Remote Memory Access in Linux
In Linux, there are several methods to access the memory of another process, a technique known as “remote memory access.” However, when accessing memory, if the page may not yet be loaded, a page fault will occur, prompting the handler to load the PTE into the struct mm object of the current process. This raises the question: how does the page fault handler distinguish between remote and local memory access, and how does it deal with a remote memory access? This post will explore these questions in detail.
1. Local Memory Access
The entry function for page fault handling is asm_exc_page_fault(), which is initialized during the early boot process.
// arch/x86/kernel/idt.c
static const __initconst struct idt_data early_pf_idts[] = {
INTG(X86_TRAP_PF, asm_exc_page_fault),
};
void __init idt_setup_early_pf(void)
{
idt_setup_from_table(idt_table, early_pf_idts,
ARRAY_SIZE(early_pf_idts), true);
}
You can also retrieve the #PF handler address from the IDT entries after initialization.
# X86_TRAP_PF == 14
pwndbg> x/10i ((unsigned long)idt_table[14].offset_high << 32) + ((unsigned long)idt_table[14].offset_middle << 16) + ((unsigned long)idt_table[14].offset_low)
=> 0xffffffff82600bf0 <asm_exc_page_fault>: nop DWORD PTR [rax]
0xffffffff82600bf3 <asm_exc_page_fault+3>: cld
0xffffffff82600bf4 <asm_exc_page_fault+4>: call 0xffffffff82601550 <error_entry>
[...]
0xffffffff82600c0d <asm_exc_page_fault+29>: call 0xffffffff8246ebb0 <exc_page_fault>
[...]
This function subsequently calls exc_page_fault(), which in turn invokes do_user_addr_fault() [1] if the fault address falls within the userspace range.
// arch/x86/mm/fault.c
DEFINE_IDTENTRY_RAW_ERRORCODE(exc_page_fault)
{
unsigned long address = read_cr2();
irqentry_state_t state;
// [...]
state = irqentry_enter(regs);
handle_page_fault(regs, error_code, address); // <-------
irqentry_exit(regs, state);
}
static __always_inline void
handle_page_fault(struct pt_regs *regs, unsigned long error_code,
unsigned long address)
{
// [...]
if (unlikely(fault_in_kernel_space(address))) {
do_kern_addr_fault(regs, error_code, address);
} else {
do_user_addr_fault(regs, error_code, address); // [1]
// [...]
}
}
The __handle_mm_fault() function is internally invoked by do_user_addr_fault(). It wraps fault information into a struct vm_fault object and calls handle_pte_fault() [2].
static inline
void do_user_addr_fault(struct pt_regs *regs,
unsigned long error_code,
unsigned long address)
{
// [...]
tsk = current;
mm = tsk->mm;
// [...]
vma = lock_vma_under_rcu(mm, address);
fault = handle_mm_fault(vma, address, flags | FAULT_FLAG_VMA_LOCK, regs); // <-------
// [...]
}
vm_fault_t handle_mm_fault(struct vm_area_struct *vma, unsigned long address,
unsigned int flags, struct pt_regs *regs)
{
// [...]
else
ret = __handle_mm_fault(vma, address, flags); // <-------
}
static vm_fault_t __handle_mm_fault(struct vm_area_struct *vma,
unsigned long address, unsigned int flags)
{
struct vm_fault vmf = {
.vma = vma,
.address = address & PAGE_MASK,
.real_address = address,
.flags = flags,
.pgoff = linear_page_index(vma, address),
.gfp_mask = __get_fault_gfp_mask(vma),
};
// [...]
return handle_pte_fault(&vmf); // [2]
}
If the PTE of the target address has not yet been loaded into the page table, the function handle_pte_fault() calls do_pte_missing() [3] to handle the PTE fault.
static vm_fault_t handle_pte_fault(struct vm_fault *vmf)
{
// [...]
if (!vmf->pte)
return do_pte_missing(vmf); // [3]
}
static vm_fault_t do_pte_missing(struct vm_fault *vmf)
{
// !vma->vm_ops
if (vma_is_anonymous(vmf->vma))
return do_anonymous_page(vmf);
else
return do_fault(vmf);
}
2. Remote Memory Access
2.1. sys_ptrace
A remote memory access can be triggered using sys_ptrace with the PEEK and POKE APIs, and its execution flow is straightforward.
