Two Network-related vunlnerabilities Analysis
In this post, I will introduce two network-related vulnerabilities in Linux kernel. Both are exploited in kCTF or kernelCTF and quite interesting – Enjoy!
1. CVE-2023-6932
The patch commit can be found here.
1.1. IP Packet
When sending data through a raw socket, the raw_sendmsg() function is called. This function first retrieves the routing table using ip_route_output_flow() [1], and then transmits IP frames via ip_push_pending_frames() [2].
static int raw_sendmsg(struct sock *sk, struct msghdr *msg, size_t len)
{
struct rtable *rt;
// [...]
rt = ip_route_output_flow(net, &fl4, sk); // [1]
// [...]
else {
// [...]
lock_sock(sk);
// append payload to packet with routing table
err = ip_append_data(sk, &fl4, raw_getfrag,
&rfv, len, 0,
&ipc, &rt, msg->msg_flags);
// [...]
err = ip_push_pending_frames(sk, &fl4); // [2]
// [...]
release_sock(sk);
}
}
If the routing table does not exist, the __mkroute_output() function [3] is called to create one.
struct rtable *ip_route_output_flow(struct net *net, struct flowi4 *flp4,
const struct sock *sk)
{
struct rtable *rt = __ip_route_output_key(net, flp4); // <----------
// [...]
return rt;
}
static inline struct rtable *__ip_route_output_key(struct net *net,
struct flowi4 *flp)
{
return ip_route_output_key_hash(net, flp, NULL); // <----------
}
struct rtable *ip_route_output_key_hash(struct net *net, struct flowi4 *fl4,
const struct sk_buff *skb)
{
struct fib_result res = {
.type = RTN_UNSPEC,
.fi = NULL,
.table = NULL,
.tclassid = 0,
};
struct rtable *rth;
// [...]
rcu_read_lock();
rth = ip_route_output_key_hash_rcu(net, fl4, &res, skb); // <----------
rcu_read_unlock();
return rth;
}
struct rtable *ip_route_output_key_hash_rcu(struct net *net, struct flowi4 *fl4,
struct fib_result *res,
const struct sk_buff *skb)
{
// [...]
make_route:
rth = __mkroute_output(res, fl4, orig_oif, dev_out, flags); // [3]
return rth;
}
The __mkroute_output() function determines the routing table type based on the destination IP address. For instance, if the destination IP address is a broadcast IP, the corresponding routing table type is RTN_BROADCAST [4]. The function then calls rt_dst_alloc() to allocate a new struct rtable object [5].
static struct rtable *__mkroute_output(const struct fib_result *res,
const struct flowi4 *fl4, int orig_oif,
struct net_device *dev_out,
unsigned int flags)
{
struct rtable *rth;
u16 type = res->type;
// [...]
if (ipv4_is_lbcast(fl4->daddr)) // [4]
type = RTN_BROADCAST;
else if (ipv4_is_multicast(fl4->daddr))
type = RTN_MULTICAST;
// [...]
// [...]
rth = rt_dst_alloc(dev_out, flags, type, // [5]
IN_DEV_ORCONF(in_dev, NOPOLICY),
IN_DEV_ORCONF(in_dev, NOXFRM));
// [...]
return rth;
}
The default output handler for a new routing table is ip_output() [6]. Additionally, if the destination IP is a local IP, the input handler will be set to ip_local_deliver() [7]
struct rtable *rt_dst_alloc(struct net_device *dev,
unsigned int flags, u16 type,
bool nopolicy, bool noxfrm)
{
rt = dst_alloc(&ipv4_dst_ops, dev, 1, DST_OBSOLETE_FORCE_CHK,
(nopolicy ? DST_NOPOLICY : 0) |
(noxfrm ? DST_NOXFRM : 0));
// [...]
rt->dst.output = ip_output; // [6]
if (flags & RTCF_LOCAL)
rt->dst.input = ip_local_deliver; // [7]
// [...]
