How Does Linux Direct Mapping Work?
I originally thought that the Direct Mapping in the x64 Linux kernel directly mapped RAM memory. However, while reproducing 1-day, I realized that the actual situation was more complex. This led me to spend some time understanding how it works.
1. Overview
____________________________________________________________|___________________________________________________________
| | | |
ffff800000000000 | -128 TB | ffff87ffffffffff | 8 TB | ... guard hole, also reserved for hypervisor
ffff880000000000 | -120 TB | ffff887fffffffff | 0.5 TB | LDT remap for PTI
ffff888000000000 | -119.5 TB | ffffc87fffffffff | 64 TB | direct mapping of all physical memory (page_offset_base)
ffffc88000000000 | -55.5 TB | ffffc8ffffffffff | 0.5 TB | ... unused hole
ffffc90000000000 | -55 TB | ffffe8ffffffffff | 32 TB | vmalloc/ioremap space (vmalloc_base)
ffffe90000000000 | -23 TB | ffffe9ffffffffff | 1 TB | ... unused hole
ffffea0000000000 | -22 TB | ffffeaffffffffff | 1 TB | virtual memory map (vmemmap_base)
ffffeb0000000000 | -21 TB | ffffebffffffffff | 1 TB | ... unused hole
ffffec0000000000 | -20 TB | fffffbffffffffff | 16 TB | KASAN shadow memory
__________________|____________|__________________|_________|____________________________________________________________
Direct Mapping is based on the physical memory layout, which, in turn, depends on the amount of RAM the system has.
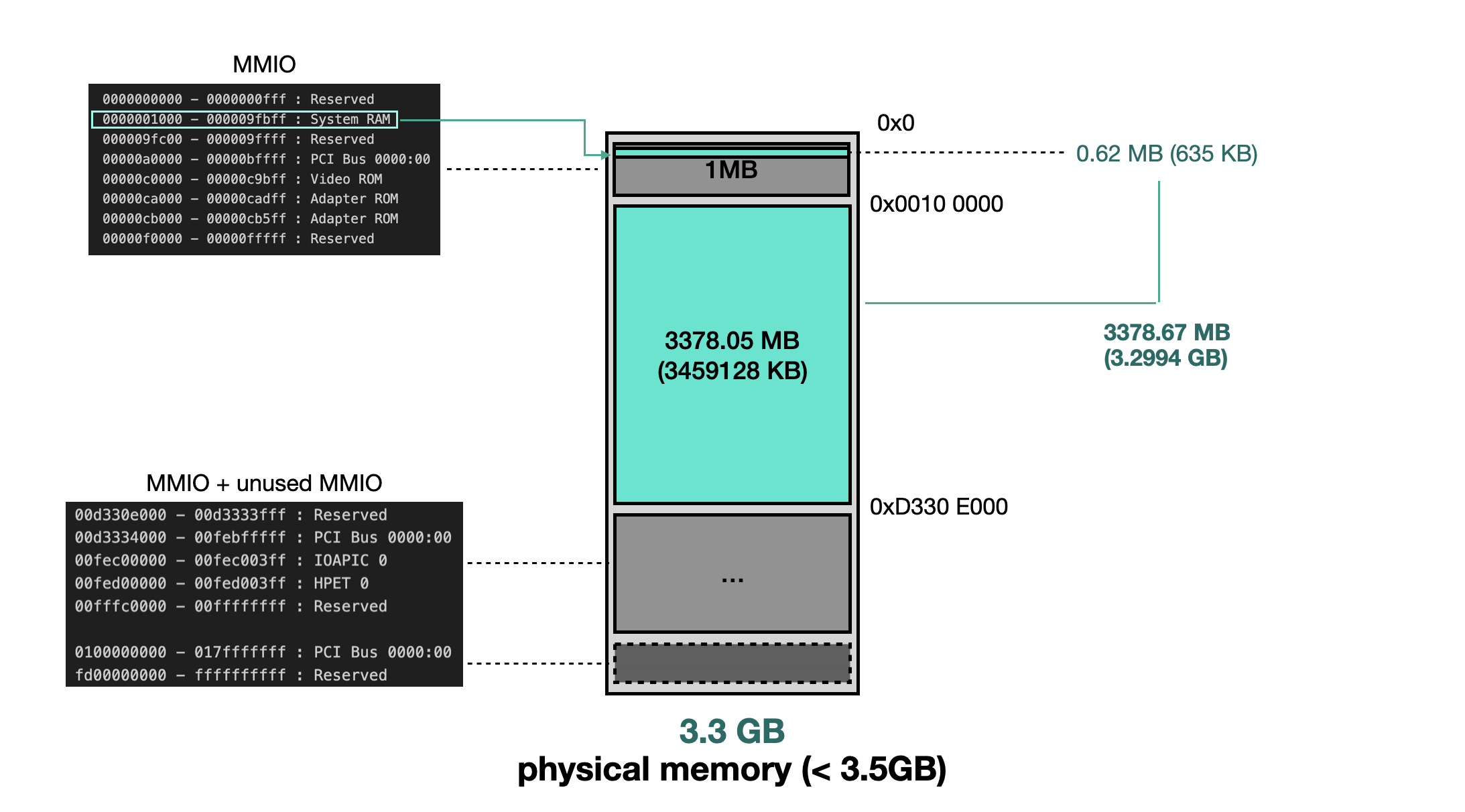
Based on testing, the layout of physical memory differs when RAM is ≥ 3.5 GB versus < 3.5 GB. Below are the /proc/iomem outputs for systems with 3.3 GB and 3.5 GB of RAM.
