(), it exits the innermost loop and proceeds to the second half of the process. It first calls rcu_gp_fqs_loop() to wait for the RCU grace period to end, ensuring that each CPU reaches a quiescent state (QS). Then, it invokes rcu_gp_cleanup() to perform the post-grace period cleanup tasks.
// kernel/rcu/tree.c
static int __noreturn rcu_gp_kthread(void *unused)
{
for (;;) {
// [...]
rcu_gp_fqs_loop();
WRITE_ONCE(rcu_state.gp_state, RCU_GP_CLEANUP);
rcu_gp_cleanup();
WRITE_ONCE(rcu_state.gp_state, RCU_GP_CLEANED);
}
}
rcu_gp_fqs_loop() waits for either a flags update or a timeout (jiffies_till_first_fqs) [9]. It exits once all CPUs reach a quiescent state (QS) and there are no blocked readers [10]. Otherwise, it updates the state and continues waiting for the next QS phase.
// kernel/rcu/tree.c
static noinline_for_stack void rcu_gp_fqs_loop(void)
{
bool first_gp_fqs = true;
int gf = 0;
unsigned long j;
int ret;
struct rcu_node *rnp = rcu_get_root();
j = READ_ONCE(jiffies_till_first_fqs);
ret = 0;
for (;;) {
// [...]
WRITE_ONCE(rcu_state.gp_state, RCU_GP_WAIT_FQS); // start to force QS
// wait rcu_gp_fqs_check_wake(&gf) to become true or timeout
swait_event_idle_timeout_exclusive(rcu_state.gp_wq, // [9]
rcu_gp_fqs_check_wake(&gf), j);
WRITE_ONCE(rcu_state.gp_state, RCU_GP_DOING_FQS); // the FQS end
// [10]
if (!READ_ONCE(rnp->qsmask) &&
!rcu_preempt_blocked_readers_cgp(rnp))
break;
// [...]
}
}
// kernel/rcu/tree_plugin.h
static int rcu_preempt_blocked_readers_cgp(struct rcu_node *rnp)
{
return READ_ONCE(rnp->gp_tasks) != NULL;
}
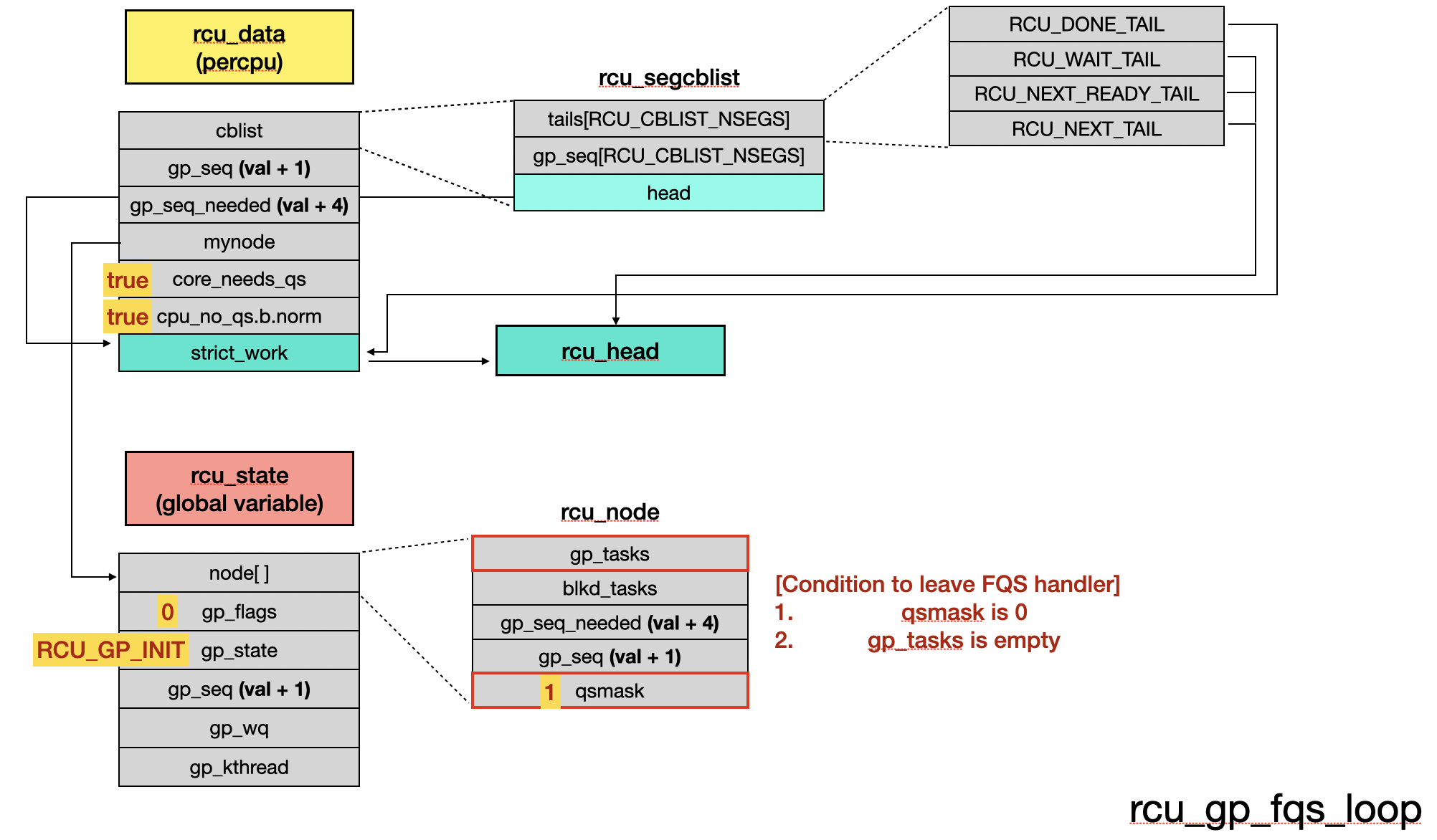
To satisfy these two conditions, we need:
-
During a context switch,
rcu_note_context_switch()is called and setscpu_no_qs.b.normto 0.// kernel/rcu/tree_plugin.h void rcu_note_context_switch(bool preempt) { // [...] rcu_qs(); // [...] } // kernel/rcu/tree_plugin.h static void rcu_qs(void) { if (__this_cpu_read(rcu_data.cpu_no_qs.b.norm)) { __this_cpu_write(rcu_data.cpu_no_qs.b.norm, false); WRITE_ONCE(current->rcu_read_unlock_special.b.need_qs, false); } }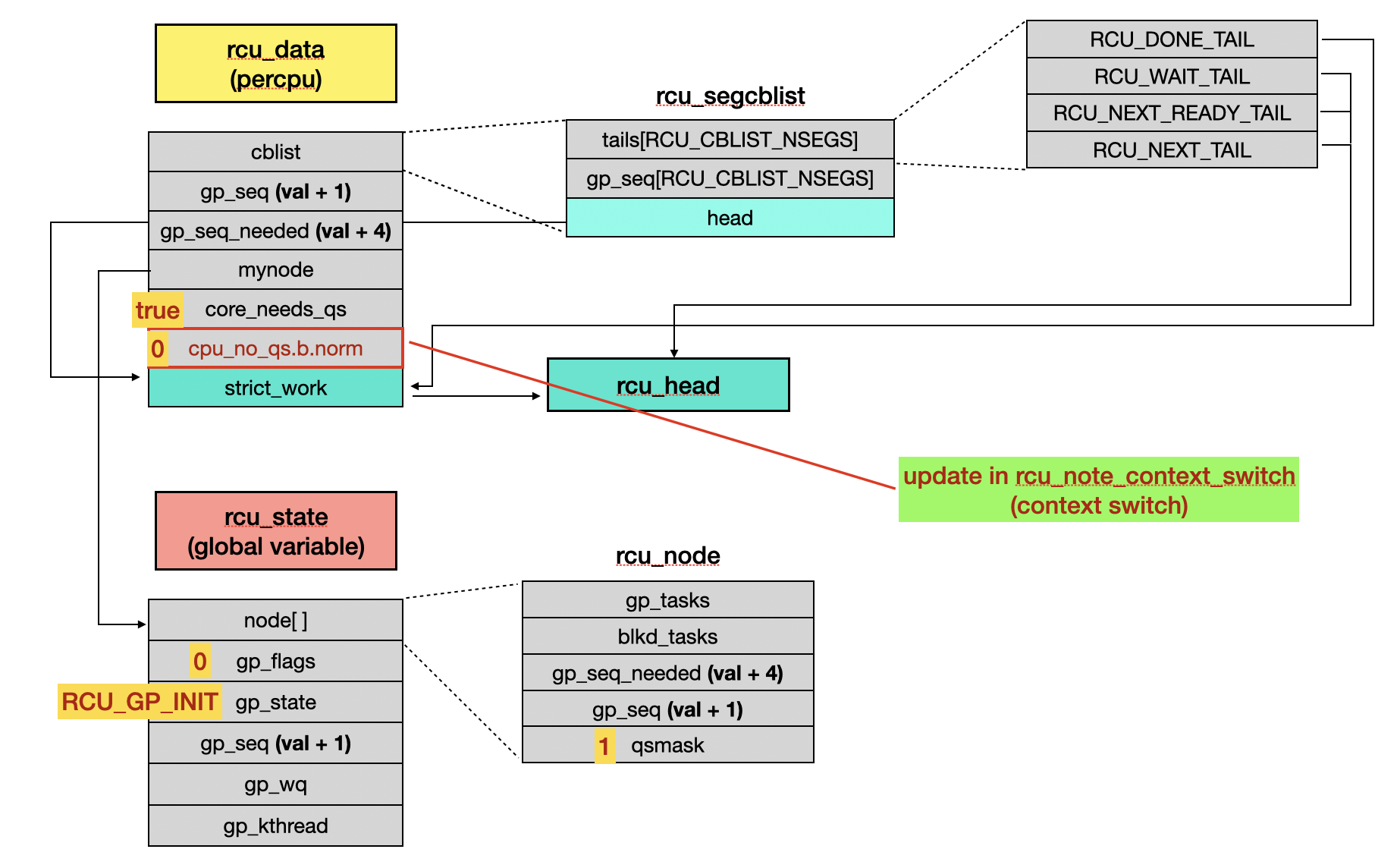