}
Once the sk object is initialized with the retrieved routing table, the ip_push_pending_frames() is called to send the packet.
int ip_push_pending_frames(struct sock *sk, struct flowi4 *fl4)
{
struct sk_buff *skb;
// combine all pending IP fragments on the socket as one IP datagram
skb = ip_finish_skb(sk, fl4);
return ip_send_skb(sock_net(sk), skb); // <----------
}
int ip_send_skb(struct net *net, struct sk_buff *skb)
{
int err;
// from local machine to outside
err = ip_local_out(net, skb->sk, skb); // <----------
// [...]
}
int ip_local_out(struct net *net, struct sock *sk, struct sk_buff *skb)
{
int err;
// call the NF hook if there is one
err = __ip_local_out(net, sk, skb);
err = dst_output(net, sk, skb); // <----------
return err;
}
The dst_output() function invokes the output handler of the current packet’s routing table, which is initialized to ip_output() in the rt_dst_alloc(), to transmit the packet at the IP layer.
static inline int dst_output(struct net *net, struct sock *sk, struct sk_buff *skb)
{
return skb_dst(skb)->output(net, sk, skb); // ip_output()
}
The ip_output() function internally invokes neigh_output() [8] with softirqs disabled. The softirqs are disabled and enabled respectively by functions rcu_read_lock_bh() [9] and rcu_read_unlock_bh() [10].
int ip_output(struct net *net, struct sock *sk, struct sk_buff *skb)
{
// [...]
return NF_HOOK_COND(NFPROTO_IPV4, NF_INET_POST_ROUTING,
net, sk, skb, indev, dev,
ip_finish_output, // <----------
!(IPCB(skb)->flags & IPSKB_REROUTED));
}
static int ip_finish_output(struct net *net, struct sock *sk, struct sk_buff *skb)
{
int ret;
switch (ret) {
case NET_XMIT_SUCCESS:
return __ip_finish_output(net, sk, skb); // <----------
// [...]
}
}
static int __ip_finish_output(struct net *net, struct sock *sk, struct sk_buff *skb)
{
// [...]
return ip_finish_output2(net, sk, skb); // <----------
}
static int ip_finish_output2(struct net *net, struct sock *sk, struct sk_buff *skb)
{
rcu_read_lock_bh(); // [9]
// [...]
res = neigh_output(neigh, skb, is_v6gw); // [8]
rcu_read_unlock_bh(); // [10]
}
static inline void rcu_read_lock_bh(void)
{
local_bh_disable();
// [...]
}
static inline void rcu_read_unlock_bh(void)
{
// [...]
local_bh_enable();
}
The neigh_output() function calls neigh_hh_output() to update the skb data buffer [11] and transmit the packet [12].
static inline int neigh_output(struct neighbour *n, struct sk_buff *skb,
bool skip_cache)
{
const struct hh_cache *hh = &n->hh;
// [...]
return neigh_hh_output(hh, skb);
}
static inline int neigh_hh_output(const struct hh_cache *hh, struct sk_buff *skb)
{
// [...]
// make room for new data from start of buffer
__skb_push(skb, hh_len); // [11]
return dev_queue_xmit(skb); // [12]
}
1.2. Softirq
Once the softirqs are re-enabled, the do_softirq() function is called to handle any pending requests [1].
static inline void local_bh_enable(void)
{
__local_bh_enable_ip(_THIS_IP_, SOFTIRQ_DISABLE_OFFSET);
}
void __local_bh_enable_ip(unsigned long ip, unsigned int cnt)
{
// [...]
if (unlikely(!in_interrupt() && local_softirq_pending())) {
do_softirq(); // [1]
}
// [...]
}
The do_softirq() function iterates the pending bits and calls the corresponding IRQ action handlers [2] on the hardirq stack [3].
asmlinkage __visible void do_softirq(void)
{
__u32 pending;
// [...]
pending = local_softirq_pending();
if (pending && !ksoftirqd_running(pending))
do_softirq_own_stack(); // <----------
}
void do_softirq_own_stack(void)
{
run_on_irqstack_cond(__do_softirq, NULL); // <----------
}
static __always_inline void run_on_irqstack_cond(void (*func)(void),
struct pt_regs *regs)
{
if (irq_needs_irq_stack(regs))
__run_on_irqstack(func); // <----------
// [...]
