Linux vDSO & VVAR
One day, while reviewing the past vulnerabilities in Linux io_uring, I found that CVE-2023-23586 is a “vvar” Read-Only page UAF. It sounds interesting, so I spent an entire day analyzing what it is and how it works. Below are the details, enjoy!
1. Overview
vDSO and VVAR are two special mappings for processes, you can see them in the output of /proc/<pid>/maps:
aaa@aaa:~$ cat /proc/self/maps
[...]
7fff7e6d7000-7fff7e6db000 r--p 00000000 00:00 0 [vvar]
7fff7e6db000-7fff7e6dd000 r-xp 00000000 00:00 0 [vdso]
[...]
The vDSO, short for “virtual dynamic shared object”, is a lightweight shared object used to implement frequently called system calls, such as gettimeofday() and time(). VVAR, short for “virtual variables”, is a memory region that stores data and variables related to the vDSO.
The vDSO file (vdso64.so) is automatically generated and compiled into the kernel image. Unfortunately, I am not familiar with the complete execution flow, so I cannot explain how it works. Kernel functions can access the vdso_image_64 variable to retrieve vDSO metadata, including raw ELF data and VVAR data offsets. For more details, you can refer to the file arch/x86/entry/vdso/vdso2c.h.
When executing a ELF using sys_execve, the kernel function load_elf_binary() is invoked to load the binary and additional pages into memory.
static int load_elf_binary(struct linux_binprm *bprm)
{
// [...]
retval = ARCH_SETUP_ADDITIONAL_PAGES(bprm, elf_ex, !!interpreter);
// [...]
}
int arch_setup_additional_pages(struct linux_binprm *bprm, int uses_interp)
{
// [...]
return map_vdso_randomized(&vdso_image_64);
}
static int map_vdso_randomized(const struct vdso_image *image)
{
unsigned long addr = vdso_addr(current->mm->start_stack, image->size-image->sym_vvar_start);
return map_vdso(image, addr);
}
These additional pages include vDSO [1] and VVAR [2], and the function _install_special_mapping() is invoked by map_vdso() to install them.
static int map_vdso(const struct vdso_image *image, unsigned long addr)
{
// [...]
vma = _install_special_mapping(mm,
text_start,
image->size,
VM_READ|VM_EXEC|
VM_MAYREAD|VM_MAYWRITE|VM_MAYEXEC,
&vdso_mapping); // [1]
// [...]
vma = _install_special_mapping(mm,
addr,
-image->sym_vvar_start,
VM_READ|VM_MAYREAD|VM_IO|VM_DONTDUMP|
VM_PFNMAP,
&vvar_mapping); // [2]
// [...]
}
struct vm_area_struct *_install_special_mapping(
struct mm_struct *mm,
unsigned long addr, unsigned long len,
unsigned long vm_flags, const struct vm_special_mapping *spec)
{
return __install_special_mapping(mm, addr, len, vm_flags, (void *)spec,
&special_mapping_vmops);
}
static const struct vm_operations_struct special_mapping_vmops = {
.close = special_mapping_close,
.fault = special_mapping_fault,
.mremap = special_mapping_mremap,
.name = special_mapping_name,
.access = NULL,
.may_split = special_mapping_split,
};
Special mappings use the special_mapping_vmops [3] variable as their vmops and special vmops as their private data [4].
static struct vm_area_struct *__install_special_mapping(
struct mm_struct *mm,
unsigned long addr, unsigned long len,
unsigned long vm_flags, void *priv,
const struct vm_operations_struct *ops)
{
int ret;
struct vm_area_struct *vma;
vma = vm_area_alloc(mm);
vma->vm_start = addr;
vma->vm_end = addr + len;
// [...]
vma->vm_ops = ops; // [3]
vma->vm_private_data = priv; // [4]
ret = insert_vm_struct(mm, vma);
// [...]
