A 1-day a Day in the Lunar New Year
農曆過年的連假期間,為了不讓腦袋停止運作,我提出了一個挑戰:每天都分析一個 Linux kernel 的漏洞 commit,六日會額外多分析一個。這些分析都不用很深入,只需要了解漏洞成因,以及猜測哪些情境下會觸發該漏洞即可。
Day1 (1/27) net: avoid race between device unregistration and ethnl ops
從 diff 可以得知該 patch 改變了找不到 network device (-ENODEV) 的檢查邏輯:
@@ -90,7 +90,7 @@ int ethnl_ops_begin(struct net_device *dev)
pm_runtime_get_sync(dev->dev.parent);
if (!netif_device_present(dev) ||
- dev->reg_state == NETREG_UNREGISTERING) {
+ dev->reg_state >= NETREG_UNREGISTERING) {
ret = -ENODEV;
goto err;
}
struct net_device 的成員 reg_state 代表 device 目前的狀態,而大於 NETREG_UNREGISTERING 共有三個。
struct net_device {
// [...]
enum { NETREG_UNINITIALIZED=0,
NETREG_REGISTERED, /* completed register_netdevice */
NETREG_UNREGISTERING, /* called unregister_netdevice */
// ==========================
NETREG_UNREGISTERED, /* completed unregister todo */
NETREG_RELEASED, /* called free_netdev */
NETREG_DUMMY, /* dummy device for NAPI poll */
} reg_state:8;
// [...]
}
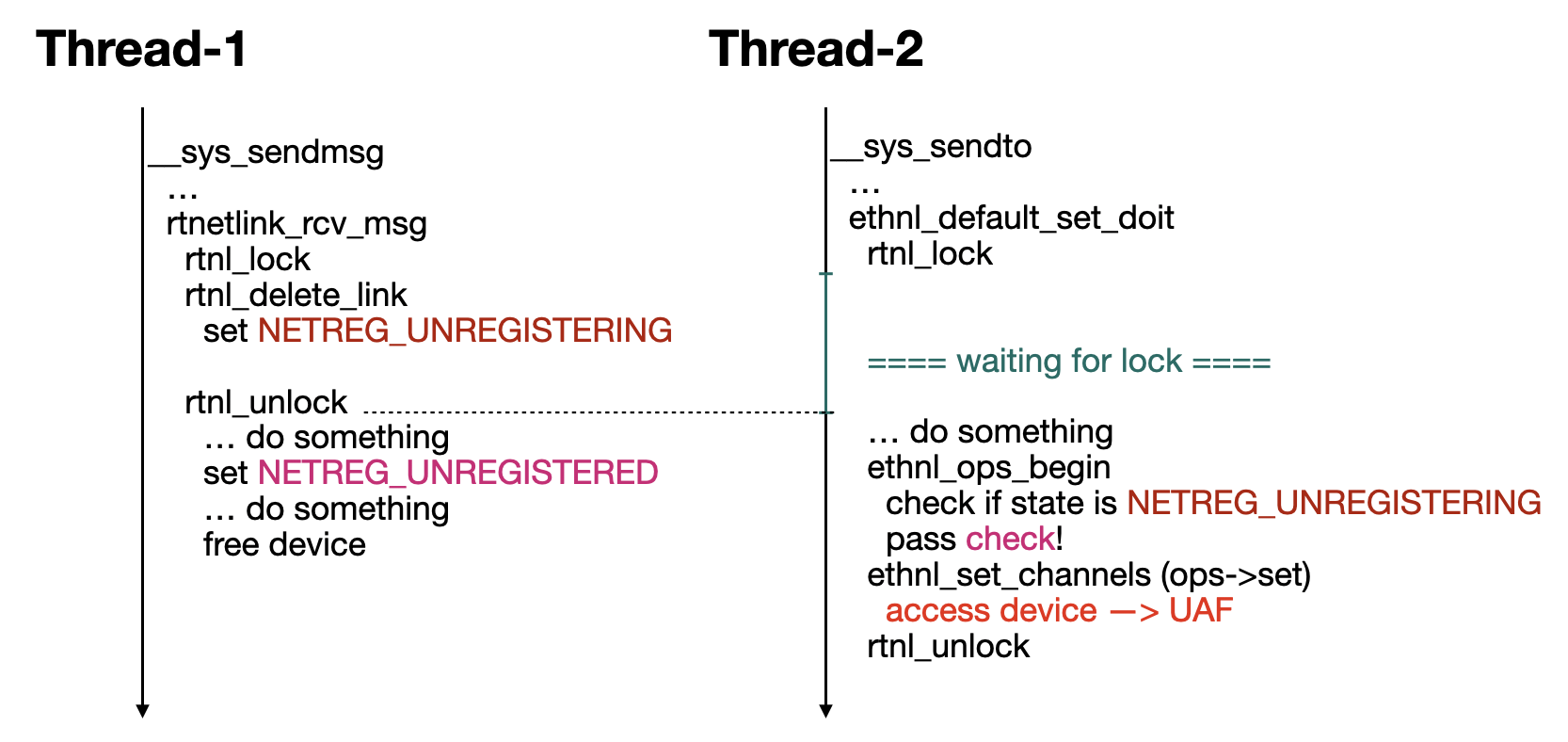
觸發 panic 的執行路徑為:
__sys_sendto()
=> ...
==> netlink_unicast()
===> genl_rcv()
====> netlink_rcv_skb()
=====> genl_rcv_msg()
======> genl_family_rcv_msg_doit()
=======> ethnl_default_set_doit() (ops->doit)
ethnl_default_set_doit() 會呼叫 ethnl_ops_begin() 檢查 device 狀態 [1],如果通過檢查則會繼續執行 set operation,也就是 ethnl_set_channels() [2]。
const struct ethnl_request_ops ethnl_channels_request_ops = {
// [...]
.set = ethnl_set_channels, // <---------------
// [...]
};
static int ethnl_default_set_doit(struct sk_buff *skb, struct genl_info *info)
{
rtnl_lock();
ret = ethnl_ops_begin(req_info.dev); // [1]
if (ret < 0)
goto out_rtnl;
// [...]
ret = ops->set(&req_info, info); // [2], ðnl_set_channels
// [...]
out_rtnl:
rtnl_unlock();
// [...]