SYSCALL_DEFINE4(ptrace, long, request, long, pid, unsigned long, addr,
unsigned long, data)
{
struct task_struct *child;
long ret;
// [...]
// find child's task object
child = find_get_task_by_vpid(pid);
// [...]
ret = arch_ptrace(child, request, addr, data); // <-------
}
long arch_ptrace(struct task_struct *child, long request,
unsigned long addr, unsigned long data)
{
switch (request) {
// [...]
default:
ret = ptrace_request(child, request, addr, data); // <-------
break;
}
}
int ptrace_request(struct task_struct *child, long request,
unsigned long addr, unsigned long data)
{
// [...]
switch (request) {
case PTRACE_PEEKTEXT:
case PTRACE_PEEKDATA:
return generic_ptrace_peekdata(child, addr, data); // <-------
// [...]
}
}
int generic_ptrace_peekdata(struct task_struct *tsk, unsigned long addr,
unsigned long data)
{
// [...]
int copied;
copied = ptrace_access_vm(tsk, addr, &tmp, sizeof(tmp), FOLL_FORCE); // <-------
// [...]
}
int ptrace_access_vm(struct task_struct *tsk, unsigned long addr,
void *buf, int len, unsigned int gup_flags)
{
struct mm_struct *mm;
int ret;
mm = get_task_mm(tsk);
// [...]
ret = __access_remote_vm(mm, addr, buf, len, gup_flags); // <-------
mmput(mm);
return ret;
}
The kernel processes this request by internally invoking the __access_remote_vm() function. This function initially attempts to fault in the target page by calling get_user_page_vma_remote() [1]. However, if the page fault is failed, the kernel subsequently invokes the .access handler of the vm operations [2].
int __access_remote_vm(struct mm_struct *mm, unsigned long addr, void *buf,
int len, unsigned int gup_flags)
{
// [...]
// if addr is not in vma and cannot expand, just return
if (!vma_lookup(mm, addr) && !expand_stack(mm, addr))
return 0;
while (len) {
int bytes, offset;
void *maddr;
struct vm_area_struct *vma = NULL;
struct page *page = get_user_page_vma_remote(mm, addr, // [1]
gup_flags, &vma);
// if not found
if (IS_ERR_OR_NULL(page)) {
vma = vma_lookup(mm, addr);
// [...]
if (vma->vm_ops && vma->vm_ops->access)
bytes = vma->vm_ops->access(vma, addr, buf, // [2]
len, write);
// [...]
}
// [...]
}
}
The __get_user_pages_locked() function internally calls __get_user_pages() to attempt to retrieve the target page from the mm object.
static inline struct page *get_user_page_vma_remote(struct mm_struct *mm,
unsigned long addr,
int gup_flags,
struct vm_area_struct **vmap)
{
struct page *page;
struct vm_area_struct *vma;
int got = get_user_pages_remote(mm, addr, 1, gup_flags, &page, NULL); // <-------
// [...]
if (got == 0)
return NULL;
vma = vma_lookup(mm, addr);
*vmap = vma;
return page;
}
long get_user_pages_remote(struct mm_struct *mm,
unsigned long start, unsigned long nr_pages,
unsigned int gup_flags, struct page **pages,
int *locked)
{
// [...]
return __get_user_pages_locked(mm, start, nr_pages, pages, // <-------
locked ? locked : &local_locked,
gup_flags);
}
static __always_inline long __get_user_pages_locked(struct mm_struct *mm,
unsigned long start,
unsigned long nr_pages,
struct page **pages,
int *locked,
unsigned int flags)
{
// [...]
for (;;) {
ret = __get_user_pages(mm, start, nr_pages, flags, pages, // <-------
locked);
}
}
The __get_user_pages() function retrieves the vma object associated with the target address [3] and checks whether the request is valid [4]. If the access request is deemed valid, the kernel invokes faultin_page() [5] to synchronously load the physical page corresponding to the target address into the page table.
static long __get_user_pages(struct mm_struct *mm,
unsigned long start, unsigned long nr_pages,
unsigned int gup_flags, struct page **pages,
int *locked)
{
struct vm_area_struct *vma = NULL;
// [...]
if (!vma || start >= vma->vm_end) {
// get vma (virtual memory area) from mm
vma = gup_vma_lookup(mm, start); // [3]
ret = check_vma_flags(vma, gup_flags); // [4]
if (ret)
goto out;
}
// find page by virt address
page = follow_page_mask(vma, start, foll_flags, &ctx);
if (!page || PTR_ERR(page) == -EMLINK) {
// if not found, try to faultin
ret = faultin_page(vma, start, &foll_flags, // [5]
PTR_ERR(page) == -EMLINK, locked);
// [...]