}
static __always_inline void __run_on_irqstack(void (*func)(void))
{
void *tos = __this_cpu_read(hardirq_stack_ptr);
// call __do_softirq() in hardirq stack
asm_call_on_stack(tos - 8, func, NULL); // [3]
}
asmlinkage __visible void __softirq_entry __do_softirq(void)
{
h = softirq_vec;
while ((softirq_bit = ffs(pending))) {
h += softirq_bit - 1;
// [...]
h->action(h); // [2]
// [...]
h++;
pending >>= softirq_bit;
}
}
Because the packet transmission generates a softirq, the receive handler of the target network device will be invoked.
1.3. IGMP Protocol
If a network device receives IP packets, the ip_rcv() function is called first, which indirectly invokes the input handler of the routing table [1]. During the allocation process, the input handler is initialized to ip_local_deliver(). The details of allocation process can be found in the rt_dst_alloc() function.
int ip_rcv(struct sk_buff *skb, struct net_device *dev, struct packet_type *pt,
struct net_device *orig_dev)
{
struct net *net = dev_net(dev);
skb = ip_rcv_core(skb, net);
return NF_HOOK(NFPROTO_IPV4, NF_INET_PRE_ROUTING,
net, NULL, skb, dev, NULL,
ip_rcv_finish); // <----------
}
static int ip_rcv_finish(struct net *net, struct sock *sk, struct sk_buff *skb)
{
struct net_device *dev = skb->dev;
int ret;
// [...]
ret = ip_rcv_finish_core(net, sk, skb, dev, NULL);
ret = dst_input(skb); // <----------
return ret;
}
static inline int dst_input(struct sk_buff *skb)
{
return skb_dst(skb)->input(skb); // [1] ip_local_deliver()
}
The ip_protocol_deliver_rcu() function is then called with RCU read lock acquired. If the protocol of these packets is IGMP, the igmp_rcv() function [2] is called to receive packets.
int ip_local_deliver(struct sk_buff *skb)
{
struct net *net = dev_net(skb->dev);
// [...]
return NF_HOOK(NFPROTO_IPV4, NF_INET_LOCAL_IN,
net, NULL, skb, skb->dev, NULL,
ip_local_deliver_finish); // <----------
}
static int ip_local_deliver_finish(struct net *net, struct sock *sk, struct sk_buff *skb)
{
// [...]
rcu_read_lock();
ip_protocol_deliver_rcu(net, skb, ip_hdr(skb)->protocol); // <----------
rcu_read_unlock();
return 0;
}
void ip_protocol_deliver_rcu(struct net *net, struct sk_buff *skb, int protocol)
{
const struct net_protocol *ipprot;
// [...]
ipprot = rcu_dereference(inet_protos[protocol]);
if (ipprot) {
// [...]
ret = INDIRECT_CALL_2(ipprot->handler, tcp_v4_rcv, udp_rcv, // <----------
skb);
// [...]
}
}
static const struct net_protocol igmp_protocol = {
.handler = igmp_rcv, // [2]
.netns_ok = 1,
};
Internet Group Management Protocol (IGMP) is a communication protocol used in the IPv4 for managing multicast group memberships. If the request type is IGMP_HOST_MEMBERSHIP_QUERY, the kernel dispatches this request to igmp_heard_query() [3].
int igmp_rcv(struct sk_buff *skb)
{
struct net_device *dev = skb->dev;
struct in_device *in_dev;
// [...]
ih = igmp_hdr(skb);
switch (ih->type) {
case IGMP_HOST_MEMBERSHIP_QUERY:
dropped = igmp_heard_query(in_dev, skb, len); // [3]
break;
// [...]
}
}
The membership query is used to discover which host groups have members on their attached local networks. After the igmp_heard_query() function processes this query, it may need to update the timers of other sockets [4].
static bool igmp_heard_query(struct in_device *in_dev, struct sk_buff *skb,
int len)
{
struct ip_mc_list *im;
struct igmpv3_query *ih3 = igmpv3_query_hdr(skb);
// [...]
rcu_read_lock();
for_each_pmc_rcu(in_dev, im) {
changed = !im->gsquery ||
igmp_marksources(im, ntohs(ih3->nsrcs), ih3->srcs);
// [...]
if (changed)
igmp_mod_timer(im, max_delay); // [4]
}
rcu_read_unlock();
// [...]