}
vDSO and VVAR have distinct handlers for handling page faults and memory remapping.
static const struct vm_special_mapping vdso_mapping = {
.name = "[vdso]",
.fault = vdso_fault,
.mremap = vdso_mremap,
};
static const struct vm_special_mapping vvar_mapping = {
.name = "[vvar]",
.fault = vvar_fault,
};
Here we focus specifically on VVAR’s fault handler and how it manages a time namespace page fault. The handler first locates the page of the VVAR memory region [5], retrieves the physical frame number (pfn) [6], and then binds the physical page to the vma object [7].
static vm_fault_t vvar_fault(const struct vm_special_mapping *sm,
struct vm_area_struct *vma, struct vm_fault *vmf)
{
// [...]
if (sym_offset == image->sym_vvar_page) {
struct page *timens_page = find_timens_vvar_page(vma); // [5]
// [...]
if (timens_page) {
// [...]
pfn = page_to_pfn(timens_page); // [6]
}
return vmf_insert_pfn(vma, vmf->address, pfn); // [7]
}
// [...]
}
The nsproxy->time_ns object represents the metadata of a time namespace, including the VVAR page object.
struct page *find_timens_vvar_page(struct vm_area_struct *vma)
{
if (likely(vma->vm_mm == current->mm))
return current->nsproxy->time_ns->vvar_page;
}
2. Allocation
To figure out when VVAR page (timens->vvar_page) is assigned, we need to understand how the kernel handles process creation. The kernel calls copy_process() to set up process resources, including namespace. Simlilarly, we focus on operation related clone flags CLONE_VM and CLONE_NEWTIME.
struct task_struct *copy_process(/*...*/)
{
struct task_struct *p;
struct nsproxy *nsp = current->nsproxy;
// task_struct of child process
p = dup_task_struct(current, node);
// [...]
retval = copy_mm(clone_flags, p);
retval = copy_namespaces(clone_flags, p);
// [...]
}
The kernel determines whether to share the memory region with parent based on clone_flags. If the CLONE_VM flag is set [1], the kernel will reuse parent’s mm object; otherwise, it duplicates a new one [2].
static int copy_mm(unsigned long clone_flags, struct task_struct *tsk)
{
struct mm_struct *mm, *oldmm;
// [...]
if (clone_flags & CLONE_VM) {
mmget(oldmm); // [1]
mm = oldmm;
} else {
mm = dup_mm(tsk, current->mm); // [2]
}
tsk->mm = mm;
tsk->active_mm = mm;
// [...]
}
The creation of namespaces is somewhat complex. It is helpful to have the operation result in mind before diving into the source code.
| flags | nsproxy | mm | time_ns | time_ns_for_children |
|---|---|---|---|---|
CLONE_VM + CLONE_NEWTIME |
new | inherit | old | new (!= time_ns) |
CLONE_NEWTIME |
new | new | new | new (== time_ns) |
CLONE_VM |
inherit | inherit | X | X |
| No | inherit | new | X | X |
After setting up the mm object, the function copy_namespaces() is called. It first checks if any flag is provided. If none is provided, it simply reuses the old namespace proxy [3]. If flags are provided, it calls create_new_namespaces() to create a new nsproxy object. After that, it calls timens_on_fork() if CLONE_VM is not included in the flags.
int copy_namespaces(unsigned long flags, struct task_struct *tsk)
{
struct nsproxy *old_ns = tsk->nsproxy;
struct user_namespace *user_ns = task_cred_xxx(tsk, user_ns);
struct nsproxy *new_ns;
if (likely(!(flags & (CLONE_NEWNS | CLONE_NEWUTS | CLONE_NEWIPC |
CLONE_NEWPID | CLONE_NEWNET |
CLONE_NEWCGROUP | CLONE_NEWTIME)))) {
// not provide any flag
if ((flags & CLONE_VM) ||
likely(old_ns->time_ns_for_children == old_ns->time_ns)) {
// share mm with child, or children needs no new time ns
get_nsproxy(old_ns); // [3]
return 0;
}
} /* ... */
new_ns = create_new_namespaces(flags, tsk, user_ns, tsk->fs); // [4]
if ((flags & CLONE_VM) == 0) // not share same memory space (mm)
timens_on_fork(new_ns, tsk);
tsk->nsproxy = new_ns;
return 0;
}
If user does not require a new namespace of the corresponding type, the function create_new_namespaces() [4] just obtains a reference from the parent process. Otherwise, it clones a new namespace and initializes it.