}
而 commit 敘述中提到的另一個 function unregister_netdevice_many_notify(),會在 hold RTNL (Routing Netlink) lock 的情況下被呼叫,把要取消註冊的 device 先 mark 成 NETREG_UNREGISTERING [3]。
void unregister_netdevice_many_notify(struct list_head *head,
u32 portid, const struct nlmsghdr *nlh)
{
ASSERT_RTNL();
// [...]
list_for_each_entry(dev, head, unreg_list) {
write_lock(&dev_base_lock);
unlist_netdevice(dev, false);
dev->reg_state = NETREG_UNREGISTERING; // [3]
write_unlock(&dev_base_lock);
}
// [...]
}
在 unlock RTNL lock 時,底層會呼叫 netdev_run_todo() 將裝置的狀態改成 NETREG_UNREGISTERED [4],之後在將 device 與其成員給釋放掉 [5]。
void rtnl_unlock(void)
{
// [...]
netdev_run_todo();
}
void netdev_run_todo(void)
{
struct net_device *dev, *tmp;
// [...]
__rtnl_unlock();
// [...]
list_for_each_entry_safe(dev, tmp, &list, todo_list) {
// [...]
write_lock(&dev_base_lock);
dev->reg_state = NETREG_UNREGISTERED; // [4]
write_unlock(&dev_base_lock);
// [...]
}
while (!list_empty(&list)) {
// [...]
dev = netdev_wait_allrefs_any(&list);
list_del(&dev->todo_list);
// [...]
if (dev->priv_destructor)
dev->priv_destructor(dev); // [5]
if (dev->needs_free_netdev)
free_netdev(dev); // [5]
// [...]
}
}
在刪除 device 時,rtnetlink_rcv_msg() 會先 hold RTNL lock [6],而後呼叫 rtnl_delete_link() 來釋放不同的 device,最後呼叫 unregister_netdevice_many_notify() 取消註冊 device [7]。
static int rtnetlink_rcv_msg(struct sk_buff *skb, struct nlmsghdr *nlh,
struct netlink_ext_ack *extack)
{
// [...]
rtnl_lock(); // [6]
link = rtnl_get_link(family, type);
if (link && link->doit) // &rtnl_dellink --> rtnl_delete_link()
err = link->doit(skb, nlh, extack);
rtnl_unlock();
// [...]
}
int rtnl_delete_link(struct net_device *dev, u32 portid, const struct nlmsghdr *nlh)
{
const struct rtnl_link_ops *ops;
LIST_HEAD(list_kill);
ops = dev->rtnl_link_ops;
ops->dellink(dev, &list_kill);
unregister_netdevice_many_notify(&list_kill, portid, nlh); // [7]
return 0;
}
更詳細一點的 backtrace 如下:
__sys_sendmsg()
=> ...
==> netlink_unicast()
===> netlink_unicast_kernel()
====> netlink_rcv_skb()
=====> rtnetlink_rcv_msg()
======> rtnl_dellink()
=======> rtnl_delete_link()
可以想像到,觸發漏洞的執行流程應該會如下圖所示:
Day2 (1/28) ksmbd: fix Out-of-Bounds Write in ksmbd_vfs_stream_write
Patch 新增了 smb2_write() 內的變數 offset 不能小於 0 的檢查:
@@ -6882,6 +6882,8 @@ int smb2_write(struct ksmbd_work *work)
}
offset = le64_to_cpu(req->Offset);
+ if (offset < 0)
+ return -EINVAL;
Function smb2_write() 是 ksmbd (Kernel SMB Daemon,也就是 In-kernel SMB Server) 用來處理寫入請求 (SMB2_WRITE_HE) 的 handler。該 function 會使用請求的 Offset [1] 與 Length [2] 欄位作為存取檔案的偏移與資料量,傳入 ksmbd_vfs_write() [3] 來完成寫入操作。
typedef long long __kernel_loff_t;
typedef __kernel_loff_t loff_t;
int smb2_write(struct ksmbd_work *work)
{
loff_t offset;
size_t length;
// [...]
offset = le64_to_cpu(req->Offset); // [1]
length = le32_to_cpu(req->Length); // [2]
if (is_rdma_channel == false) {
// [...]
data_buf = (char *)(((char *)&req->hdr.ProtocolId) +
le16_to_cpu(req->DataOffset));
// [...]
err = ksmbd_vfs_write(work, fp, data_buf, length, &offset, // [3]
writethrough, &nbytes);
}
// [...]
}
當目標檔案是 stream 類型時 [4],ksmbd_vfs_write() 會再呼叫 ksmbd_vfs_stream_write() [5],而傳入的參數 pos 為我們可控成負數值的 offset。
static inline bool ksmbd_stream_fd(struct ksmbd_file *fp)
{
return fp->stream.name != NULL;
}
int ksmbd_vfs_write(struct ksmbd_work *work, struct ksmbd_file *fp,
char *buf, size_t count, loff_t *pos, bool sync,
ssize_t *written)
{
// [...]
loff_t offset = *pos;
int err = 0;
// [...]
if (ksmbd_stream_fd(fp)) { // [4]
err = ksmbd_vfs_stream_write(fp, buf, pos, count); // [5]
// [...]
}
}
如果 stream file 沒初始化,ksmbd_vfs_stream_write() 會先分配一塊記憶體給他 [6],之後再把要寫入的資料複製到該記憶體內 [7]。然而,當傳入的 offset (*pos) 為負數時,複製資料時就會觸發 out-of-bound write。
static int ksmbd_vfs_stream_write(struct ksmbd_file *fp, char *buf, loff_t *pos,
size_t count)
{
char *stream_buf = NULL, *wbuf;
// [...]
wbuf = kvzalloc(size, GFP_KERNEL); // [6]
// [...]
stream_buf = wbuf;
memcpy(&stream_buf[*pos], buf, count); // [7]
// [...]
}
對 ksmbd 熟悉的朋友可能會知道,執行 command handler 前會先呼叫 smb2_get_data_area_len()。該 function 會根據不同的 command,檢查傳入的欄位是否合法,但他並沒有檢查有問題的欄位 Offset。
static int smb2_get_data_area_len(unsigned int *off, unsigned int *len,
struct smb2_hdr *hdr)
{
switch (hdr->Command) {
// [...]
case SMB2_WRITE:
if (((struct smb2_write_req *)hdr)->DataOffset ||
((struct smb2_write_req *)hdr)->Length) {
// [8]
*off = max_t(unsigned short int,
le16_to_cpu(((struct smb2_write_req *)hdr)->DataOffset),
offsetof(struct smb2_write_req, Buffer));
*len = le32_to_cpu(((struct smb2_write_req *)hdr)->Length);
break;
}
*off = le16_to_cpu(((struct smb2_write_req *)hdr)->WriteChannelInfoOffset);
*len = le16_to_cpu(((struct smb2_write_req *)hdr)->WriteChannelInfoLength);
break;
// [...]