}
The igmp_start_timer() function starts the timer [5] while holding a lock [6], and increments its refcount without any checks [7]. The refcount of a struct ip_mc_list object is updated only during the addition or deletion of a timer.
static void igmp_mod_timer(struct ip_mc_list *im, int max_delay)
{
spin_lock_bh(&im->lock); // [6]
// [...]
igmp_start_timer(im, max_delay); // [5]
spin_unlock_bh(&im->lock);
}
static void igmp_start_timer(struct ip_mc_list *im, int max_delay)
{
int tv = prandom_u32() % max_delay;
im->tm_running = 1;
if (!mod_timer(&im->timer, jiffies+tv+2))
refcount_inc(&im->refcnt); // [7]
}
However, the lock &im->lock is primarily acquired when updating the timer. For example, the ip_ma_put() function is invoked without requiring the lock when the device goes down and leaves the multicast group. This function decrements the refcount [8], and calls RCU free callback when the refcount drops to zero [9].
static void ip_ma_put(struct ip_mc_list *im)
{
if (refcount_dec_and_test(&im->refcnt)) { // [8]
in_dev_put(im->interface);
kfree_rcu(im, rcu); // [9]
}
}
When the ip_ma_put() and igmp_start_timer() functions are called concurrently, the igmp_start_timer() function does not verify whether the refcount is zero before starting the timer.
This can result in a UAF if the timer is triggered after the RCU callback has already released the struct ip_mc_list object.
1.4. Patch
After being patched, the igmp_start_timer() function now checks the refcount before starting the timer.
--- a/net/ipv4/igmp.c
+++ b/net/ipv4/igmp.c
@@ -216,8 +216,10 @@ static void igmp_start_timer(struct ip_mc_list *im, int max_delay)
// [...]
- if (!mod_timer(&im->timer, jiffies+tv+2))
- refcount_inc(&im->refcnt);
+ if (refcount_inc_not_zero(&im->refcnt)) {
+ if (mod_timer(&im->timer, jiffies + tv + 2))
+ ip_ma_put(im);
+ }
2. CVE-2023-0461
The patch commit can be found here.
2.1. Socket Create
The sys_socket calls __sock_create() to create a sock object [1]. The sock object is then initialized by the creation handler of family ops [2].
int __sock_create(struct net *net, int family, int type, int protocol,
struct socket **res, int kern)
{
struct socket *sock;
sock = sock_alloc(); // [1]
sock->type = type;
// [...]
pf = rcu_dereference(net_families[family]);
// [...]
err = pf->create(net, sock, protocol, kern); // [2]
}
All types of family ops are listed below:
alg_family
atalk_family_ops
pvc_family_ops
svc_family_ops
ax25_family_ops
bt_sock_family_ops
caif_family_ops
can_family_ops
ieee802154_family_ops
inet_family_ops
inet6_family_ops
iucv_sock_family_ops
kcm_family_ops
pfkey_family_ops
llc_ui_family_ops
mctp_pf
netlink_family_ops
nr_family_ops
nfc_sock_family_ops
packet_family_ops
phonet_proto_family
qrtr_family
rds_family_ops
rose_family_ops
rxrpc_family_ops
smc_sock_family_ops
tipc_family_ops
unix_family_ops
vsock_family_ops
x25_family_ops
xsk_family_ops
If the family is AF_INET, the inet_create() function [3], which serves the as creation handler for inet family, is called.
static const struct net_proto_family inet_family_ops = {
.family = PF_INET,
.create = inet_create, // [3]
// [...]
};
A inet_protosw object wraps the protocol handler with type information. The inet_create() iterates the &inetsw[type] protocol array [4] to locate the correspoinding inet_protosw object [5]. This function creates a sock object and initialize it with the protocol handler [6]. Finally, it calls the initialization handler of the protocol ops [7].
static int inet_create(struct net *net, struct socket *sock, int protocol,
int kern)
{
struct sock *sk;
struct inet_protosw *answer;
struct proto *answer_prot;
// [...]
list_for_each_entry_rcu(answer, &inetsw[sock->type] /* [4] */, list) {
// [5]
if (protocol == answer->protocol) {
// [...]