However, there is a special case for time namespace (represented as time_ns in the source code): the kernel always inherits the time namespace from the parent process [5].
static struct nsproxy *create_new_namespaces(unsigned long flags,
struct task_struct *tsk, struct user_namespace *user_ns,
struct fs_struct *new_fs)
{
struct nsproxy *new_nsp;
new_nsp = create_nsproxy();
// [...]
new_nsp->time_ns_for_children = copy_time_ns(flags, user_ns,
tsk->nsproxy->time_ns_for_children);
// [...]
// always inherit time_ns from parent
new_nsp->time_ns = get_time_ns(tsk->nsproxy->time_ns); // [5]
}
struct time_namespace *copy_time_ns(unsigned long flags,
struct user_namespace *user_ns, struct time_namespace *old_ns)
{
// if CLONE_NEWTIME is set, just inherit from parent
if (!(flags & CLONE_NEWTIME))
return get_time_ns(old_ns);
// or create new timens
return clone_time_ns(user_ns, old_ns);
}
A time namespace is created by clone_time_ns(), which initializes the VVAR page (ns->vvar_page) [6], the special mapping introduced earlier.
static struct time_namespace *clone_time_ns(struct user_namespace *user_ns,
struct time_namespace *old_ns)
{
struct time_namespace *ns;
// [...]
ns = kmalloc(sizeof(*ns), GFP_KERNEL_ACCOUNT);
ns->vvar_page = alloc_page(GFP_KERNEL_ACCOUNT | __GFP_ZERO); // [6]
// [...]
}
Additionally, the kernel ensures that time_ns matches time_ns_for_children [7] when forking a new process without the CLONE_VM flag. To archive this, the function timens_on_fork() sets time_ns to time_ns_for_children if they differ [8].
void timens_on_fork(struct nsproxy *nsproxy, struct task_struct *tsk)
{
struct ns_common *nsc = &nsproxy->time_ns_for_children->ns;
struct time_namespace *ns = to_time_ns(nsc);
if (nsproxy->time_ns == nsproxy->time_ns_for_children) // [7]
return;
// Only when `flags` includes `CLONE_NEWTIME` and excludes `CLONE_VM`,
// the execution flow will reach here
get_time_ns(ns);
put_time_ns(nsproxy->time_ns);
nsproxy->time_ns = ns; // [8]
timens_commit(tsk, ns);
}
The function timens_commit() is called whenever there is an update to the time namespace. This function sets up the VVAR page [9] and re-faults [10] the existing mapping using vdso_join_timens().
void timens_commit(struct task_struct *tsk, struct time_namespace *ns)
{
// setup the vvar page
timens_set_vvar_page(tsk, ns); // [9]
// if child changes time ns, the vvar page needs to re-fault,
// so we remove vvar page from the vma of child process
vdso_join_timens(tsk, ns); // [10]
}
3. Release
When the refcount of the time namespace object reaches zero, the function free_time_ns() is called to release resources. Internally, it calls __free_page() to free the VVAR page [1].
static inline void put_time_ns(struct time_namespace *ns)
{
if (refcount_dec_and_test(&ns->ns.count))
free_time_ns(ns);
}
void free_time_ns(struct time_namespace *ns)
{
dec_time_namespaces(ns->ucounts);
put_user_ns(ns->user_ns);
ns_free_inum(&ns->ns);
__free_page(ns->vvar_page); // [1]
kfree(ns);
}
4. Time_ns Installation
The system call setns is used to set a process’s namespace. The parameter fd must reference a procns file [1], which can be created by opening files within /proc/$pid/ns/. Subsequently, the function validate_ns() is called to check the preconditions before attaching to another namespace, followed by invoking commit_nsset() to apply the update.