}
// [...]
}
The execution flow of faultin_page() is similar to the page fault handler asm_exc_page_fault(), as both eventually call handle_mm_fault() [6] to handle the page fault.
static int faultin_page(struct vm_area_struct *vma,
unsigned long address, unsigned int *flags, bool unshare,
int *locked)
{
// [...]
ret = handle_mm_fault(vma, address, fault_flags, NULL); // [6]
// [...]
}
2.2. process_vm_{readv, writev}
Other methods for triggering remote memory access include the system calls process_vm_readv and process_vm_writev. These syscalls are used to transfer data between two processes.
SYSCALL_DEFINE6(process_vm_readv, pid_t, pid, const struct iovec __user *, lvec,
unsigned long, liovcnt, const struct iovec __user *, rvec,
unsigned long, riovcnt, unsigned long, flags)
{
return process_vm_rw(pid, lvec, liovcnt, rvec, riovcnt, flags, 0); // <-------
}
static ssize_t process_vm_rw(pid_t pid,
const struct iovec __user *lvec,
unsigned long liovcnt,
const struct iovec __user *rvec,
unsigned long riovcnt,
unsigned long flags, int vm_write)
{
// [...]
rc = import_iovec(dir, lvec, liovcnt, UIO_FASTIOV, &iov_l, &iter);
iov_r = iovec_from_user(rvec, riovcnt, UIO_FASTIOV, iovstack_r,
in_compat_syscall());
rc = process_vm_rw_core(pid, &iter, iov_r, riovcnt, flags, vm_write); // <-------
// [...]
}
static ssize_t process_vm_rw_core(pid_t pid, struct iov_iter *iter,
const struct iovec *rvec,
unsigned long riovcnt,
unsigned long flags, int vm_write)
{
// [...]
// find child's task object
task = find_get_task_by_vpid(pid);
// get mm from task
mm = mm_access(task, PTRACE_MODE_ATTACH_REALCREDS);
for (i = 0; i < riovcnt && iov_iter_count(iter) && !rc; i++)
rc = process_vm_rw_single_vec( // <-------
(unsigned long)rvec[i].iov_base, rvec[i].iov_len,
iter, process_pages, mm, task, vm_write);
// [...]
}
static int process_vm_rw_single_vec(unsigned long addr,
unsigned long len,
struct iov_iter *iter,
struct page **process_pages,
struct mm_struct *mm,
struct task_struct *task,
int vm_write)
{
// [...]
while (!rc && nr_pages && iov_iter_count(iter)) {
// [...]
// get page objects from given mm
pinned_pages = pin_user_pages_remote(mm, pa, pinned_pages, // <-------
flags, process_pages,
&locked);
// [...]
// read/write target pages
rc = process_vm_rw_pages(process_pages,
start_offset, bytes, iter,
vm_write);
}
// [...]
}
long pin_user_pages_remote(struct mm_struct *mm,
unsigned long start, unsigned long nr_pages,
unsigned int gup_flags, struct page **pages,
int *locked)
{
// [...]
return __gup_longterm_locked(mm, start, nr_pages, pages, // <-------
locked ? locked : &local_locked,
gup_flags);
}
Finally, the syscall handler calls __get_user_pages_locked() to get user pages, which has already been introduced in the 2.1. ptrace section.
static long __gup_longterm_locked(struct mm_struct *mm,
unsigned long start,
unsigned long nr_pages,
struct page **pages,
int *locked,
unsigned int gup_flags)
{
if (!(gup_flags & FOLL_LONGTERM))
return __get_user_pages_locked(mm, start, nr_pages, pages, // <-------
locked, gup_flags);
// [...]