} else {
// [...]
}
}
sock->ops = answer->ops; // type ops
answer_prot = answer->prot;
// [...]
sk = sk_alloc(net, PF_INET, GFP_KERNEL, answer_prot, kern); // [6]
// sk->sk_prot will be assigned to &answer_prot
sk->sk_protocol = protocol;
// [...]
if (sk->sk_prot->init) {
err = sk->sk_prot->init(sk); // [7]
// [...]
}
}
All types of socket type are listed below:
enum sock_type {
SOCK_STREAM = 1,
SOCK_DGRAM = 2,
SOCK_RAW = 3,
SOCK_RDM = 4,
SOCK_SEQPACKET = 5,
SOCK_DCCP = 6,
SOCK_PACKET = 10,
};
#define SOCK_MAX (SOCK_PACKET + 1)
For a TCP (i.e. the type is SOCK_STREAM) socket, the corresponding inet_protosw object is the first entry in the inetsw_array[] array [8], and the type ops will be inet_stream_ops [9].
static struct inet_protosw inetsw_array[] =
{
// [8]
{
.type = SOCK_STREAM,
.protocol = IPPROTO_TCP,
.prot = &tcp_prot,
.ops = &inet_stream_ops, // [9]
// [...]
},
// [...]
};
The high-level hierarchy of family, type, and protocol can be structured as follows:
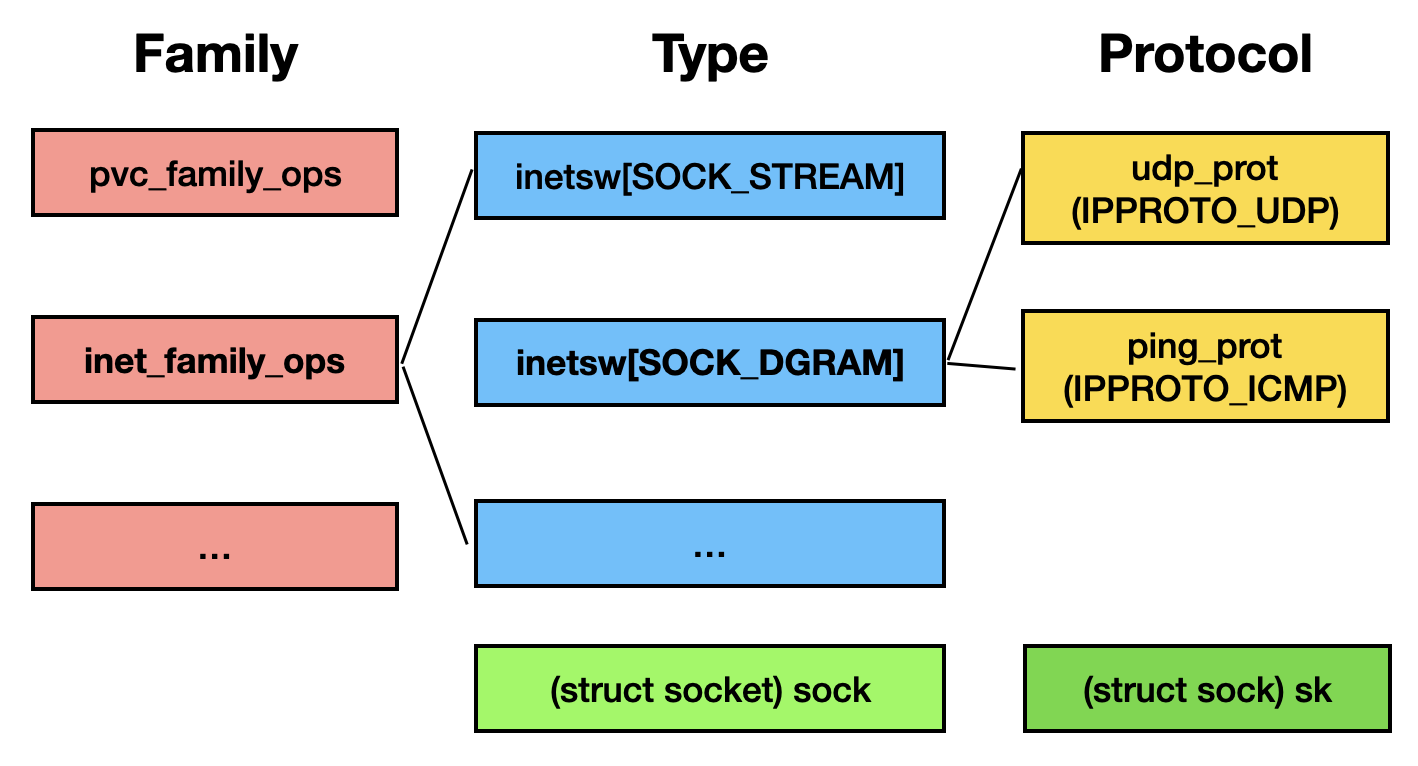
2.2. Socket Listen
The sys_listen moves a socket into listening state. As the type ops of a STREAM socket is &inet_stream_ops, the listen handler inet_listen() is called [1].