SYSCALL_DEFINE2(setns, int, fd, int, flags)
{
struct fd f = fdget(fd);
struct ns_common *ns = NULL;
struct nsset nsset = {};
// [...]
if (proc_ns_file(f.file)) { // [1]
ns = get_proc_ns(file_inode(f.file));
// [...]
} /* [...] */
if (proc_ns_file(f.file))
err = validate_ns(&nsset, ns);
// [...]
if (!err) {
commit_nsset(&nsset);
// [...]
}
}
If the kind of namespace being updated is the time namespace, the function timens_commit() is called.
static void commit_nsset(struct nsset *nsset)
{
unsigned flags = nsset->flags;
struct task_struct *me = current;
// [...]
if (flags & CLONE_NEWTIME)
timens_commit(me, nsset->nsproxy->time_ns);
// [...]
}
The method the kernel uses for validation depends on the type of namespace. If it’s a time namespace, the function timens_install() will be called.
static inline int validate_ns(struct nsset *nsset, struct ns_common *ns)
{
return ns->ops->install(nsset, ns);
}
static int timens_install(struct nsset *nsset, struct ns_common *new)
{
struct nsproxy *nsproxy = nsset->nsproxy;
struct time_namespace *ns = to_time_ns(new);
// multi-thread isn't allowed
if (!current_is_single_threaded()) // [2]
return -EUSERS;
//[...]
// release old time_ns and time_ns_for_children