}
if (*off > 4096) {
// [...]
ret = -EINVAL;
} else if ((u64)*off + *len > MAX_STREAM_PROT_LEN) {
// [...]
ret = -EINVAL;
}
return ret;
}
Day3 (1/29) vsock/virtio: cancel close work in the destructor
AF_VSOCK 是一種 socket family,用於處理 hypervisor 與 guest 之間的溝通。Function vsock_assign_transport() 會在一個 vsock 進行連線時被呼叫。當該 function 檢查 socket 已經初始化過 transport 時,會依序執行 release handler [1] 與 destructor [2]。
int vsock_assign_transport(struct vsock_sock *vsk, struct vsock_sock *psk)
{
// [...]
if (vsk->transport) {
// [...]
vsk->transport->release(vsk); // [1]
vsock_deassign_transport(vsk);
}
}
static void vsock_deassign_transport(struct vsock_sock *vsk)
{
// [...]
vsk->transport->destruct(vsk); // [2]
// [...]
vsk->transport = NULL;
}
以 Loopback 類型的 transport 為例,release handler 與 destructor 分別為 virtio_transport_release() 以及 virtio_transport_destruct()。
static struct virtio_transport loopback_transport = {
.transport = {
// [...]
.destruct = virtio_transport_destruct,
.release = virtio_transport_release,
// [...]
}
// [...]
};
Release handler (virtio_transport_destruct()) 會呼叫 virtio_transport_close() [3] 來關閉 transport。該 function 會在一些條件下,延遲 close socket 的執行。實際上是 dispatch 給 worker 來執行 [4]。
void virtio_transport_release(struct vsock_sock *vsk)
{
struct sock *sk = &vsk->sk;
bool remove_sock = true;
if (sk->sk_type == SOCK_STREAM || sk->sk_type == SOCK_SEQPACKET)
remove_sock = virtio_transport_close(vsk); // [3]
if (remove_sock) {
// [...]
}
}
static bool virtio_transport_close(struct vsock_sock *vsk)
{
struct sock *sk = &vsk->sk;
// [...]
sock_hold(sk); // refcount++
INIT_DELAYED_WORK(&vsk->close_work,
virtio_transport_close_timeout); // [4]
vsk->close_work_scheduled = true;
schedule_delayed_work(&vsk->close_work, VSOCK_CLOSE_TIMEOUT);
return false;
}
Destructor (virtio_transport_release()) 則會釋放 bind 在該 vsock transport 的 virtio_vsock_sock object [5]。
void virtio_transport_destruct(struct vsock_sock *vsk)
{
struct virtio_vsock_sock *vvs = vsk->trans;
kfree(vvs); // [5]
vsk->trans = NULL;
}
如果 close callback function virtio_transport_close_timeout() 發現 socket 的 SOCK_DONE flag 沒有設起來 [6],就會先呼叫 virtio_transport_reset() 發送 VIRTIO_VSOCK_OP_RST packet 給 Loopback vsock worker,接著呼叫 virtio_transport_do_close() 來關閉 vsock [7]。
static void virtio_transport_close_timeout(struct work_struct *work)
{
struct vsock_sock *vsk =
container_of(work, struct vsock_sock, close_work.work);
struct sock *sk = sk_vsock(vsk);
sock_hold(sk); // refcount++
lock_sock(sk);
if (!sock_flag(sk, SOCK_DONE)) { // [6]
virtio_transport_reset(vsk, NULL);
virtio_transport_do_close(vsk, false); // [7]
}
vsk->close_work_scheduled = false;
release_sock(sk);
sock_put(sk); // refcount--
}
virtio_transport_do_close() 會 mark socket 成 SOCK_DONE,之後呼叫 vsock_stream_has_data() 檢查 socket 內是否還有資料仍未處理,有的話會把 TCP 的狀態更新成關閉中 [8]。參考先前介紹的執行流程,該 function 會接著呼叫 virtio_transport_remove_sock() [9] 從 global object 移除與此 vsock 有關的 bound 與 connected vsock 資訊。
static void virtio_transport_do_close(struct vsock_sock *vsk,
bool cancel_timeout /* false */)
{
struct sock *sk = sk_vsock(vsk);
sock_set_flag(sk, SOCK_DONE);
vsk->peer_shutdown = SHUTDOWN_MASK;
if (vsock_stream_has_data(vsk) <= 0)
sk->sk_state = TCP_CLOSING; // [8]
sk->sk_state_change(sk);
if (vsk->close_work_scheduled && // true
(!cancel_timeout || cancel_delayed_work(&vsk->close_work))) {
vsk->close_work_scheduled = false;
virtio_transport_remove_sock(vsk); // [9]
sock_put(sk); // refcount--
}
}
不論是 vsock_stream_has_data() [10] 還是 virtio_transport_remove_sock() [11],都會存取到 bind 在 transport 的 virtio_vsock_sock object,但有可能該 object 已經提前在 destructor (virtio_transport_destruct()) 被釋放掉,這樣就會有 Use-After-Free 的錯誤。
s64 vsock_stream_has_data(struct vsock_sock *vsk)
{
return vsk->transport->stream_has_data(vsk); // <---------------, &virtio_transport_stream_has_data
}
s64 virtio_transport_stream_has_data(struct vsock_sock *vsk)
{
struct virtio_vsock_sock *vvs = vsk->trans;
s64 bytes;
spin_lock_bh(&vvs->rx_lock); // [10]
bytes = vvs->rx_bytes; // [10]
spin_unlock_bh(&vvs->rx_lock); // [10]
return bytes;
}
static void virtio_transport_remove_sock(struct vsock_sock *vsk)
{
struct virtio_vsock_sock *vvs = vsk->trans;
// [...]
__skb_queue_purge(&vvs->rx_queue); // [11]
// [...]