-
When handling
RCU_SOFTIRQ,rcu_check_quiescent_state()detects that the current CPU has reached a QS and callsrcu_report_qs_rdp()to update the QS fields.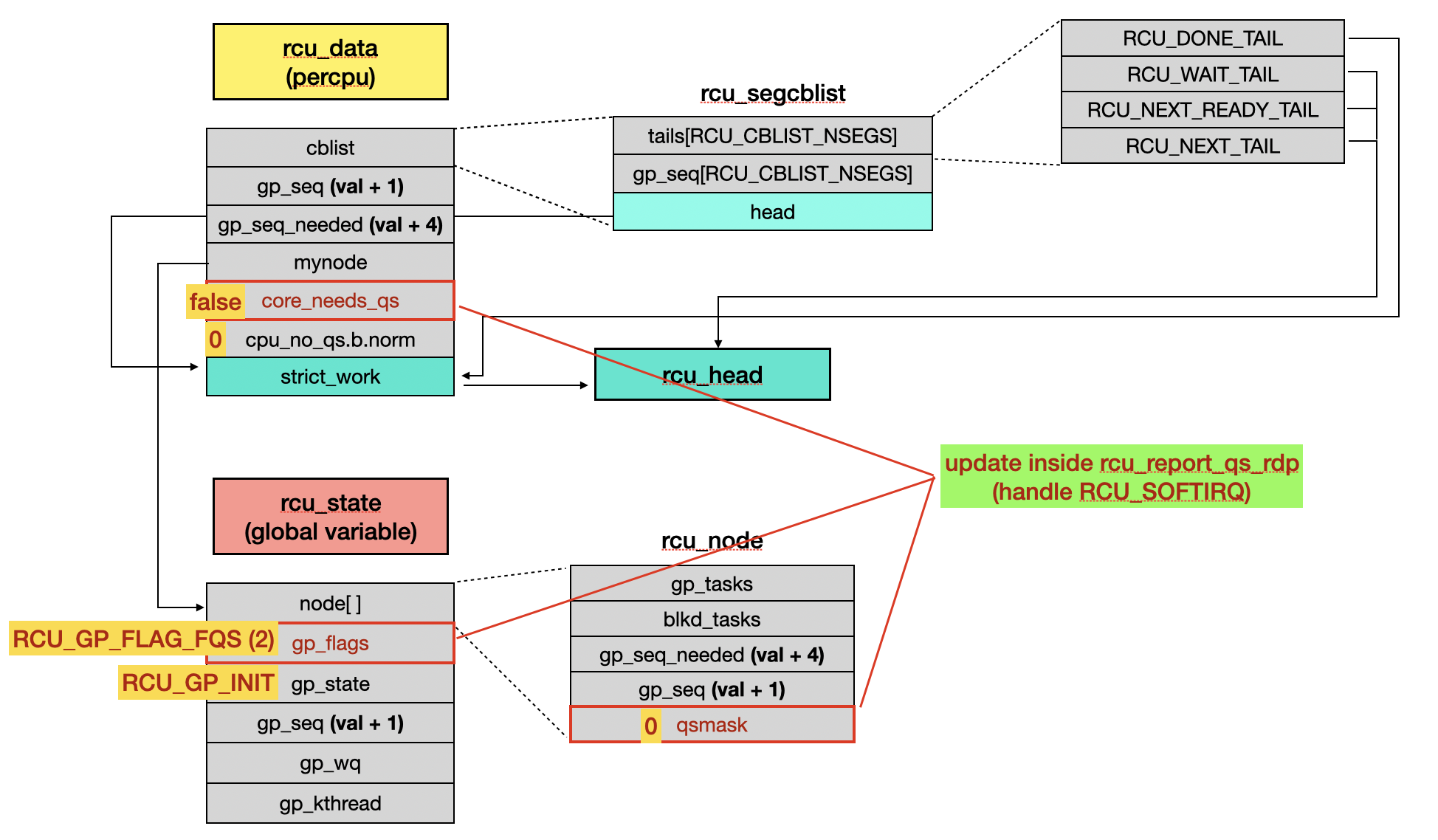
-
In a non-preemptible kernel,
gp_tasksis always empty, allowingrcu_gp_fqs_loop()to return afterrcu_report_qs_rdp()updates the QS fields. (We’ll cover handling the preemptible kernel in section 3.5)
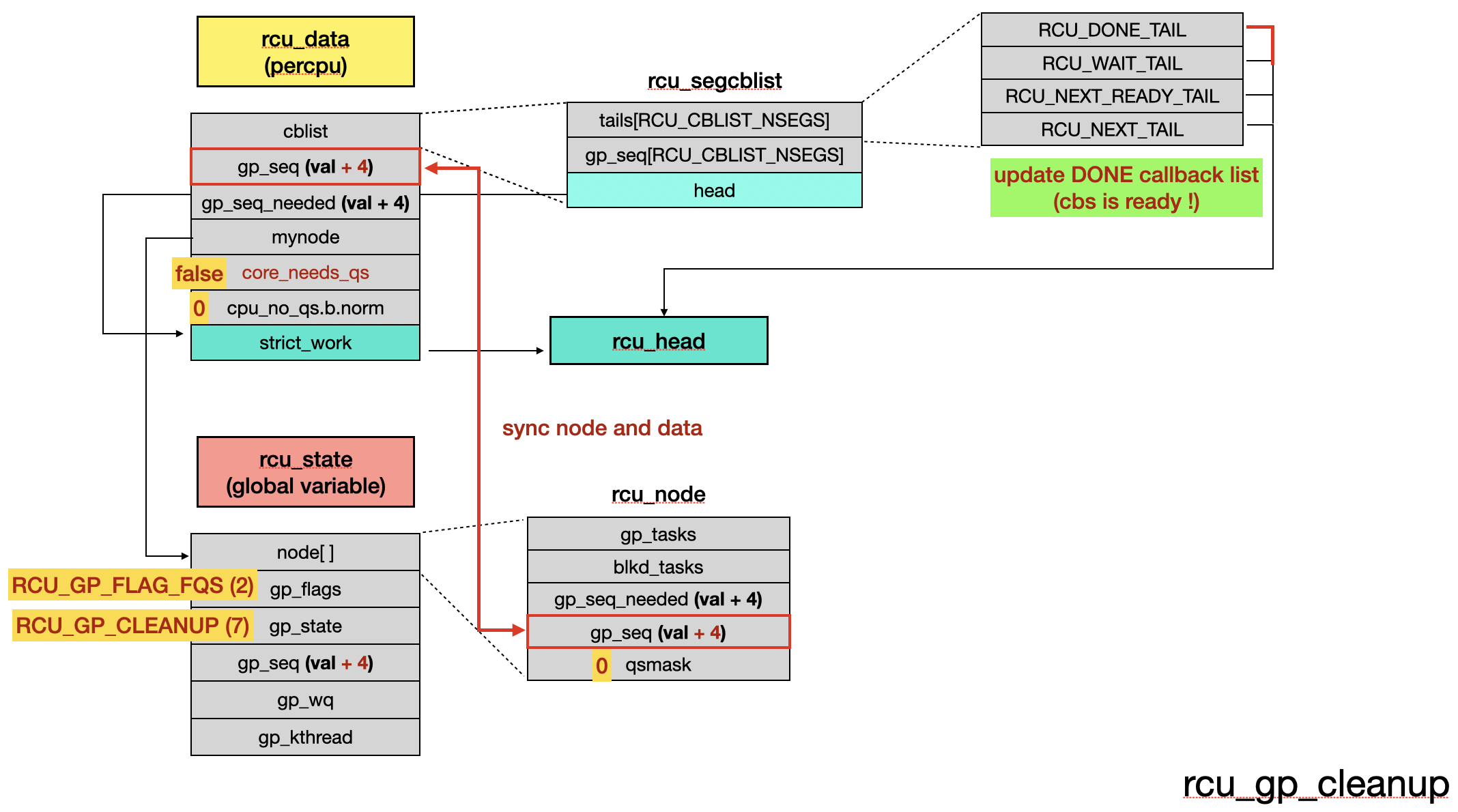
At the beginning of rcu_gp_cleanup(), the function updates sequence-related data and calculates the sequence number for the completed grace period [11]. It then updates the sequence numbers of all RCU nodes [12]. During this process, __note_gp_changes() is called a second time [13] to move the callback list to RCU_DONE_TAIL list. Finally, after re-enabling IRQs, the softirq handler executes rcu_do_batch().