RAM == 3.3 GB
0000000000-0000000fff : Reserved
0000001000-000009fbff : System RAM
000009fc00-000009ffff : Reserved
00000a0000-00000bffff : PCI Bus 0000:00
00000c0000-00000c9bff : Video ROM
00000ca000-00000cadff : Adapter ROM
00000cb000-00000cb5ff : Adapter ROM
00000f0000-00000fffff : Reserved
----------- (Differences Below) -----------
0000100000-00d330dfff : System RAM (1)
00d330e000-00d3333fff : Reserved
00d3334000-00febfffff : PCI Bus 0000:00
00fec00000-00fec003ff : IOAPIC 0
00fed00000-00fed003ff : HPET 0
00fffc0000-00ffffffff : Reserved
0100000000-017fffffff : PCI Bus 0000:00
fd00000000-ffffffffff : Reserved
RAM == 3.5 GB
0000000000-0000000fff : Reserved
0000001000-000009fbff : System RAM
000009fc00-000009ffff : Reserved
00000a0000-00000bffff : PCI Bus 0000:00
00000c0000-00000c9bff : Video ROM
00000ca000-00000cadff : Adapter ROM
00000cb000-00000cb5ff : Adapter ROM
00000f0000-00000fffff : Reserved
----------- (Differences Below) -----------
0000100000-00bffd9fff : System RAM (1)
00bffda000-00bfffffff : Reserved
00c0000000-00febfffff : PCI Bus 0000:00
00fec00000-00fec003ff : IOAPIC 0
00fed00000-00fed003ff : HPET 0
00fffc0000-00ffffffff : Reserved
0100000000-011fffffff : System RAM (2)
0140000000-01bfffffff : PCI Bus 0000:00
fd00000000-ffffffffff : Reserved
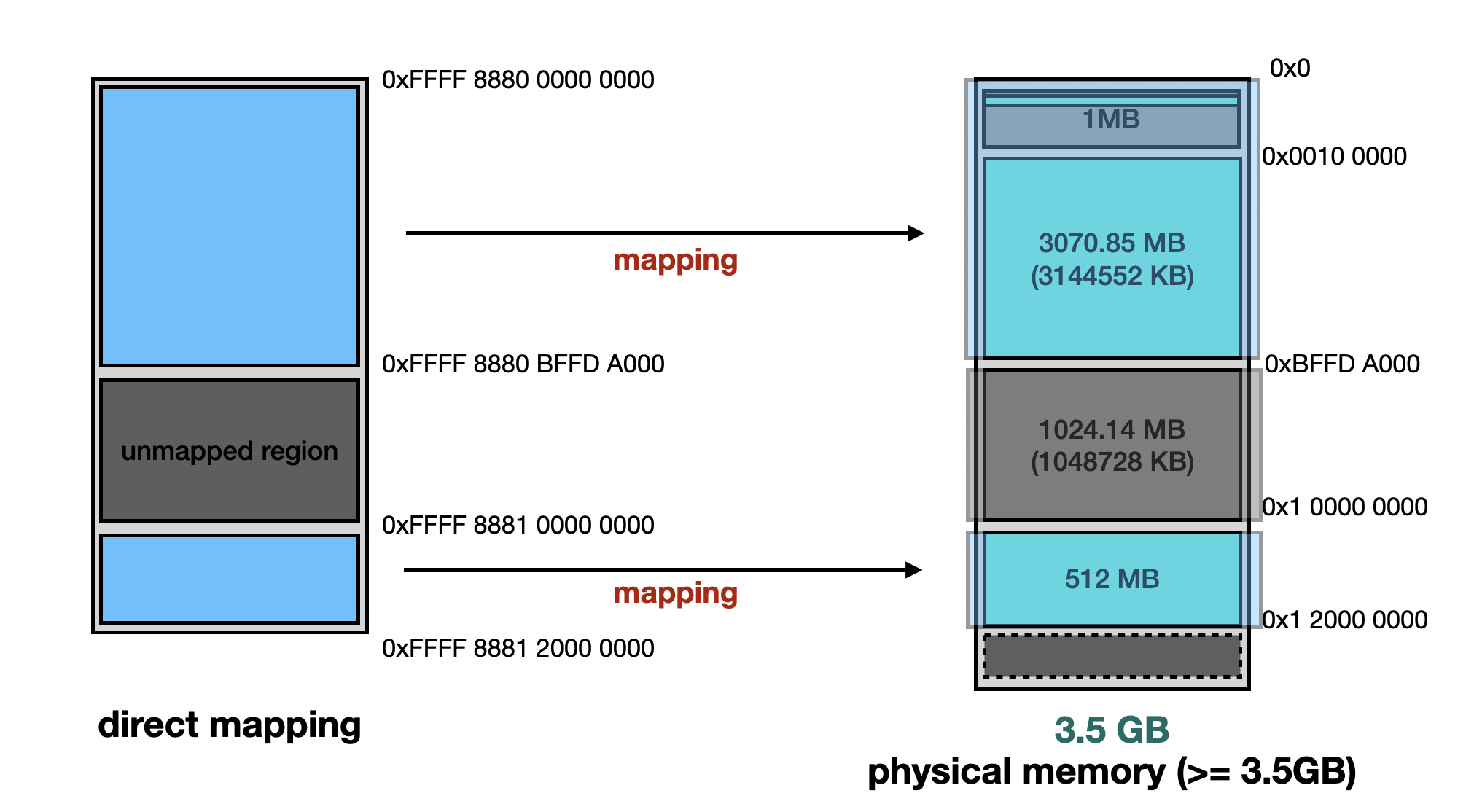