}
Patch 確保了再釋放 virtio_vsock_sock object 之前 callback function 已經執行完。
@@ -1109,6 +1112,8 @@ void virtio_transport_destruct(struct vsock_sock *vsk)
{
struct virtio_vsock_sock *vvs = vsk->trans;
+ virtio_transport_cancel_close_work(vsk, true);
+
kfree(vvs);
vsk->trans = NULL;
}
Function virtio_transport_cancel_close_work() 會呼叫 cancel_delayed_work()。如果 work 正在執行,那就等到他執行結束;如果 work 為 pending 狀態,就直接取消。這樣就可以確保會使用到 virtio_vsock_sock object 的 callback function 會在 destructor 釋放此 object 之前就執行完。
static void virtio_transport_cancel_close_work(struct vsock_sock *vsk,
bool cancel_timeout)
{
struct sock *sk = sk_vsock(vsk);
if (vsk->close_work_scheduled &&
(!cancel_timeout || cancel_delayed_work(&vsk->close_work))) {
vsk->close_work_scheduled = false;
virtio_transport_remove_sock(vsk);
sock_put(sk);
}
}
Day4 (1/30) xsk: fix OOB map writes when deleting elements
AF_XDP 是一種 socket family,是 XDP (express data path) interface,用 eBPF 在網路封包進到 stack 前就先過濾一次的機制。此種類型的 socket 需要在當前 namespace 有 CAP_NET_RAW 權限才能建立 [1]。
static const struct net_proto_family xsk_family_ops = {
.family = PF_XDP,
.create = xsk_create, // <---------------
.owner = THIS_MODULE,
};
static int xsk_create(struct net *net, struct socket *sock, int protocol,
int kern)
{
// [...]
if (!ns_capable(net->user_ns, CAP_NET_RAW)) // [1]
return -EPERM;
if (sock->type != SOCK_RAW)
return -ESOCKTNOSUPPORT;
if (protocol)
return -EPROTONOSUPPORT;
// [...]
}
該漏洞的 patch 將 function xsk_map_delete_elem() 內的 k 變數從 signed 改成 unsigned。
@@ -224,7 +224,7 @@ static long xsk_map_delete_elem(struct bpf_map *map, void *key)
struct xsk_map *m = container_of(map, struct xsk_map, map);
struct xdp_sock __rcu **map_entry;
struct xdp_sock *old_xs;
- int k = *(u32 *)key;
+ u32 k = *(u32 *)key;
該 function 用來在 eBPF program 中刪除 XSK map 的 element。XSK 指的就是 XDP socket,而 XSK map 為 eBPF program 中用來存放 XDP socket 的記憶體空間。
const struct bpf_map_ops xsk_map_ops = {
// [...]
.map_update_elem = xsk_map_update_elem,
.map_delete_elem = xsk_map_delete_elem,
// [...]
};
不過如果要在 eBPF program 中使用這種類型的 map,需要在 init namespace 中有 root 的權限 [2],因此一般使用者存取不到。
#if defined(CONFIG_XDP_SOCKETS)
BPF_MAP_TYPE(BPF_MAP_TYPE_XSKMAP, xsk_map_ops)
#endif
static int map_create(union bpf_attr *attr)
{
// [...]
switch (map_type) {
// [...]
case BPF_MAP_TYPE_XSKMAP:
if (!capable(CAP_NET_ADMIN)) // [2]
return -EPERM;
break;
// [...]
}
}
因為 key 是使用者可控,加上 xsk_map_delete_elem() 並沒有對 key value 的 lower bound 做檢查 [3],因此在存取 map entry 時就會觸發 Out-Of-Bounds access [4, 5]。
static long xsk_map_delete_elem(struct bpf_map *map, void *key)
{
struct xsk_map *m = container_of(map, struct xsk_map, map);
struct xdp_sock __rcu **map_entry;
struct xdp_sock *old_xs;
int k = *(u32 *)key;
if (k >= map->max_entries) // [3]
return -EINVAL;
spin_lock_bh(&m->lock);
map_entry = &m->xsk_map[k]; // [4]
old_xs = unrcu_pointer(xchg(map_entry, NULL));
if (old_xs)
xsk_map_sock_delete(old_xs, map_entry); // [5]
spin_unlock_bh(&m->lock);
return 0;
}
Day5 (1/31) af_packet: fix vlan_get_tci() vs MSG_PEEK
Patch 調整了 function vlan_get_tci() 的執行邏輯,我們需要先知道怎麼走到這個 function。
AF_PACKET 為 Linux kernel Low-level packet interface 的實作。當建立一個 AF_PACKET socket 時,會由 AF_PACKET 的 create handler packet_create() 來處理。
static const struct net_proto_family packet_family_ops = {
.family = PF_PACKET,
.create = packet_create,
// [...]
};
packet_create() 檢查是否 process 在當前 namespace 有足夠的權限 [1],並且只支援部分的 socket type [2]。新增的 socket 其 type ops 為 packet_ops。
static int packet_create(struct net *net, struct socket *sock, int protocol,
int kern)
{
// [...]
if (!ns_capable(net->user_ns, CAP_NET_RAW)) // [1]
return -EPERM;
if (sock->type != SOCK_DGRAM && sock->type != SOCK_RAW && // [2]
sock->type != SOCK_PACKET)
return -ESOCKTNOSUPPORT;
// [...]
sock->ops = &packet_ops;
// [...]
}
當 AF_PACKET socket 呼叫 sys_recvmsg() 時,底層會由 recvmsg handler packet_recvmsg() 來處理 [3]。在解析封包時,如果 packet socket 的 PACKET_SOCK_AUXDATA flag 有被設上 [4],就會用 control block (CB) 內的 interface index 來取的對應的 device object [5],並以此為參數呼叫 vlan_get_tci() [6]。
static const struct proto_ops packet_ops = {
.family = PF_PACKET,
// [...]
.sendmsg = packet_sendmsg,
.recvmsg = packet_recvmsg, // [3]
// [...]
};
#define PACKET_SKB_CB(__skb) ((struct packet_skb_cb *)((__skb)->cb))
static int packet_recvmsg(struct socket *sock, struct msghdr *msg, size_t len,
int flags)
{
struct sock *sk = sock->sk;
// [...]
skb = skb_recv_datagram(sk, flags, &err);
// [...]
if (packet_sock_flag(pkt_sk(sk), PACKET_SOCK_AUXDATA)) { // [4]
struct sockaddr_ll *sll = &PACKET_SKB_CB(skb)->sa.ll;
// [...]
else if (unlikely(sock->type == SOCK_DGRAM && eth_type_vlan(skb->protocol))) {
dev = dev_get_by_index_rcu(sock_net(sk), sll->sll_ifindex); // [5]
if (dev) {
aux.tp_vlan_tci = vlan_get_tci(skb, dev); // [6]
// [...]