// kernel/rcu/tree.c
static noinline void rcu_gp_cleanup(void)
{
// [...]
new_gp_seq = rcu_state.gp_seq;
rcu_seq_end(&new_gp_seq); // [11]
rcu_for_each_node_breadth_first(rnp) {
raw_spin_lock_irq_rcu_node(rnp);
WRITE_ONCE(rnp->gp_seq, new_gp_seq); // [12]
// [...]
rdp = this_cpu_ptr(&rcu_data);
if (rnp == rdp->mynode)
needgp = __note_gp_changes(rnp, rdp) || needgp; // [13]
// [...]
raw_spin_unlock_irq_rcu_node(rnp);
// trigger IRQ handler --> rcu_core() --> rcu_do_batch()
// [...]
}
rcu_seq_end(&rcu_state.gp_seq);
// [...]
}
The execution flow of __note_gp_changes() during cleanup differs from its first invocation. Since the grace period has already ended, it proceeds to execute rcu_advance_cbs() and marks that no further quiescent states (QS) are needed.
// kernel/rcu/tree.c
static bool __note_gp_changes(struct rcu_node *rnp, struct rcu_data *rdp)
{
if (rcu_seq_completed_gp(rdp->gp_seq, rnp->gp_seq)) {
ret = rcu_advance_cbs(rnp, rdp);
rdp->core_needs_qs = false;
}
// [...]