// set time_ns and time_ns_for_children to specified one
get_time_ns(ns);
put_time_ns(nsproxy->time_ns);
nsproxy->time_ns = ns;
get_time_ns(ns);
put_time_ns(nsproxy->time_ns_for_children);
nsproxy->time_ns_for_children = ns;
return 0;
}
The most interesting part is that the installation handler does now allow a multi-threaded process to update the time namespace [2]. However, this restriction was bypassed by io_uring workers, leading to the CVE-2023-23586 vulnerability.
Why is a multi-threaded process unabled to install a time namespace, and what would happen if we could bypass this restriction? To explore this experimentally, I removed the check and attempted to construct a namespace state that triggers a UAF in the VVAR page.
static int timens_install(struct nsset *nsset, struct ns_common *new) {
// [...]
- if (!current_is_single_threaded())
- return -EUSERS;
// [...]
}
5. VVAR Page UAF
Normally, the simplified relationship between namespaces and threads is illustrated below.
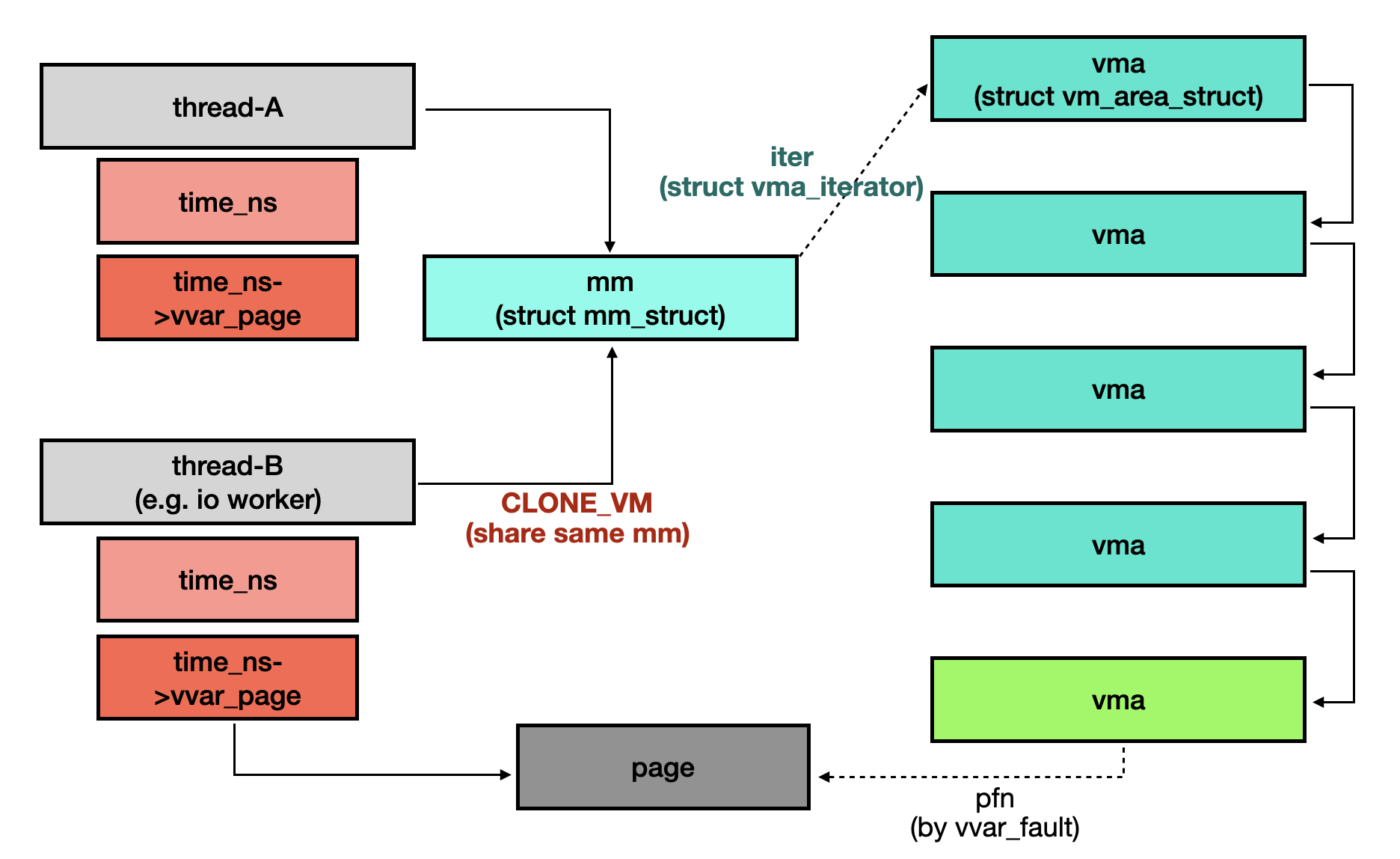
However, if two threads sharing same mm object are able to install another time namespace, the page bound to the corresponding VMA object could be either page-A or page-B, as shown in the following figure.