}
}
}
}
vlan_get_tci() 用來從 packet 中取得 VLAN 標記 (TCI, Tag Control Information)。該 function 會先呼叫 skb_push() 來調整 packet object 的 metadata [7],再取得封包內容並回傳 [8]。
static u16 vlan_get_tci(struct sk_buff *skb, struct net_device *dev)
{
u8 *skb_orig_data = skb->data;
int skb_orig_len = skb->len;
struct vlan_hdr vhdr, *vh;
unsigned int header_len;
// [...]
skb_push(skb, skb->data - skb_mac_header(skb)); // [7]
vh = skb_header_pointer(skb, header_len, sizeof(vhdr), &vhdr);
// [...]
return ntohs(vh->h_vlan_TCI); // [8]
}
void *skb_push(struct sk_buff *skb, unsigned int len)
{
skb->data -= len;
skb->len += len;
if (unlikely(skb->data < skb->head))
skb_under_panic(skb, len, __builtin_return_address(0));
return skb->data;
}
然而,用於取得 packet object 的 function skb_recv_datagram() 會在底層呼叫 __skb_try_recv_from_queue(),並在 syscall 的參數 flags 有包含 MSG_PEEK 時更新 refcount 就回傳 packet object [9],而不是從 packet queue 中移除 [10]。
struct sk_buff *__skb_try_recv_from_queue(/* ... */)
{
bool peek_at_off = false;
struct sk_buff *skb;
int _off = 0;
// [...]
*last = queue->prev;
skb_queue_walk(queue, skb) {
if (flags & MSG_PEEK) {
// [...]
refcount_inc(&skb->users); // [9]
} else {
__skb_unlink(skb, queue); // [10]
}
// [...]
return skb;
}
// [...]
}
也就是說,我們可以透過 MSG_PEEK 不斷觸發 skb_push(),這樣就能夠一直更新 skb metadata。直到 data pointer 比 header 還要前面時,function skb_under_panic() 就會被執行並觸發 kernel panic。
而 patch 則是將 vlan_get_tci() 的參數 skb 改成 const pointer,確保該 object 的成員不會在 function 內被更新。
Day6 (2/01)
KEYS: prevent NULL pointer dereference in find_asymmetric_key()
在 function find_asymmetric_key() 的開頭有用 WARN_ON() 檢查傳入的參數 id_{0,1,2} 是否都是 NULL pointer [1],但是後續 if-else 的最後還是會直接存取 id_2 [2],這樣就會有 null-ptr-deref 的問題。
struct key *find_asymmetric_key(struct key *keyring,
const struct asymmetric_key_id *id_0,
const struct asymmetric_key_id *id_1,
const struct asymmetric_key_id *id_2,
bool partial)
{
struct key *key;
key_ref_t ref;
const char *lookup;
char *req, *p;
int len;
WARN_ON(!id_0 && !id_1 && !id_2); // [1]
if (id_0) {
lookup = id_0->data;
len = id_0->len;
} else if (id_1) {
lookup = id_1->data;
len = id_1->len;
} else {
lookup = id_2->data; // [2]
len = id_2->len;
}
// [...]
}
Patch 也很簡單,就新增一個 id_2 的 else-if block,然後把原本的 WARN_ON() 移動到最後的 else。
@@ -60,17 +60,18 @@ struct key *find_asymmetric_key(struct key *keyring,
// [...]
- WARN_ON(!id_0 && !id_1 && !id_2);
-
// [...]
- } else {
+ } else if (id_2) {
lookup = id_2->data;
len = id_2->len;
+ } else {
+ WARN_ON(1);
+ return ERR_PTR(-EINVAL);
}
漏洞本身很直觀,不過 find_asymmetric_key() 會在什麼情況下被呼叫?
System call add_key 能在 Linux kernel key management 註冊一把 key。呼叫時需要傳入 type 來指定 key 的類型 [3],而底層 function 會遍歷 linked list key_types_list 來找對應類型名稱的 key_type object [4]。
SYSCALL_DEFINE5(add_key, const char __user *, _type, /* ... */)
{
char type[32];
// [...]
ret = key_get_type_from_user(type, _type, sizeof(type)); // [3]
// [...]
key_ref = key_create_or_update(keyring_ref, type, description, // <---------------
payload, plen, KEY_PERM_UNDEF,
KEY_ALLOC_IN_QUOTA);
// [...]
}
key_ref_t key_create_or_update(key_ref_t keyring_ref,
const char *type,
/* ... */)
{
return __key_create_or_update(keyring_ref, type, description, payload, // <---------------
plen, perm, flags, true);
}
static key_ref_t __key_create_or_update(key_ref_t keyring_ref,
const char *type,
/* ... */)
{
struct keyring_index_key index_key = {
// [...]
};
index_key.type = key_type_lookup(type); // <---------------
// [...]
}
struct key_type *key_type_lookup(const char *type)
{
struct key_type *ktype;
// [...]
list_for_each_entry(ktype, &key_types_list, link) { // [4]
if (strcmp(ktype->name, type) == 0)
goto found_kernel_type;
}
// [...]
found_kernel_type:
return ktype;
}
Subsystem 會在 kernel booting 時呼叫 register_key_type() 註冊 key_type object 到 linked list。key_type object 定義了 parsing、lookup asymmetric key 等相關操作時所呼叫的 handler。
Key management 的初始化 function key_init() 會註冊下面幾種 key type:
- “keyring” (
key_type_keyring) - “.dead” (
key_type_dead) - “user” (
key_type_user) - “logon” (
key_type_logon)
而 kernelCTF 的執行環境還會註冊下面幾種:
- “blacklist” (
key_type_blacklist) - “id_resolver” (
key_type_id_resolver) - “id_legacy” (
key_type_id_resolver_legacy) - “cifs.spnego” (
cifs_spnego_key_type) - “cifs.idmap” (
cifs_idmap_key_type) - “asymmetric” (
key_type_asymmetric) - “dns_resolver” (
key_type_dns_resolver)
“asymmetric” 類型的 key 會在搜尋 restriction 時呼叫 asymmetric_lookup_restriction()。
struct key_type key_type_asymmetric = {
.name = "asymmetric",
// [...]
.lookup_restriction = asymmetric_lookup_restriction, // <---------------
// [...]
};
asymmetric_lookup_restriction() 會用 restrict_link_by_key_or_keyring() 作為 check handler [5]。
static struct key_restriction *asymmetric_lookup_restriction(
const char *restriction)
{
//[...]
if ((strcmp(restrict_method, "key_or_keyring") == 0) && next) {
// [...]
key_restrict_link_func_t link_fn =
restrict_link_by_key_or_keyring;
// [...]
ret = asymmetric_restriction_alloc(link_fn, key); // <---------------
}
// [...]