}
rcu_advance_cbs() moves the RCU nodes that are ready for execution to the RCU_DONE_TAIL list. Additionally, it calls rcu_accelerate_cbs() to check for any unfinished RCU nodes. If any are found, it initiates the next grace period.
// kernel/rcu/tree.c
static bool rcu_advance_cbs(struct rcu_node *rnp, struct rcu_data *rdp)
{
// [...]
rcu_segcblist_advance(&rdp->cblist, rnp->gp_seq);
return rcu_accelerate_cbs(rnp, rdp);
}
rcu_segcblist_advance() iterates through the callback lists of different states and moves RCU nodes whose grace period has ended to the RCU_DONE_TAIL list.
// kernel/rcu/rcu_segcblist.c
void rcu_segcblist_advance(struct rcu_segcblist *rsclp, unsigned long seq)
{
int i, j;
if (rcu_segcblist_restempty(rsclp, RCU_DONE_TAIL))
return;
for (i = RCU_WAIT_TAIL; i < RCU_NEXT_TAIL; i++) {
if (ULONG_CMP_LT(seq, rsclp->gp_seq[i]))
break;
WRITE_ONCE(rsclp->tails[RCU_DONE_TAIL], rsclp->tails[i]);
rcu_segcblist_move_seglen(rsclp, i, RCU_DONE_TAIL);
}
// [...]
}
// kernel/rcu/rcu_segcblist.h
static inline bool rcu_segcblist_restempty(struct rcu_segcblist *rsclp, int seg)
{
return !READ_ONCE(*READ_ONCE(rsclp->tails[seg]));
}
After rcu_gp_cleanup(), the RCU objects are be as follows:
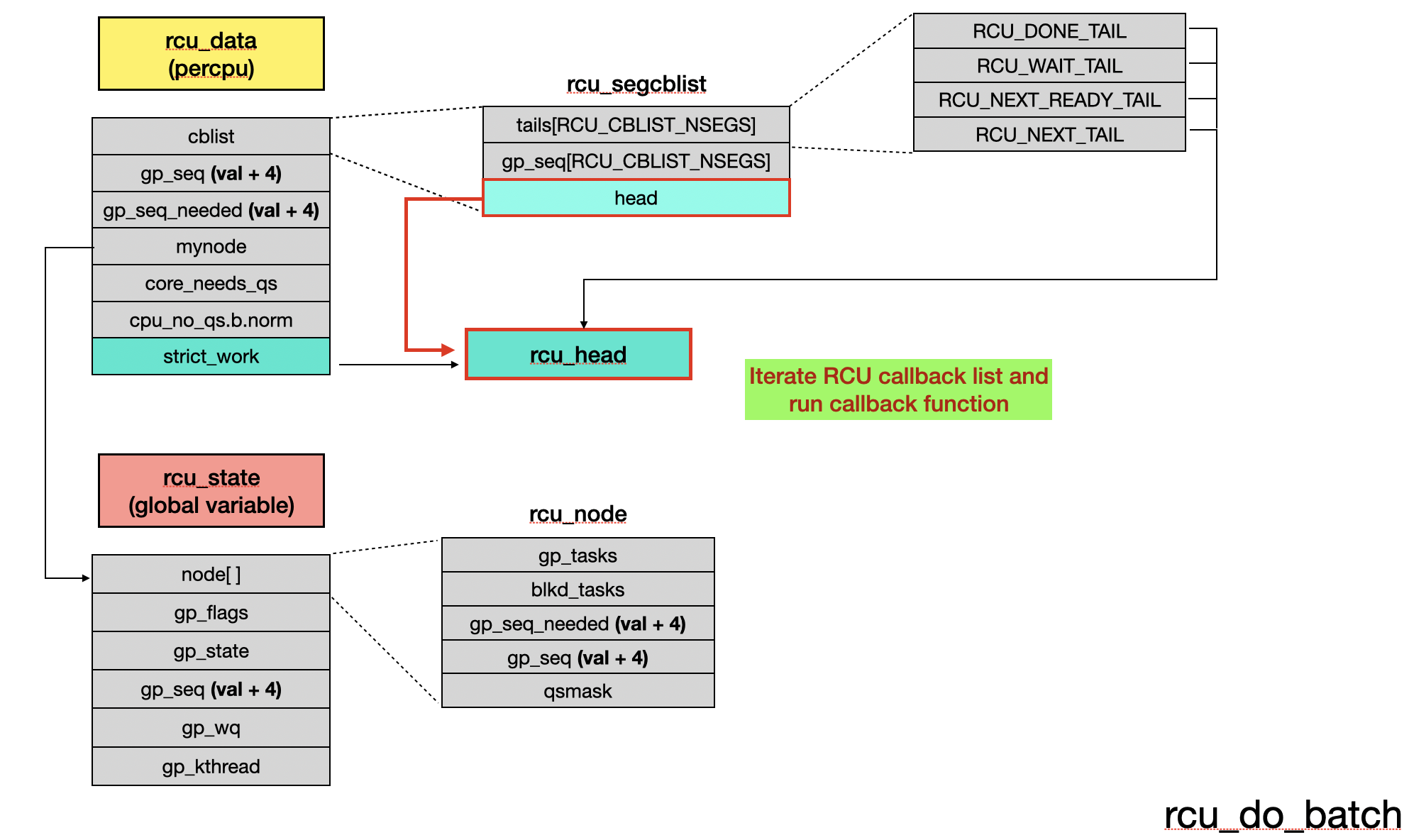
Run RCU Callback
During the next occurrence of rcu_core(), since the RCU_DONE_TAIL list is not empty, rcu_do_batch() will be called to execute the RCU callbacks.