}
2.3. /proc/$pid/mem
The third method for accessing remote memory involves reading from or writing to the file /proc/$pid/mem. The kernel variable tid_base_stuff[] determines the file permissions and operation table.
static const struct pid_entry tid_base_stuff[] = {
// [...]
REG("mem", S_IRUSR|S_IWUSR, proc_mem_operations),
// [...]
};
static const struct file_operations proc_mem_operations = {
.llseek = mem_lseek,
.read = mem_read,
.write = mem_write,
.open = mem_open,
.release = mem_release,
};
When opening this file, the .open handler mem_open() internally calls the function proc_mem_open(). This function then invokes mm_access() [1] to retrieve the mm object from the target process.
static int __mem_open(struct inode *inode, struct file *file, unsigned int mode)
{
struct mm_struct *mm = proc_mem_open(inode, mode); // <-------
// [...]
// assign mm object of target process to file private data
file->private_data = mm;
return 0;
}
struct mm_struct *proc_mem_open(struct inode *inode, unsigned int mode)
{
struct task_struct *task = get_proc_task(inode);
struct mm_struct *mm = ERR_PTR(-ESRCH);
if (task) {
mm = mm_access(task, mode | PTRACE_MODE_FSCREDS); // [1]
put_task_struct(task);
// [...]
}
return mm;
}
The function __access_remote_vm() is invoked when reading from or writing to this file. It is used for accessing remote memory and is also discussed in the 2.1. ptrace section.
static ssize_t mem_read(struct file *file, char __user *buf,
size_t count, loff_t *ppos)
{
return mem_rw(file, buf, count, ppos, 0); // <-------
}
static ssize_t mem_rw(struct file *file, char __user *buf,
size_t count, loff_t *ppos, int write)
{
struct mm_struct *mm = file->private_data;
unsigned long addr = *ppos;
ssize_t copied;
char *page;
unsigned int flags;
// [...]
page = (char *)__get_free_page(GFP_KERNEL);
// [...]
while (count > 0) {
// [...]
this_len = access_remote_vm(mm, addr, page, this_len, flags); // <-------
// [...]
}
*ppos = addr;
mmput(mm);
free:
free_page((unsigned long) page);
return copied;
}
int access_remote_vm(struct mm_struct *mm, unsigned long addr,
void *buf, int len, unsigned int gup_flags)
{
return __access_remote_vm(mm, addr, buf, len, gup_flags); // <-------
}
2.4. Validation Helper
Almost all methods call the functions mm_access() and check_vma_flags() to validate access requests.
The function mm_access() internally calls __ptrace_may_access() to verify access modes, namespace capabilities, and identifiers.
struct mm_struct *mm_access(struct task_struct *task, unsigned int mode)
{
struct mm_struct *mm;
int err;
err = down_read_killable(&task->signal->exec_update_lock);
mm = get_task_mm(task);
if (mm && mm != current->mm && !ptrace_may_access(task, mode)) { // <-------
mmput(mm);
mm = ERR_PTR(-EACCES);
}
up_read(&task->signal->exec_update_lock);
return mm;
}
bool ptrace_may_access(struct task_struct *task, unsigned int mode)
{
int err;
task_lock(task);
err = __ptrace_may_access(task, mode); // <-------
task_unlock(task);
return !err;
}
The function check_vma_flags() verifies whether the virtual memory is permitted to handle faults during remote access. For instance, it prevents access to MMIO mappings of another process.
static int check_vma_flags(struct vm_area_struct *vma, unsigned long gup_flags)
{
vm_flags_t vm_flags = vma->vm_flags;
// [...]
if (vm_flags & (VM_IO | VM_PFNMAP))
return -EFAULT;
// [...]
}
In a nutshell, mm_access() performs process-layer validation, while check_vma_flags() handles memory-layer validation.
3. Conclusion
The illustration of the entire execution flow for local and remote memory access is shown below.