It can be observed that when RAM ≥ 3.5 GB, the physical memory is split into two separate regions, as shown in the figure below:
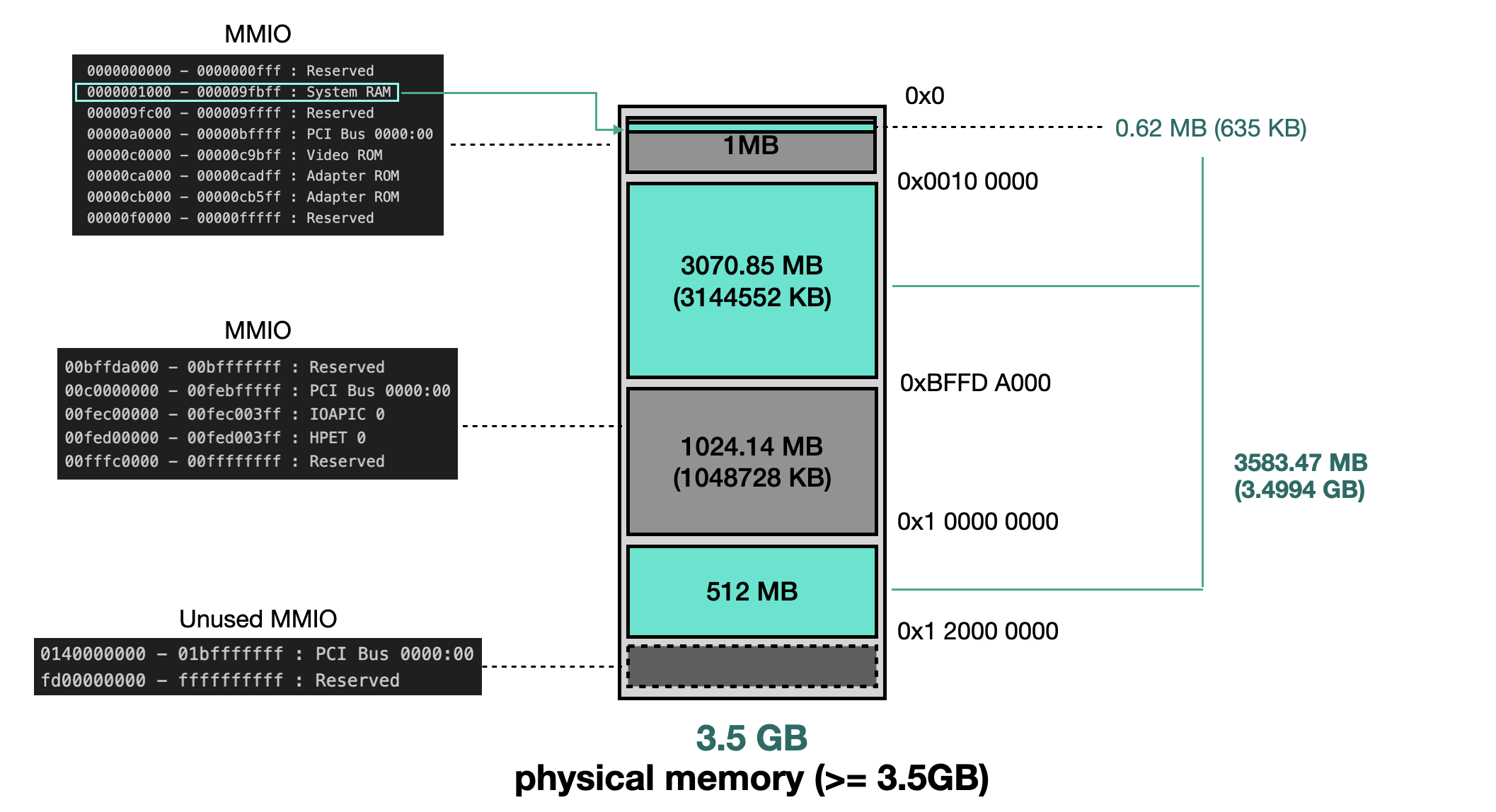
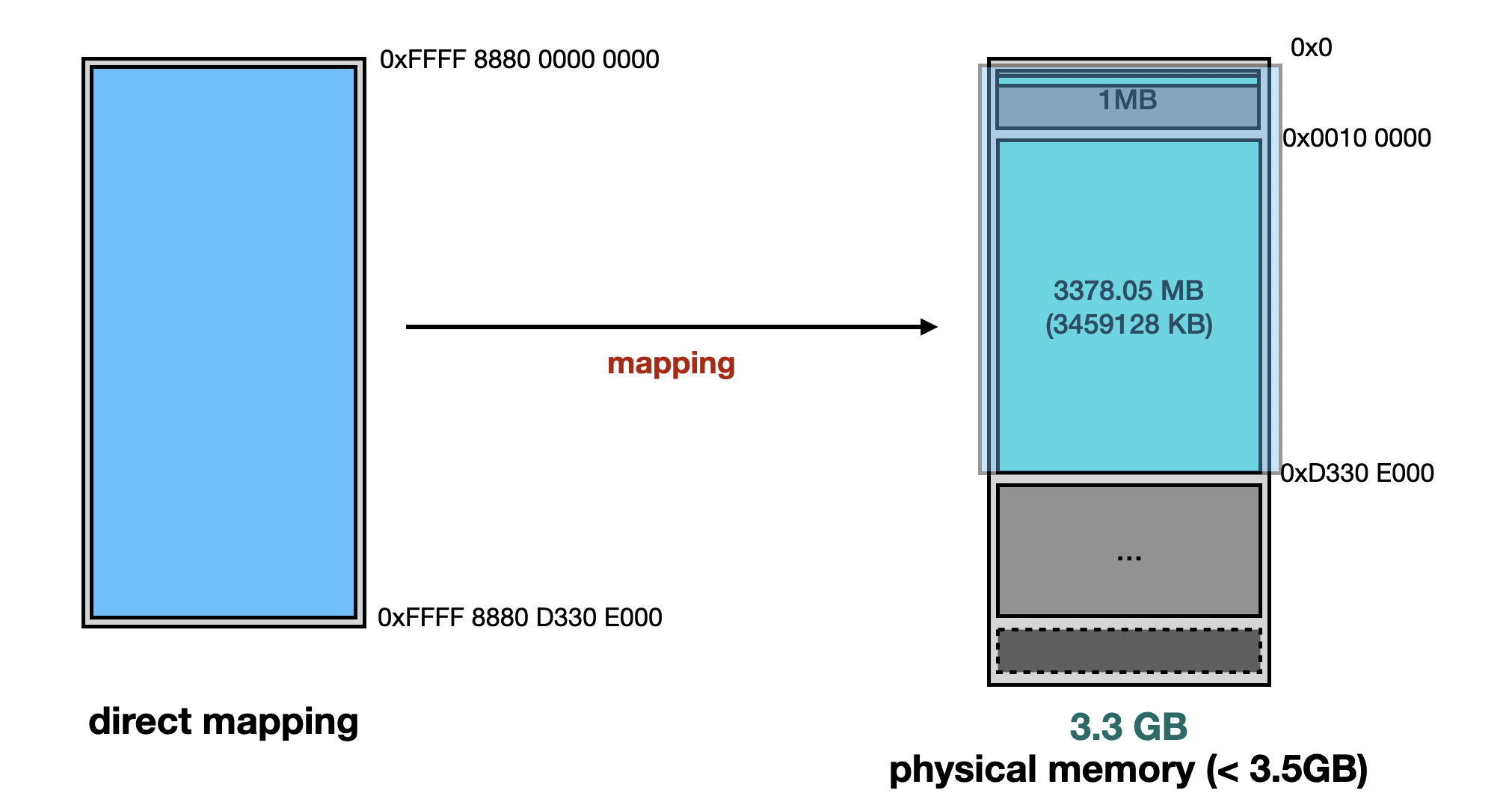
If RAM ≥ 3.5 GB, the first 3 GB remains in its original location, while the remaining portion is mapped to the physical address 0x100000000.
Direct Mapping focuses on mapping system RAM to virtual memory. If a physical address is used for MMIO mapping, Direct Mapping will exclude it. As a result, any attempt to access that region will trigger a page fault.
Zone is responsible for Direct Mapping memory, and in a NUMA architecture, each node maintains its own Zone. There are multiple types of Zone, and which Zone types are included depends on the kernel configuration at compile time. In the kernelCTF environment, there are five Zone types: DMA, DMA32, Normal, Movable, and Device.
// include/linux/mmzone.h
typedef struct pglist_data {
struct zone node_zones[MAX_NR_ZONES];
// [...]
}
enum zone_type {
ZONE_DMA,
ZONE_DMA32,
ZONE_NORMAL,
ZONE_MOVABLE,
ZONE_DEVICE,
__MAX_NR_ZONES
};
2. Zone
Anyone familiar with Linux kernel memory management knows about the Buddy System and Slab Allocator. The Buddy System serves as the backend for the Slab Allocator, while Zone can be thought of as the backend for the Buddy System.