// kernel/rcu/tree.c
static __latent_entropy void rcu_core(void)
{
// [...]
if (rcu_segcblist_ready_cbs(&rdp->cblist) && /* ... */) {
rcu_do_batch(rdp);
// [...]
}
}
rcu_do_batch() dequeues RCU objects and invokes their respective callback functions.
// kernel/rcu/tree.c
static void rcu_do_batch(struct rcu_data *rdp)
{
// [...]
rcu_segcblist_extract_done_cbs(&rdp->cblist, &rcl);
rhp = rcu_cblist_dequeue(&rcl);
for (; rhp; rhp = rcu_cblist_dequeue(&rcl)) {
// [...]
f = rhp->func;
f(rhp);
// [...]
}
// [...]
}
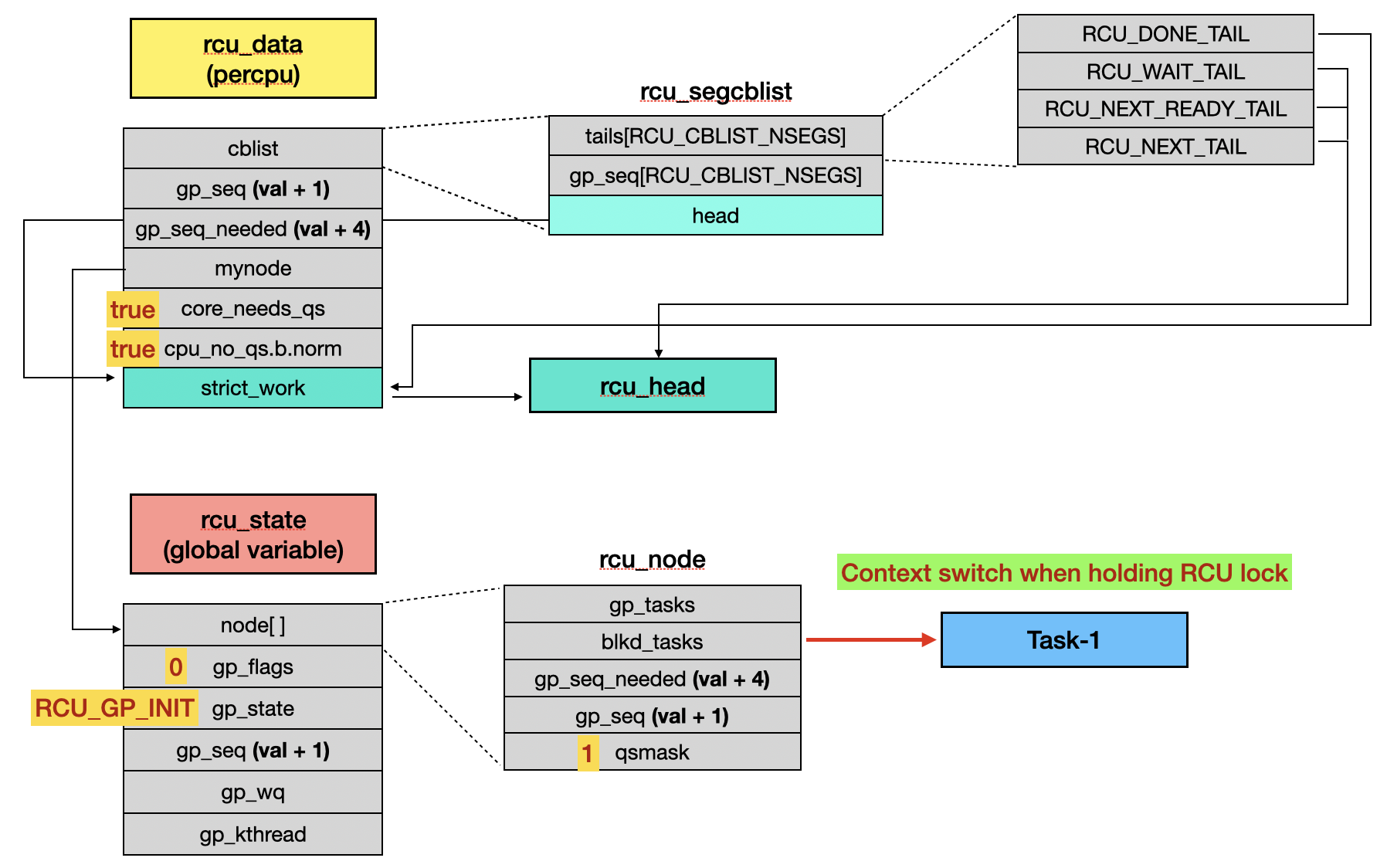
3.5 Preemptive RCU
There are three types of preemption in the Linux kernel: preemptible (CONFIG_PREEMPT=y), voluntary preemption (CONFIG_PREEMPT_VOLUNTARY=y), and no preemption (CONFIG_PREEMPT_NONE=y).