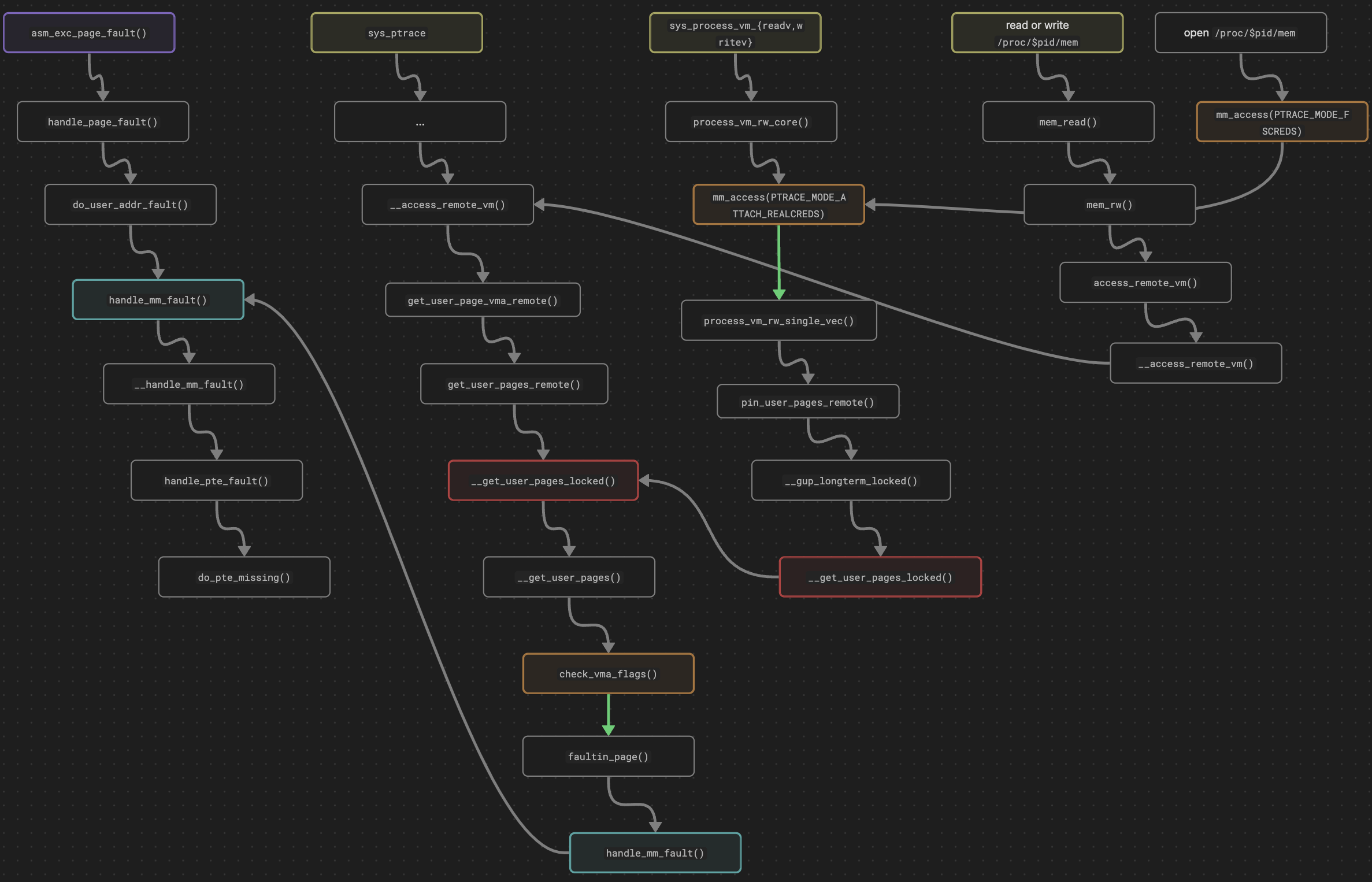
When the kernel handles a remote memory access, it first attempts to retrieve the page object associated with the address from the target process. If the page does not exist, the kernel invokes validation functions (mm_access() and check_vma_flags()) to filter out invalid requests.
Next, it retrieves the mm object of the target process and calls the page fault handling function handle_mm_fault(), which is also invoked by the #PF handler.
Bonus. Copy-On-Write
When I set out to understand how remote memory access works, a question arose: Could remote memory access trigger Copy-On-Write (COW), and how is COW managed in Linux? The answer is that there is probably no difference between remote and local access in this regard. However, I still want to note down how the COW mechanism is designed.