}
static struct key_restriction *asymmetric_restriction_alloc(
key_restrict_link_func_t check,
struct key *key)
{
struct key_restriction *keyres =
kzalloc(sizeof(struct key_restriction), GFP_KERNEL);
// [...]
keyres->check = check; // [5]
keyres->key = key;
keyres->keytype = &key_type_asymmetric;
return keyres;
}
當呼叫 check handler 時,key_or_keyring_common() 就會呼叫 find_asymmetric_key() [6] 來找 key。不過 key_or_keyring_common() 在一開始已經有檢查 sig->auth_ids[] 是否存在 [7],所以該漏洞有可能只是單純被 static tool 分析,或者是從另一條預設沒啟用的執行路徑觸發 (crypto/asymmetric_keys/pkcs7_trust.c)。
int restrict_link_by_key_or_keyring(struct key *dest_keyring,
const struct key_type *type,
const union key_payload *payload,
struct key *trusted)
{
return key_or_keyring_common(dest_keyring, type, payload, trusted, // <---------------
false);
}
static int key_or_keyring_common(struct key *dest_keyring,
const struct key_type *type,
const union key_payload *payload,
struct key *trusted, bool check_dest)
{
// [...]
sig = payload->data[asym_auth];
if (!sig->auth_ids[0] && !sig->auth_ids[1] && !sig->auth_ids[2]) // [7]
return -ENOKEY;
if (trusted) {
if (trusted->type == &key_type_keyring) {
// [...]
key = find_asymmetric_key(trusted, sig->auth_ids[0], // [6]
sig->auth_ids[1],
sig->auth_ids[2], false);
}
// [...]
}
}
epoll: be better about file lifetimes
從 diff 可以知道,ep_item_poll() 在執行 polling 會先嘗試呼叫 epi_fget() 取得 file object 並增加 refcount。如果 file refcount 已經變為 0,則不更新並直接回傳。
+static struct file *epi_fget(const struct epitem *epi)
+{
+ struct file *file;
+
+ file = epi->ffd.file;
+ if (!atomic_long_inc_not_zero(&file->f_count))
+ file = NULL;
+ return file;
+}
static __poll_t ep_item_poll(const struct epitem *epi, poll_table *pt,
int depth)
{
- struct file *file = epi->ffd.file;
+ struct file *file = epi_fget(epi);
__poll_t res;
// [...]
+ if (!file)
+ return 0;
// [...]
+ fput(file);
return res & epi->event.events;
}
透過 sys_epoll_ctl(EPOLL_CTL_ADD) 可以在 epoll_event 新增一個 item,而 event item 會有一個 reference 指向 file [1]。
SYSCALL_DEFINE4(epoll_ctl, int, epfd, int, op, int, fd,
struct epoll_event __user *, event)
{
struct epoll_event epds;
// [...]
return do_epoll_ctl(epfd, op, fd, &epds, false); // <---------------
}
int do_epoll_ctl(int epfd, int op, int fd, struct epoll_event *epds,
bool nonblock)
{
// [...]
f = fdget(epfd);
tf = fdget(fd);
ep = f.file->private_data;
// [...]
switch (op) {
case EPOLL_CTL_ADD:
if (!epi) {
epds->events |= EPOLLERR | EPOLLHUP;
error = ep_insert(ep, epds, tf.file, fd, full_check); // <---------------
}
// [...]
}
}
static int ep_insert(struct eventpoll *ep, const struct epoll_event *event,
struct file *tfile, int fd, int full_check)
{
// [...]
epi = kmem_cache_zalloc(epi_cache, GFP_KERNEL); // event item
epi->ep = ep;
ep_set_ffd(&epi->ffd, tfile, fd);
epi->event = *event;
// [...]
attach_epitem(tfile, epi);
// [...]
ep_rbtree_insert(ep, epi);
// [...]
epq.epi = epi;
init_poll_funcptr(&epq.pt, ep_ptable_queue_proc);
revents = ep_item_poll(epi, &epq.pt, 1);
// [...]
}
static inline void ep_set_ffd(struct epoll_filefd *ffd,
struct file *file, int fd)
{
ffd->file = file; // [1]
ffd->fd = fd;
}
其中 attach_epitem() 會建立一個 epitems_head object [2] 給目標檔案,而 event item epi->fllink 會把所有 polled 的 file 串在一起 [3]。
static int attach_epitem(struct file *file, struct epitem *epi)
{
struct epitems_head *to_free = NULL;
struct hlist_head *head = NULL;
struct eventpoll *ep = NULL;
// [...]
else if (!READ_ONCE(file->f_ep)) {
to_free = kmem_cache_zalloc(ephead_cache, GFP_KERNEL); // [2]
// [...]
head = &to_free->epitems;
}
spin_lock(&file->f_lock);
if (!file->f_ep) {
// [...]
WRITE_ONCE(file->f_ep, head);
to_free = NULL;
}
hlist_add_head_rcu(&epi->fllink, file->f_ep); // [3]
spin_unlock(&file->f_lock);
free_ephead(to_free);
return 0;
}
當 file refcount 降為 0 並要被釋放時,eventpoll_release() 會根據 file object 是否有 event poll object [4] 來決定要不要執行 eventpoll_release_file(),把 epitem 從 eventpoll RB tree 中移除。
static void __fput(struct file *file)
{
// [...]
eventpoll_release(file); // <---------------
// [...]
}
static inline void eventpoll_release(struct file *file)
{
if (likely(!READ_ONCE(file->f_ep))) // [4]
return;
eventpoll_release_file(file);
}
另一個 system call epoll_wait 可以等待 epoll file 發生 I/O event。如果 ep_events_available() 發現已經有需要處理的 event [5],就會呼叫 ep_send_events() 通知所有 event item [6]。
SYSCALL_DEFINE4(epoll_wait, int, epfd, struct epoll_event __user *, events,
int, maxevents, int, timeout)
{
struct timespec64 to;
return do_epoll_wait(epfd, events, maxevents, // <---------------
/* ... */);
}
static int do_epoll_wait(int epfd, struct epoll_event __user *events,
int maxevents, struct timespec64 *to)
{
// [...]
ep = f.file->private_data;
error = ep_poll(ep, events, maxevents, to); // <---------------
// [...]
}
static int ep_poll(struct eventpoll *ep, struct epoll_event __user *events,
int maxevents, struct timespec64 *timeout)
{
// [...]
eavail = ep_events_available(ep); // [5]
while (1) {
if (eavail) {
// [...]
res = ep_send_events(ep, events, maxevents); // [6]
if (res)
return res;
}
}
// [...]