SYSCALL_DEFINE2(listen, int, fd, int, backlog)
{
return __sys_listen(fd, backlog);
}
int __sys_listen(int fd, int backlog)
{
struct socket *sock;
// [...]
if (sock) {
// sock->ops == &inet_stream_ops
err = sock->ops->listen(sock, backlog); // [1]
// [...]
}
return err;
}
const struct proto_ops inet_stream_ops = {
.family = PF_INET,
// [...]
.listen = inet_listen, // [1]
// [...]
};
The inet_listen() function verifies the socket’s state. First, it ensures this socket is a STREAM (i.e. TCP) socket and is in an unconnected state [2]. Next, it ensures the TCP socket is either in CLOSE or LISTEN state [3]. Finally, the inet_csk_listen_start() function is called to switch the socket’s TCP state from CLOSE to LISTEN.
int inet_listen(struct socket *sock, int backlog)
{
struct sock *sk = sock->sk;
unsigned char old_state;
lock_sock(sk);
// [...]
if (sock->state != SS_UNCONNECTED || sock->type != SOCK_STREAM) // [2]
goto out;
old_state = sk->sk_state;
if (!((1 << old_state) & (TCPF_CLOSE | TCPF_LISTEN))) // [3]
goto out;
if (old_state != TCP_LISTEN) {
// [...]
err = inet_csk_listen_start(sk); // [4]
}
return err;
}
The inet_csk_listen_start() function sets the socket’s TCP state to TCP_LISTEN.
int inet_csk_listen_start(struct sock *sk)
{
struct inet_connection_sock *icsk = inet_csk(sk);
// [...]
reqsk_queue_alloc(&icsk->icsk_accept_queue);
// set `sk->sk_state` to `TCP_LISTEN`
inet_sk_state_store(sk, TCP_LISTEN);
// [...]
}
2.3. Socket Accept
The do_accept() function is invoked to accept a new network connection. It first duplicates the socket object [1] and then calls the accept handler of type ops [2].
struct file *do_accept(struct file *file, unsigned file_flags,
struct sockaddr __user *upeer_sockaddr,
int __user *upeer_addrlen, int flags)
{
struct socket *sock, *newsock;
sock = sock_from_file(file);
// [1]
newsock = sock_alloc();
newsock->type = sock->type;
newsock->ops = sock->ops;
newfile = sock_alloc_file(newsock, flags, sock->sk->sk_prot_creator->name);
err = sock->ops->accept(sock, newsock, sock->file->f_flags | file_flags, // [2]
false);
// [...]
return newfile;
}
The inet_accept() function is be called when the socket is a STREAM type. It invokes the accept handler of protocol ops [3] and sets the state of the new socket to CONNECTED [4].
int inet_accept(struct socket *sock, struct socket *newsock, int flags,
bool kern)
{
struct sock *sk1 = sock->sk, *sk2;
int err = -EINVAL;
sk2 = READ_ONCE(sk1->sk_prot)->accept(sk1, flags, &err, kern); // [3]
// [...]
newsock->state = SS_CONNECTED; // [4]
// [...]
return err;
}
The the accept handler of a TCP protocol is inet_csk_accept() [5]. If the request socket queue is empty, it waits for a connection [6]. When new connections are present in the queue, this function retrieves the request result from the queue [7].
struct proto tcp_prot = {
.name = "TCP",
// [...]