In the non-preemptible (CONFIG_PREEMPT=n) kernel, a context switch to another task occurs only when the current task voluntarily releases the execution resources. Theoretically, as long as every CPU completes at least one context switch, it guarantees that all CPUs have reached QS, since tasks holding an RCU read lock do not voluntarily release execution resources. However, if a CPU voluntarily releases execution resources while holding the RCU lock, warning will be triggered during the context switch process, and subsequent handling will be similar to preemptible kernel.
void rcu_note_context_switch(bool preempt)
{
// [...]
WARN_ONCE(!preempt && rcu_preempt_depth() > 0, "Voluntary context switch within RCU read-side critical section!");
// [...]
}
In a preemptible kernel, when the time slot expires, the execution resources are forcibly changed to another task. If a process is still holding an RCU read lock at this time, it will be placed in a blocked queue and marked for special handling. Later, when the task is switched back and rcu_read_unlock() is called, rcu_read_unlock_special() will be invoked to clear the blocked queue, allowing the force QS function rcu_gp_fqs_loop() to continue its execution.
Scheduling
When a context switch occurs, __schedule() is called. If it detects that the task is still holding an RCU lock, it sets fields related to RCU special unlock handling [1] and places the task into the blocked task list [2].
// kernel/sched/core.c
static void __sched notrace __schedule(unsigned int sched_mode)
{
// [...]
rcu_note_context_switch(!!sched_mode);
// [...]
}
// kernel/rcu/tree_plugin.h
void rcu_note_context_switch(bool preempt)
{
struct task_struct *t = current;
if (rcu_preempt_depth() > 0 &&
!t->rcu_read_unlock_special.b.blocked) {
rnp = rdp->mynode;
// [...]
t->rcu_read_unlock_special.b.blocked = true; // [1]
rcu_preempt_ctxt_queue(rnp, rdp); // [2]
// [...]
}
// [...]
}
// kernel/rcu/tree_plugin.h
static void rcu_preempt_ctxt_queue(struct rcu_node *rnp, struct rcu_data *rdp)
{
struct task_struct *t = current;
// [...]
list_add(&t->rcu_node_entry, &rnp->blkd_tasks);
}
When the kthread “rcu_preempt” calls rcu_gp_init() to prepare a new grace period, if it finds the blocked task list is not empty, it will move those tasks to rnp->gp_tasks.
// kernel/rcu/tree.c
static noinline_for_stack bool rcu_gp_init(void)
{
// [...]
rcu_for_each_node_breadth_first(rnp) {
rcu_preempt_check_blocked_tasks(rnp);
}
// [...]
}
// kernel/rcu/tree_plugin.h