When a child process is forked or a new namespace is unshared, the kernel function dup_mmap() is invoked to duplicate memory-related objects. The page table duplication is handled by the copy_page_range() function [1].
static __latent_entropy int dup_mmap(struct mm_struct *mm,
struct mm_struct *oldmm)
{
struct vm_area_struct *mpnt, *tmp;
VMA_ITERATOR(old_vmi, oldmm, 0);
// [...]
for_each_vma(old_vmi, mpnt) {
// [...]
tmp = vm_area_dup(mpnt);
// [...]
retval = copy_page_range(tmp, mpnt); // [1]
// [...]
}
// [...]
}
This function copies all page information, from p4d to pte, to the child process and ultimately calls copy_pte_range().
int
copy_page_range(struct vm_area_struct *dst_vma, struct vm_area_struct *src_vma)
{
unsigned long addr = src_vma->vm_start;
unsigned long end = src_vma->vm_end;
struct mm_struct *dst_mm = dst_vma->vm_mm;
struct mm_struct *src_mm = src_vma->vm_mm;
// [...]
dst_pgd = pgd_offset(dst_mm, addr);
src_pgd = pgd_offset(src_mm, addr);
do {
next = pgd_addr_end(addr, end);
// [...]
// iterate p4d --> pud --> pmd --> pte
copy_p4d_range(dst_vma, src_vma, dst_pgd, src_pgd, addr, next);
// [...]
} while (/* ... */);
// [...]
}
The function copy_pte_range() then calls copy_present_pte() [2] to copy the PTEs. During the copying process, copy_present_pte() checks whether the target PTE is a COW mapping. If it is, the function clears the R/W bit for both the parent [3] and child [4] PTEs.
static int
copy_pte_range(struct vm_area_struct *dst_vma, struct vm_area_struct *src_vma,
pmd_t *dst_pmd, pmd_t *src_pmd, unsigned long addr,
unsigned long end)
{
// [...]
dst_pte = pte_alloc_map_lock(dst_mm, dst_pmd, addr, &dst_ptl);
src_pte = pte_offset_map_nolock(src_mm, src_pmd, addr, &src_ptl);
// [...]
do {
ret = copy_present_pte(dst_vma, src_vma, dst_pte, src_pte, // [2]
addr, rss, &prealloc);
} while (/*...*/);
// [...]
}
static inline int
copy_present_pte(struct vm_area_struct *dst_vma, struct vm_area_struct *src_vma,
pte_t *dst_pte, pte_t *src_pte, unsigned long addr, int *rss,
struct folio **prealloc)
{
// [...]
if (is_cow_mapping(vm_flags) && pte_write(pte)) {
// set src PTE non-writable
ptep_set_wrprotect(src_mm, addr, src_pte); // [3]
// set dst PTE non-writable
pte = pte_wrprotect(pte); // [4]
}
// [...]
}
static inline bool is_cow_mapping(vm_flags_t flags)
{
// may write but not shared
return (flags & (VM_SHARED | VM_MAYWRITE)) == VM_MAYWRITE;
}
static inline int pte_write(pte_t pte)
{
// writable
return (pte_flags(pte) & _PAGE_RW) || /*...*/;
}
When either the parent or child attempts to write to a COW page, the page fault handling function handle_pte_fault() invokes wp_page_copy() [5] to create a copy of the page.
static vm_fault_t handle_pte_fault(struct vm_fault *vmf)
{
// [...]
vmf->pte = pte_offset_map_nolock(vmf->vma->vm_mm, vmf->pmd,
vmf->address, &vmf->ptl);
vmf->orig_pte = ptep_get_lockless(vmf->pte);
// [...]
// write a protected page
if (vmf->flags & (FAULT_FLAG_WRITE|FAULT_FLAG_UNSHARE)) {
if (!pte_write(entry))
return do_wp_page(vmf); // <-------
}
}
static vm_fault_t do_wp_page(struct vm_fault *vmf)
__releases(vmf->ptl)
{
// [...]
vmf->page = vm_normal_page(vma, vmf->address, vmf->orig_pte);
if (vmf->page)
folio = page_folio(vmf->page);
// [...]
// duplicate a new PTE to target process
return wp_page_copy(vmf); // [5]
}
Finally, the kernel successfully duplicates a new page for the parent or child process from a COW page.