The relationship between these three components can be represented as follows:
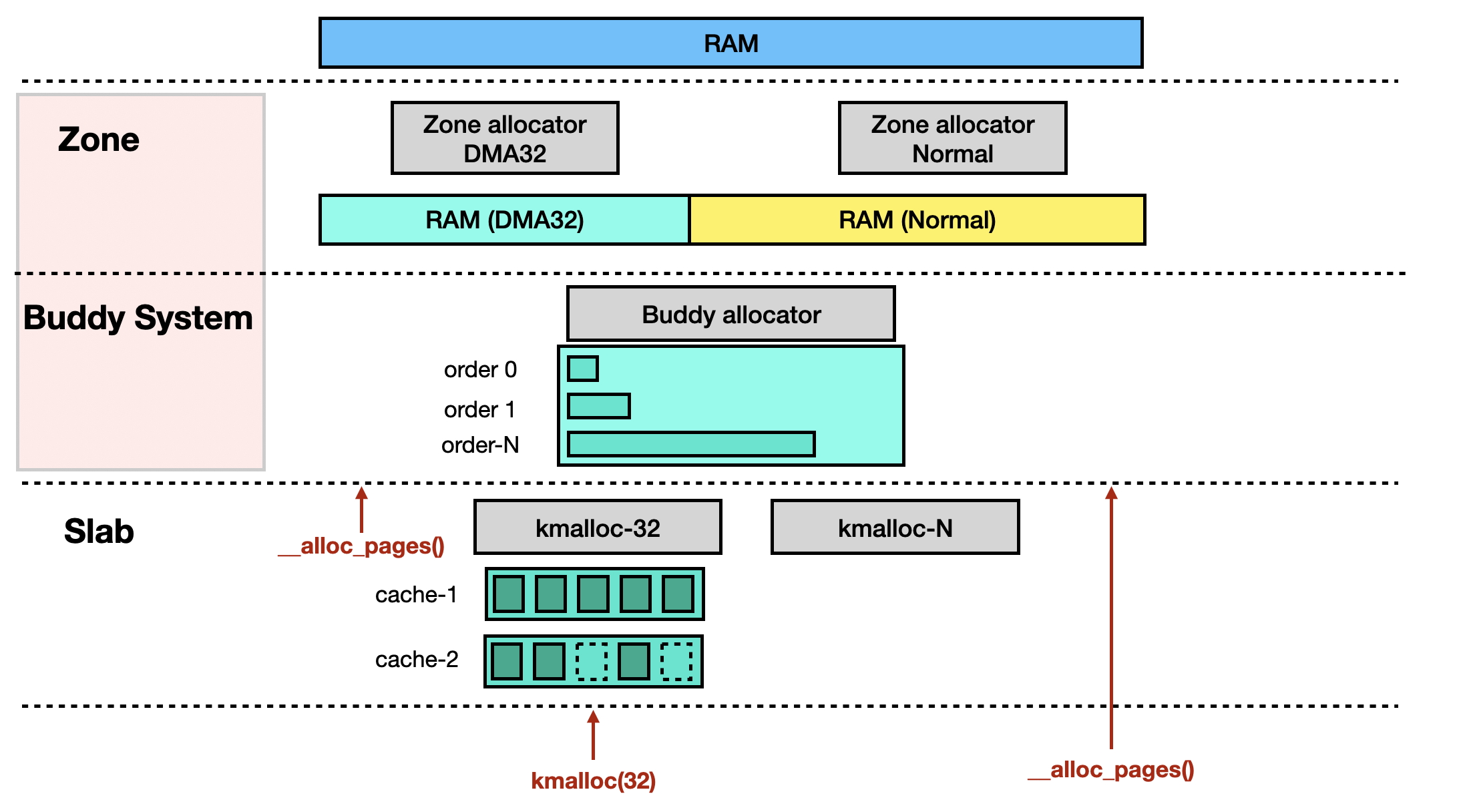
Next, let’s trace Zone design from the source code.
2.1. Exposed API
We start with the __alloc_pages() function. According to the comments in the source code, this is a key API for page allocation.
/*
* This is the 'heart' of the zoned buddy allocator.
*/
struct page *__alloc_pages(gfp_t gfp, unsigned int order, int preferred_nid,
nodemask_t *nodemask)
{
/* First allocation attempt */
page = get_page_from_freelist(alloc_gfp, order, alloc_flags, &ac); // <---------------
// [...]
}
/*
* get_page_from_freelist goes through the zonelist trying to allocate
* a page.
*/
static struct page *
get_page_from_freelist(gfp_t gfp_mask, unsigned int order, int alloc_flags,
const struct alloc_context *ac)
{
// [...]
page = rmqueue(ac->preferred_zoneref->zone, zone, order, // <---------------
gfp_mask, alloc_flags, ac->migratetype);
// [...]
}
In the function rmqueue(), there are two ways to obtain a page. The first is from the per-CPU list, and the second is by requesting it from the Buddy System.
When the requested page order is small, the function rmqueue_pcplist() is called to retrieve pages from the per-CPU list [1]. If that fails, it falls back to the function rmqueue_buddy() [2].
/*
* Allocate a page from the given zone.
* ...
*/
static inline
struct page *rmqueue(struct zone *preferred_zone,
struct zone *zone, unsigned int order,
gfp_t gfp_flags, unsigned int alloc_flags,
int migratetype)
{
// [...]
if (pcp_allowed_order(order) /* order < 3 */) {
page = rmqueue_pcplist(preferred_zone, zone, order, // [1]
migratetype, alloc_flags);
if (page)
goto out;
}
// or
page = rmqueue_buddy(preferred_zone, zone, order, alloc_flags, // [2]
migratetype);
// [...]