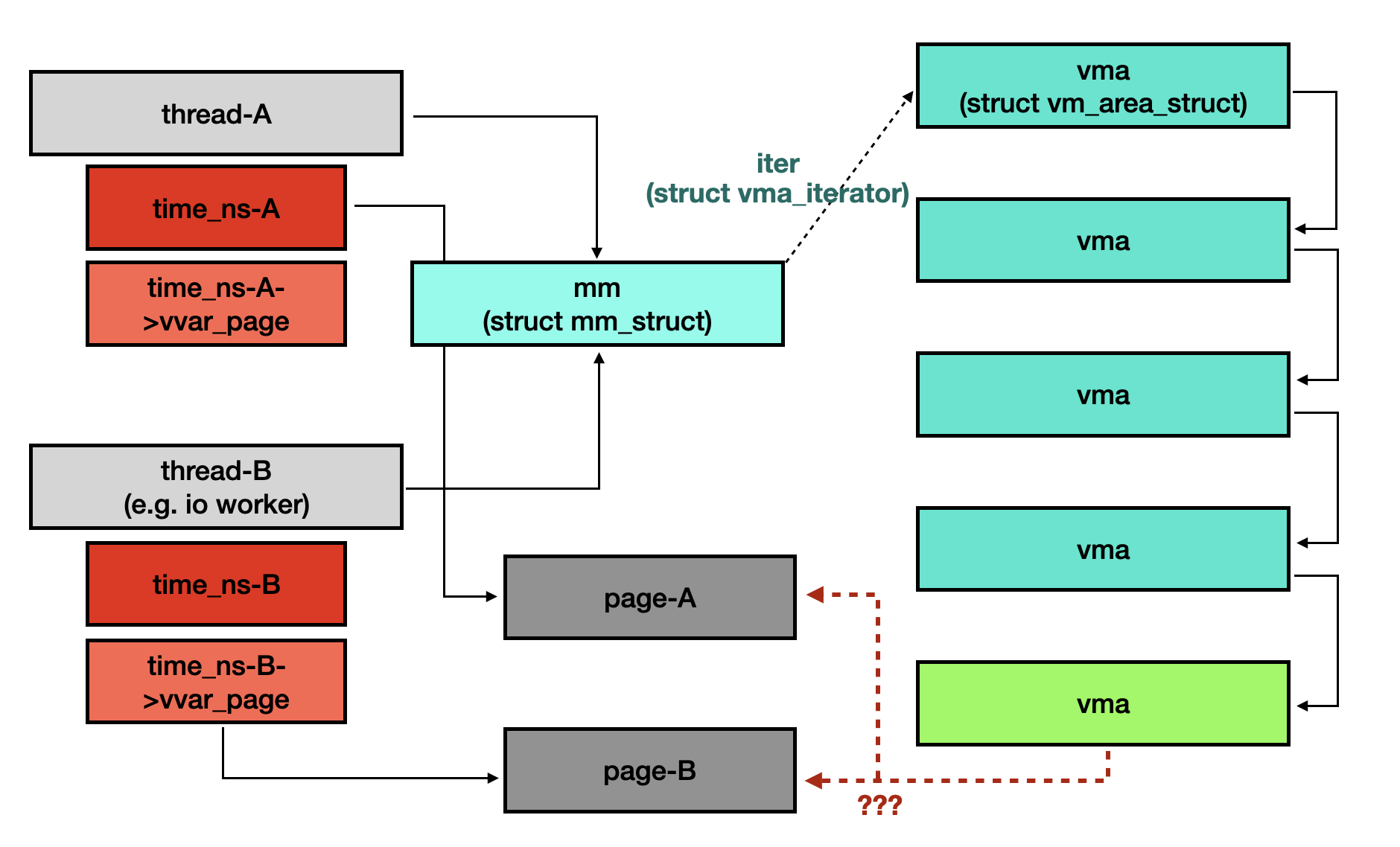
At first glance, there doesn’t appear to be any problem, but we can release the time namespace object and the VVAR page while the associated physical page remains mapped because the time namespace destructor does not zap the VMA object of the VVAR page.
I wrote a POC to demonstrate the VVAR page UAF, along with some explanatory comments. I hope you find it helpful 🙂.
6. Others
I am curious whether it is possible to cause a VVAR page fault from other processes and trigger the warning in find_timens_vvar_page().
struct page *find_timens_vvar_page(struct vm_area_struct *vma)
{
// [...]
WARN(1, "vvar_page accessed remotely");
return NULL;
}
The system calls process_vm_{readv,writev}, ptrace(PTRACE_PEEKDATA) or accessing /proc/$pid/mem can easily enalbe the virtual memory remote access. However, the vmops special_mapping_vmops doesn’t have .access handler. As a result, the VVAR page cannot be faulted from other processes.
int __access_remote_vm(struct mm_struct *mm, unsigned long addr, void *buf,
int len, unsigned int gup_flags)
{
// [...]
while (len) {
if (vma->vm_ops && vma->vm_ops->access)
bytes = vma->vm_ops->access(vma, addr, buf,
len, write);
}
// [...]
}