.accept = inet_csk_accept, // [5]
// [...]
};
struct sock *inet_csk_accept(struct sock *sk, int flags, int *err, bool kern)
{
struct request_sock *req;
// [...]
if (sk->sk_state != TCP_LISTEN)
goto out_err;
if (reqsk_queue_empty(queue)) { // [6]
// [...]
error = inet_csk_wait_for_connect(sk, timeo);
}
// [...]
req = reqsk_queue_remove(queue, sk); // [7]
newsk = req->sk;
// [...]
return newsk;
}
2.4. TCP Receive
The tcp_v4_rcv() function is called to do TCP handshake in the softirq context. Most of the unnecessary code details are omitted here.
int tcp_v4_rcv(struct sk_buff *skb)
{
// [...]
if (sk->sk_state == TCP_NEW_SYN_RECV) {
struct request_sock *req = inet_reqsk(sk);
// [...]
sk = req->rsk_listener;
// [...]
nsk = tcp_check_req(sk, skb, req, false, &req_stolen); // <----------
// [...]
}
}
struct sock *tcp_check_req(struct sock *sk, struct sk_buff *skb,
struct request_sock *req,
bool fastopen, bool *req_stolen)
{
// [...]
child = inet_csk(sk)->icsk_af_ops->syn_recv_sock(sk, skb, req, NULL,
req, &own_req); // <----------
// [...]
}
const struct inet_connection_sock_af_ops ipv4_specific = {
// [...]
.syn_recv_sock = tcp_v4_syn_recv_sock, // <----------
// [...]
}
struct sock *tcp_v4_syn_recv_sock(const struct sock *sk, struct sk_buff *skb,
struct request_sock *req,
struct dst_entry *dst,
struct request_sock *req_unhash,
bool *own_req)
{
// [...]
newsk = tcp_create_openreq_child(sk, req, skb); // <----------
// [...]
return newsk;
}
struct sock *tcp_create_openreq_child(const struct sock *sk,
struct request_sock *req,
struct sk_buff *skb)
{
struct sock *newsk = inet_csk_clone_lock(sk, req, GFP_ATOMIC); // <----------
// [...]
return newsk;
}
The inet_csk_clone_lock() function is called after the TCP handshake process is completed. It allocates a new sock object [1] as a child socket and invokes the clone handler of the ULP ops [2], if it exists.
struct sock *inet_csk_clone_lock(const struct sock *sk,
const struct request_sock *req,
const gfp_t priority)
{
struct sock *newsk = sk_clone_lock(sk, priority); // [1]
// [...]
inet_clone_ulp(req, newsk, priority); // <----------
return newsk;
}
static void inet_clone_ulp(const struct request_sock *req, struct sock *newsk,
const gfp_t priority)
{
struct inet_connection_sock *icsk = inet_csk(newsk);
if (!icsk->icsk_ulp_ops)
return;
if (icsk->icsk_ulp_ops->clone)
icsk->icsk_ulp_ops->clone(req, newsk, priority); // [2]
}
After that, the waiting accept operation is awakened and returns the fd of the child socket to userspace.
2.5. ULP (Upper Layer Protocol)
An ULP refers to the higher-level protocols or subsystems that operate above the transport layer in the network stack. These protocols interface with the transport layer (such as TCP or UDP) to provide more specialized functionality to applications.
A TCP socket can set the TLS ULP by sys_setsockopt() with TCP_ULP as the option, which internally triggers the tcp_set_ulp() function [1].
int do_tcp_setsockopt(struct sock *sk, int level, int optname,
sockptr_t optval, unsigned int optlen)
{
switch (optname) {
case TCP_ULP:
// [...]
err = tcp_set_ulp(sk, name); // [1]
// [...]