}
2.2. Allocated From Per-CPU List
Zone has a per-CPU page set [1], which can be thought of as a page cache maintained independently by each CPU.
static struct page *rmqueue_pcplist(struct zone *preferred_zone,
struct zone *zone, unsigned int order,
int migratetype, unsigned int alloc_flags)
{
struct per_cpu_pages *pcp;
struct list_head *list;
struct page *page;
// [...]
pcp = pcp_spin_trylock(zone->per_cpu_pageset); // [1]
// [...]
list = &pcp->lists[order_to_pindex(migratetype, order)];
page = __rmqueue_pcplist(zone, order, migratetype, alloc_flags, pcp, list);
// [...]
}
When __rmqueue_pcplist() detects that the per-CPU list is empty [2], it calls rmqueue_bulk() [3] to preallocate multiple pages.
/* Remove page from the per-cpu list, ... */
static inline
struct page *__rmqueue_pcplist(struct zone *zone, unsigned int order,
int migratetype,
unsigned int alloc_flags,
struct per_cpu_pages *pcp,
struct list_head *list)
{
struct page *page;
do {
if (list_empty(list)) { // [2]
int batch = READ_ONCE(pcp->batch);
int alloced;
// [...]
alloced = rmqueue_bulk(zone, order, // [3]
batch, list,
migratetype, alloc_flags);
pcp->count += alloced << order;
// [...]
}
page = list_first_entry(list, struct page, pcp_list);
list_del(&page->pcp_list);
pcp->count -= 1 << order;
} while (check_new_pages(page, order));
return page;
}
The function rmqueue_bulk() calls __rmqueue() to allocate pages [4] and adds the returned pages to the per-CPU list first [5].
/*
* Obtain a specified number of elements from the buddy allocator, ...
*/
static int rmqueue_bulk(struct zone *zone, unsigned int order,
unsigned long count, struct list_head *list,
int migratetype, unsigned int alloc_flags)
{
for (i = 0; i < count; ++i) {
struct page *page = __rmqueue(zone, order, migratetype, // [4]
alloc_flags);
list_add_tail(&page->pcp_list, list); // [5]
// [...]
}
// [...]
}
Since __rmqueue() is also called by another API, rmqueue_buddy(), we will introduce it later.
2.3. Allocated From Buddy System
The function rmqueue_buddy() just calls __rmqueue() directly [1] and returns pages without adding it to a cache list like the per-CPU list.
static __always_inline
struct page *rmqueue_buddy(struct zone *preferred_zone, struct zone *zone,
unsigned int order, unsigned int alloc_flags,
int migratetype)
{
struct page *page;
do {
// [...]
page = __rmqueue(zone, order, migratetype, alloc_flags); // [1]
// [...]
} while (check_new_pages(page, order));
return page;
}
2.4. Core Function: __rmqueue
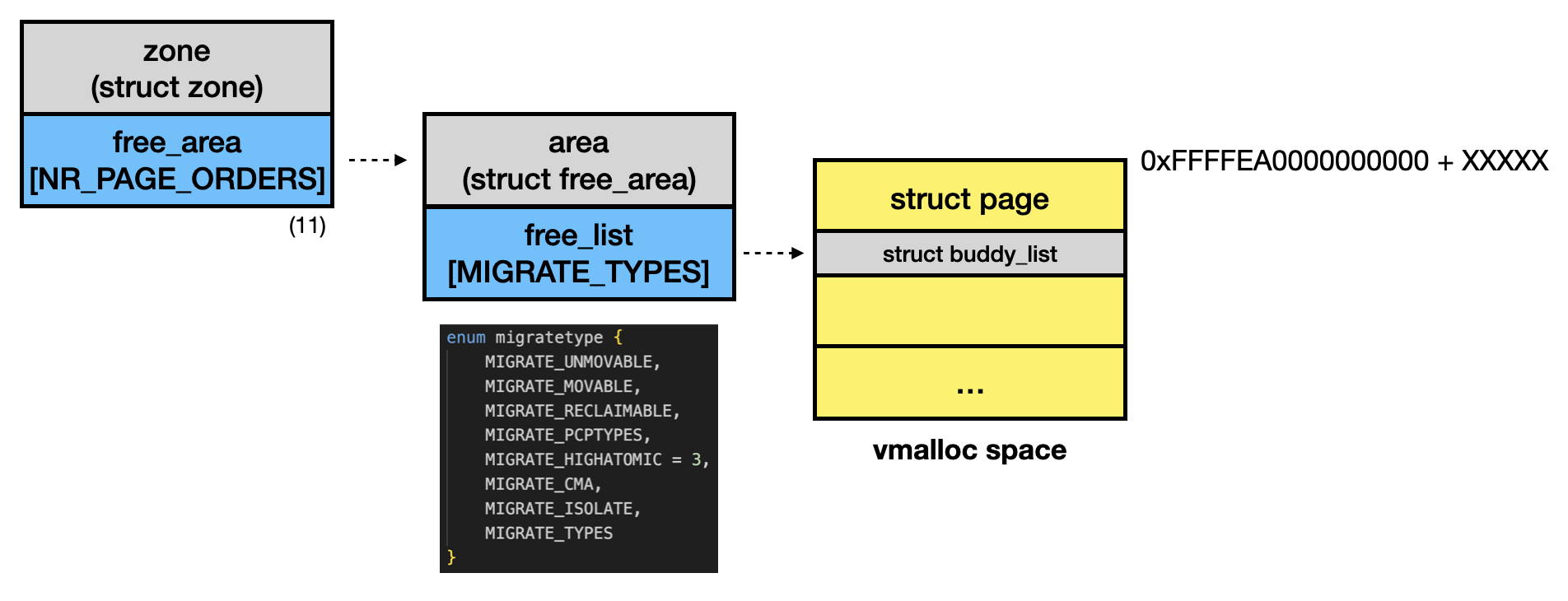