}
ep_send_events() 會遍歷每個 event item,嘗試執行 ep_item_poll() [7] 來取得 polling event。
static int ep_send_events(struct eventpoll *ep,
struct epoll_event __user *events, int maxevents)
{
struct epitem *epi, *tmp;
// [...]
ep_start_scan(ep, &txlist);
// [...]
list_for_each_entry_safe(epi, tmp, &txlist, rdllink) {
// [...]
revents = ep_item_poll(epi, &pt, 1); // [7]
// [...]
}
}
但因為 ep_item_poll() 在執行 polling 前不會拿 file refcount,如果此時另一個 thread 在執行 polling handler 的過程中釋放 target file,就有可能 race fput() 而造成 Use-After-Free。
不幸的是,所有與 event 相關的操作都會用 eventpoll lock (ep->mtx) 保護,這導致就算 target file object 的 refcount 已經為 0,即將被釋放,還是會因為 lock 而卡在 eventpoll_release_file()。除非 polling handler 有對檔案做其他操作,否則看起來是 unexploitable 的漏洞。
更詳細的漏洞說明以及 POC,可以參考討論串的其中一則訊息。
Day7 (2/02)
nfsd: fix race between laundromat and free_stateid
根據敘述,NFSD (Network File System Daemon) 在下面兩個操作同時執行時會發生 race condition:
- Laundromat thread - 處理 revoked delegations
- NFS thread - 處理 client 的 free_stateid 請求
在初始化 NFSv4 Server 時會建立一個 Laundromat thread,定期管理與回收過期的連線 [1]。Thread 的 entry function 為 laundromat_main()。
static int nfs4_state_create_net(struct net *net)
{
struct nfsd_net *nn = net_generic(net, nfsd_net_id);
// [...]
INIT_DELAYED_WORK(&nn->laundromat_work, laundromat_main); // [1]
// [...]
}
laundromat_main() 會呼叫 nfs4_laundromat(),而 nfs4_laundromat() 會在 hold state lock 的情況下遍歷 delegation recall linked list [2],將過期的 delegation 新增到 reaper list [3]。接著該 function 會釋放 state lock 後,並遍歷 reaper list 呼叫 revoke_delegation() 來 revoke delegation [4]。
static void
laundromat_main(struct work_struct *laundry)
{
time64_t t;
struct delayed_work *dwork = to_delayed_work(laundry);
struct nfsd_net *nn = container_of(dwork, struct nfsd_net,
laundromat_work);
t = nfs4_laundromat(nn);
queue_delayed_work(laundry_wq, &nn->laundromat_work, t*HZ);
}
static time64_t
nfs4_laundromat(struct nfsd_net *nn)
{
// [...]
spin_lock(&state_lock);
list_for_each_safe(pos, next, &nn->del_recall_lru) {
dp = list_entry (pos, struct nfs4_delegation, dl_recall_lru); // [2]
if (!state_expired(<, dp->dl_time))
break;
unhash_delegation_locked(dp, SC_STATUS_REVOKED);
list_add(&dp->dl_recall_lru, &reaplist); // [3]
}
spin_unlock(&state_lock);
while (!list_empty(&reaplist)) {
dp = list_first_entry(&reaplist, struct nfs4_delegation,
dl_recall_lru);
list_del_init(&dp->dl_recall_lru);
revoke_delegation(dp); // [4]
}
// [...]
}
Delegation revocation handler revoke_delegation() 上 client lock 後,更新 refcount 且將 delegation object 移動到 revoke list [5],之後呼叫 destroy_unhashed_deleg()。
static void revoke_delegation(struct nfs4_delegation *dp)
{
struct nfs4_client *clp = dp->dl_stid.sc_client;
// [...]
if (dp->dl_stid.sc_status &
(SC_STATUS_REVOKED | SC_STATUS_ADMIN_REVOKED)) {
spin_lock(&clp->cl_lock);
refcount_inc(&dp->dl_stid.sc_count);
list_add(&dp->dl_recall_lru, &clp->cl_revoked); // [5]
spin_unlock(&clp->cl_lock);
}
destroy_unhashed_deleg(dp);
}
destroy_unhashed_deleg() 會呼叫 nfs4_unlock_deleg_lease() 更新 delegation file 對應到的 lease lock [6],最後呼叫 nfs4_put_stid() 釋放 refcount。
static void destroy_unhashed_deleg(struct nfs4_delegation *dp)
{
// [...]
nfs4_unlock_deleg_lease(dp); // [6]
nfs4_put_stid(&dp->dl_stid);
}
static void nfs4_unlock_deleg_lease(struct nfs4_delegation *dp)
{
struct nfs4_file *fp = dp->dl_stid.sc_file;
struct nfsd_file *nf = fp->fi_deleg_file;
// [...]
kernel_setlease(nf->nf_file, F_UNLCK, NULL, (void **)&dp);
put_deleg_file(fp);
}
NFS client 可以發送 procedure OP_FREE_STATEID 來釋放 stateid (delegation)。NFSD server 會呼叫 nfsd4_free_stateid() 來處理該請求 [7]。
static const struct nfsd4_operation nfsd4_ops[] = {
// [...]
[OP_FREE_STATEID] = {
.op_func = nfsd4_free_stateid, // [7]
// [...]
.op_name = "OP_FREE_STATEID",
// [...]
},
// [...]
};
nfsd4_free_stateid() 發現 stateid 的 type 為 SC_TYPE_DELEG,會在 hold client lock 的情況下將 delegation object 從 reaper list 移除 [8],unlock 後釋放 stateid object [9]。
__be32
nfsd4_free_stateid(struct svc_rqst *rqstp, struct nfsd4_compound_state *cstate,
union nfsd4_op_u *u)
{
struct nfs4_stid *s;
struct nfs4_client *cl = cstate->clp;
// [...]
spin_lock(&cl->cl_lock);
s = find_stateid_locked(cl, stateid);
// [...]
spin_lock(&s->sc_lock);
switch (s->sc_type) {
case SC_TYPE_DELEG:
if (s->sc_status & SC_STATUS_REVOKED) {
s->sc_status |= SC_STATUS_CLOSED;
spin_unlock(&s->sc_lock);
dp = delegstateid(s);
list_del_init(&dp->dl_recall_lru); // [8]
spin_unlock(&cl->cl_lock);
nfs4_put_stid(s); // [9]
ret = nfs_ok;
goto out;
}
ret = nfserr_locks_held;
break;
// [...]