static bool rcu_preempt_has_tasks(struct rcu_node *rnp)
{
return !list_empty(&rnp->blkd_tasks);
}
// kernel/rcu/tree_plugin.h
static void rcu_preempt_check_blocked_tasks(struct rcu_node *rnp)
{
struct task_struct *t;
if (rcu_preempt_has_tasks(rnp) &&
(rnp->qsmaskinit || rnp->wait_blkd_tasks)) {
WRITE_ONCE(rnp->gp_tasks, rnp->blkd_tasks.next);
}
}
// kernel/rcu/tree_plugin.h
static bool rcu_preempt_has_tasks(struct rcu_node *rnp)
{
return !list_empty(&rnp->blkd_tasks);
}
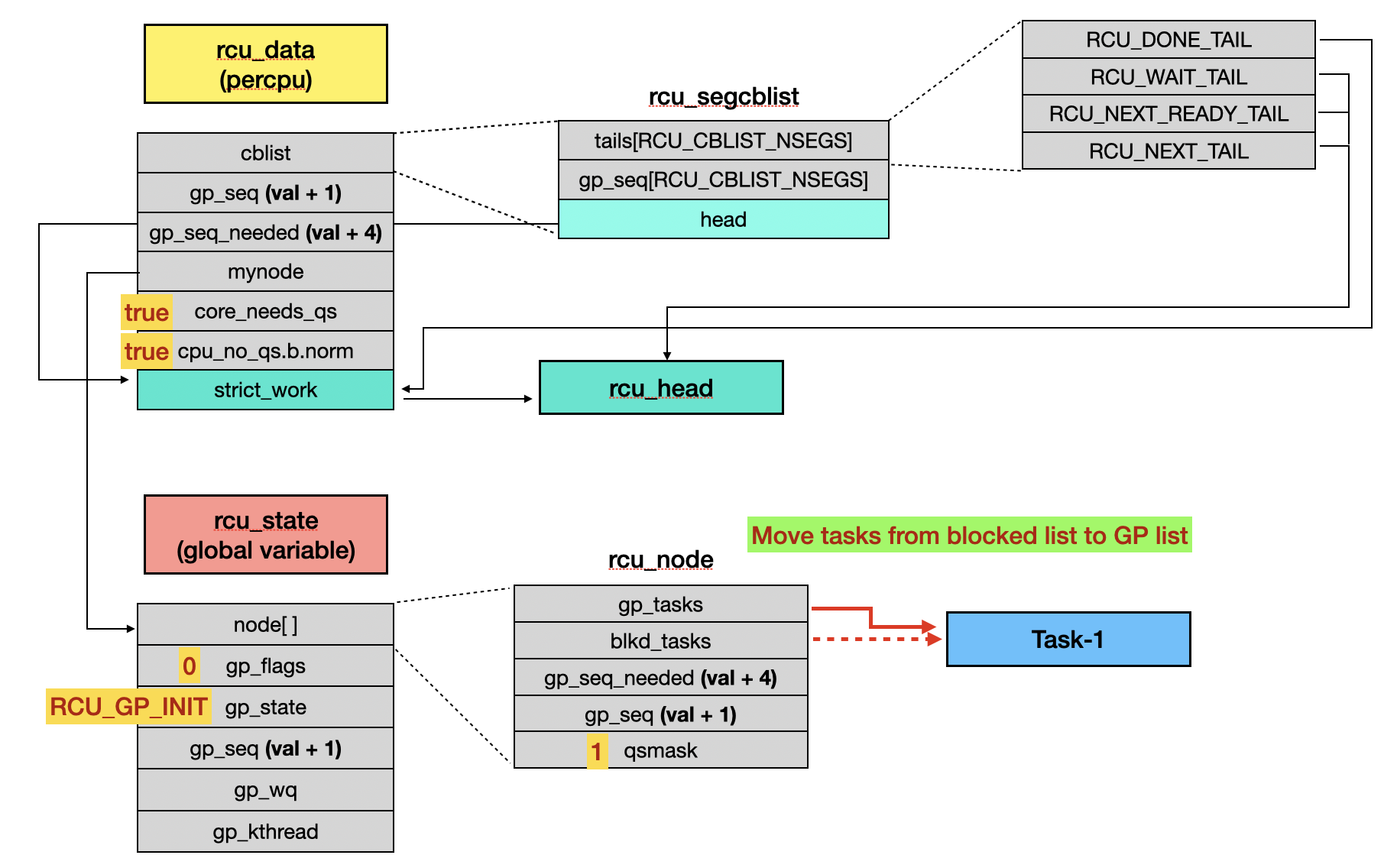
Subsequently, because rnp->gp_tasks is not empty [3], the rcu_gp_fqs_loop() will be stuck in the for loop, resulting in the RCU callback not being invoked.
// kernel/rcu/tree.c
static noinline_for_stack void rcu_gp_fqs_loop(void)
{
// [...]
for (;;) {
// [...]
if (!READ_ONCE(rnp->qsmask) &&
!rcu_preempt_blocked_readers_cgp(rnp)) // [3]
break;
// [...]
}
// [...]
}
// kernel/rcu/tree_plugin.h
static int rcu_preempt_blocked_readers_cgp(struct rcu_node *rnp)
{
return READ_ONCE(rnp->gp_tasks) != NULL;
}
If the blocked task subsequently executes __rcu_read_unlock() and detects that the RCU special unlock fields have been set, it will call rcu_read_unlock_special().
// kernel/rcu/tree_plugin.h
void __rcu_read_unlock(void)
{
// [...]
struct task_struct *t = current;
if (rcu_preempt_read_exit() == 0) {
if (unlikely(READ_ONCE(t->rcu_read_unlock_special.s)))
rcu_read_unlock_special(t);
}
// [...]
}
// kernel/rcu/tree_plugin.h
static void rcu_read_unlock_special(struct task_struct *t)
{
// [...]
rcu_preempt_deferred_qs_irqrestore(t, flags);
}
The internal function rcu_preempt_deferred_qs_irqrestore() resets rnp->gp_tasks to NULL [4], allowing rcu_gp_fqs_loop() to continue its execution.
// kernel/rcu/tree_plugin.h
static notrace void
rcu_preempt_deferred_qs_irqrestore(struct task_struct *t, unsigned long flags)
{
if (special.b.blocked) {
np = rcu_next_node_entry(t, rnp);
if (&t->rcu_node_entry == rnp->gp_tasks)
WRITE_ONCE(rnp->gp_tasks, np); // [4]
}
}
Interesting, once process exits, the RCU state is also reset.
// kernel/exit.c
void __noreturn do_exit(long code)
{
exit_rcu();
}
// kernel/rcu/tree_plugin.h
void exit_rcu(void)
{
struct task_struct *t = current;
if (unlikely(!list_empty(¤t->rcu_node_entry))) {
rcu_preempt_depth_set(1);
barrier();
WRITE_ONCE(t->rcu_read_unlock_special.b.blocked, true);
} else if (unlikely(rcu_preempt_depth())) {
rcu_preempt_depth_set(1);
} else {
return;
}
__rcu_read_unlock();
rcu_preempt_deferred_qs(current);
}