}
}
The tcp_set_ulp() function first retrieves the ULP ops [2] and then invokes the initialization handler [3].
int tcp_set_ulp(struct sock *sk, const char *name)
{
const struct tcp_ulp_ops *ulp_ops;
ulp_ops = __tcp_ulp_find_autoload(name); // [2]
return __tcp_set_ulp(sk, ulp_ops); // <----------
}
static int __tcp_set_ulp(struct sock *sk, const struct tcp_ulp_ops *ulp_ops)
{
struct inet_connection_sock *icsk = inet_csk(sk);
err = ulp_ops->init(sk); // [3]
icsk->icsk_ulp_ops = ulp_ops;
return 0;
}
The tcp_ulp_find() function iterates the tcp_ulp_list variable [4], which links all TCP ULPs, to find the corresponding ULP ops based on the given name [5].
static const struct tcp_ulp_ops *__tcp_ulp_find_autoload(const char *name)
{
const struct tcp_ulp_ops *ulp = NULL;
ulp = tcp_ulp_find(name); // <----------
// [...]
return ulp;
}
static struct tcp_ulp_ops *tcp_ulp_find(const char *name)
{
struct tcp_ulp_ops *e;
list_for_each_entry_rcu(e, &tcp_ulp_list, list, // [4]
lockdep_is_held(&tcp_ulp_list_lock)) {
if (strcmp(e->name, name) == 0) // [5]
return e;
}
return NULL;
}
A TCP ULP can register its ops to the tcp_ulp_list linked list using tcp_register_ulp().
int tcp_register_ulp(struct tcp_ulp_ops *ulp)
{
int ret = 0;
// [...]
list_add_tail_rcu(&ulp->list, &tcp_ulp_list);
return ret;
}
All types of ULP are listed below:
subflow_ulp_ops
smc_ulp_ops
tcp_tls_ulp_ops
espintcp_ulp
2.6. TLS
When setting a TCP socket with the TLS ULP, the initialization handler tls_init() is invoked [1]. This function allocates a tls_context object [2] and assigns it to the ULP data field [3].
static struct tcp_ulp_ops tcp_tls_ulp_ops __read_mostly = {
.name = "tls",
.init = tls_init, // [1]
// [...]
};
static int tls_init(struct sock *sk)
{
struct tls_context *ctx;
// [...]
ctx = tls_ctx_create(sk); // <----------
// [...]
}
struct tls_context *tls_ctx_create(struct sock *sk)
{
struct inet_connection_sock *icsk = inet_csk(sk);
struct tls_context *ctx;
ctx = kzalloc(sizeof(*ctx), GFP_ATOMIC); // [2]
// [...]
rcu_assign_pointer(icsk->icsk_ulp_data, ctx); // [3]
// [...]
}
When a TLS socket is closed, the refcount of the sock object may drop to zero, triggering a call to tls_sk_proto_close() to destruct the ULP object. It gets the tls_context object from the sk’s ULP data icsk->icsk_ulp_data [4] and then frees it by RCU [5].
static void tls_sk_proto_close(struct sock *sk, long timeout)
{
struct tls_context *ctx = tls_get_ctx(sk);
// [...]
if (free_ctx)
tls_ctx_free(sk, ctx);
}
void tls_ctx_free(struct sock *sk, struct tls_context *ctx)
{
// [...]
if (sk)
kfree_rcu(ctx, rcu); // [5]
else
kfree(ctx);
}
static inline struct tls_context *tls_get_ctx(const struct sock *sk)
{
struct inet_connection_sock *icsk = inet_csk(sk);
return (__force void *)icsk->icsk_ulp_data; // [4]
}
2.7. Root Cause
When the inet_csk_clone_lock() function duplicates an old socket, it also copies icsk->icsk_ulp_data to the new socket. As a result, multiple sockets may hold the same tls_context object.
If one of these sockets releases the sock object, the tls_context will also be freed. Consequently, a UAF occurs when other sockets attempt to access the freed tls_context object.
2.8. Patch
The fix is straighforward:
- Prevent a ULP socket whose ops lacks a clone handler from switching to the listening state.
- Prevent a socket in listening state from setting a ULP whose ops lacks a clone handler.