}
out:
return ret;
}
正常情況下 laundromat 的執行流程會像是:

如果與 nfsd4_free_stateid() 有 race condition 的問題,則執行流程會變得像:

此時,file lease 仍 reference 到 delegation object,因此後續 NFSD 遍歷 lease list 時,就會呼叫 nfsd_breaker_owns_lease() 並存取到已經釋放的 delegation object [10]。
static bool nfsd_breaker_owns_lease(struct file_lease *fl)
{
struct nfs4_delegation *dl = fl->c.flc_owner;
struct svc_rqst *rqst;
struct nfs4_client *clp;
rqst = nfsd_current_rqst();
if (!nfsd_v4client(rqst))
return false;
clp = *(rqst->rq_lease_breaker);
return dl->dl_stid.sc_client == clp; // [10]
}
smb: client: fix double free of TCP_Server_Info::hostname
CIFS 為 Linux kernel smb 的 client 端實作。當 mount 一個 smb server 時,function cifs_get_tcp_session() 會被呼叫來建立 TCP session object,紀錄 remote server 的連線狀態。此外,在初始化的過程中,該 function 還會建立一個 kernel thread “cifsd” 來處理此 session 連線 [1]。
int cifs_mount(struct cifs_sb_info *cifs_sb, struct smb3_fs_context *ctx)
{
int rc = 0;
struct cifs_mount_ctx mnt_ctx = { .cifs_sb = cifs_sb, .fs_ctx = ctx, };
rc = cifs_mount_get_session(&mnt_ctx); // <---------------
// [...]
}
int cifs_mount_get_session(struct cifs_mount_ctx *mnt_ctx)
{
// [...]
server = cifs_get_tcp_session(ctx, NULL); // <---------------
// [...]
}
struct TCP_Server_Info *
cifs_get_tcp_session(struct smb3_fs_context *ctx,
struct TCP_Server_Info *primary_server)
{
struct TCP_Server_Info *tcp_ses = NULL;
// [...]
tcp_ses = kzalloc(sizeof(struct TCP_Server_Info), GFP_KERNEL);
tcp_ses->hostname = kstrdup(ctx->server_hostname, GFP_KERNEL);
if (ctx->leaf_fullpath) {
tcp_ses->leaf_fullpath = kstrdup(ctx->leaf_fullpath, GFP_KERNEL);
// [...]
}
// [...]
tcp_ses->tsk = kthread_run(cifs_demultiplex_thread, // [1]
tcp_ses, "cifsd");
// [...]
return tcp_ses;
}
cifs_demultiplex_thread() 會非同步地建立連線,然而當底層 function cifs_handle_standard() 發現 session 已經過期 [2],就會呼叫 cifs_reconnect() 重新連線。
static int
cifs_demultiplex_thread(void *p)
{
struct TCP_Server_Info *server = p;
// [...]
while (server->tcpStatus != CifsExiting) {
// [...]
else {
mids[0] = server->ops->find_mid(server, buf);
bufs[0] = buf;
num_mids = 1;
if (!mids[0] || !mids[0]->receive)
length = standard_receive3(server, mids[0]); // <---------------
// [...]
}
// [...]
}
}
static int
standard_receive3(struct TCP_Server_Info *server, struct mid_q_entry *mid)
{
// [...]
return cifs_handle_standard(server, mid); // <---------------
}
int
cifs_handle_standard(struct TCP_Server_Info *server, struct mid_q_entry *mid)
{
char *buf = server->large_buf ? server->bigbuf : server->smallbuf;
// [...]
if (server->ops->is_session_expired &&
server->ops->is_session_expired(buf)) { // [2]
cifs_reconnect(server, true);
return -1;
}
// [...]
}
在 DFS (Distributed File System) feature 支援的情況下,cifs_reconnect() 底層會呼叫 reconnect_target_unlocked(),遍歷所有可能的 target file system name [3],呼叫 __reconnect_target_unlocked() 向這些 target 建立連線 [4]。
int cifs_reconnect(struct TCP_Server_Info *server, bool mark_smb_session)
{
// [...]
return reconnect_dfs_server(server); // <---------------
}
static int reconnect_dfs_server(struct TCP_Server_Info *server)
{
// [...]
do {
// [...]
cifs_server_lock(server);
rc = reconnect_target_unlocked(server, &tl, &target_hint);
// [...]
} while (server->tcpStatus == CifsNeedReconnect);
}
static int reconnect_target_unlocked(struct TCP_Server_Info *server, struct dfs_cache_tgt_list *tl,
struct dfs_cache_tgt_iterator **target_hint)
{
int rc;
struct dfs_cache_tgt_iterator *tit;
// [...]
tit = dfs_cache_get_tgt_iterator(tl);
// [...]
for (; tit; tit = dfs_cache_get_next_tgt(tl, tit)) { // [3]
rc = __reconnect_target_unlocked(server, dfs_cache_get_tgt_name(tit)); // [4]
// [...]
}
}
__reconnect_target_unlocked() 會釋放當前 server object 的成員 hostname [5] 且替換成新的 target hostname [6]。
static int __reconnect_target_unlocked(struct TCP_Server_Info *server, const char *target)
{
// [...]
if (!cifs_swn_set_server_dstaddr(server)) {
if (server->hostname != target) {
hostname = extract_hostname(target);
if (!IS_ERR(hostname)) {
spin_lock(&server->srv_lock);
kfree(server->hostname); // [5]
server->hostname = hostname; // [6]
spin_unlock(&server->srv_lock);
}
}
// [...]
}
}
在發生錯誤時會執行 cifs_put_tcp_session() 來釋放 hostname [7] 以及停止 cifsd [8]。
void
cifs_put_tcp_session(struct TCP_Server_Info *server, int from_reconnect)
{
// [...]
kfree(server->hostname); // [7]
server->hostname = NULL;
// [...]
task = xchg(&server->tsk, NULL);
if (task)
send_sig(SIGKILL, task, 1); // [8]
}
然而,該 function 會先釋放 server object 的 hostname,之後才發送 SIGKILL signal 給 cifsd thread。若此時 cifsd thread 正執行 __reconnect_target_unlocked() 到一半,則 kfree(server->hostname) 就有可能被釋放兩次,造成 double free。
結語
雖然大部分漏洞的成因都不難,但因為涵蓋了各式各樣的 subsystem,仍讓我在分析觸發漏洞的執行流程中學到不少新東西。希望今年 (2025) 可以繼續精進自己的能力,且持續分享 Linux kernel 相關的 1-day 分析與手法,祝各位新年快樂 🎊。