The function __rmqueue() retrieves pages from the Buddy Allocator and returns them. It first attempts to call __rmqueue_smallest() [1], iterating through zone->free_area[] [2] using the requested order as an index, up to NR_PAGE_ORDERS (11). After that, it retrieves a free page from the corresponding area [3]. If a suitable page is found, it is returned immediately.
/*
* Do the hard work of removing an element from the buddy allocator.
* Call me with the zone->lock already held.
*/
static __always_inline struct page *
__rmqueue(struct zone *zone, unsigned int order, int migratetype,
unsigned int alloc_flags)
{
retry:
// [...]
page = __rmqueue_smallest(zone, order, migratetype); // [1]
// [...]
if (!page && __rmqueue_fallback(zone, order, migratetype,
alloc_flags))
goto retry;
}
struct page *__rmqueue_smallest(struct zone *zone, unsigned int order,
int migratetype)
{
unsigned int current_order;
struct free_area *area;
struct page *page;
/* Find a page of the appropriate size in the preferred list */
for (current_order = order; current_order < NR_PAGE_ORDERS; ++current_order) {
area = &(zone->free_area[current_order]); // [2]
page = get_page_from_free_area(area, migratetype); // <---------------
if (!page)
continue;
del_page_from_free_list(page, zone, current_order);
expand(zone, page, order, current_order, migratetype);
// [...]
return page; // [3]
}
// [...]
}
static inline struct page *get_page_from_free_area(struct free_area *area,
int migratetype)
{
return list_first_entry_or_null(&area->free_list[migratetype], // [3]
struct page, buddy_list);
}
If no suitable page is found, __rmqueue() calls the function __rmqueue_fallback() [4] to steal pages from a higher-order area [5].
/*
* Try finding a free buddy page on the fallback list and put it on the free
* list of requested migratetype, ...
*/
static __always_inline bool
__rmqueue_fallback(struct zone *zone, int order, int start_migratetype,
unsigned int alloc_flags)
{
struct free_area *area;
int current_order;
int min_order = order;
struct page *page;
int fallback_mt;
bool can_steal;
// [...]
for (current_order = MAX_ORDER; current_order >= min_order; --current_order) {
area = &(zone->free_area[current_order]); // [4]
fallback_mt = find_suitable_fallback(area, current_order,
start_migratetype, false, &can_steal);
if (fallback_mt == -1)
continue;
// [...]
goto do_steal;
}
// [...]
do_steal:
page = get_page_from_free_area(area, fallback_mt); // [5]
steal_suitable_fallback(zone, page, alloc_flags, start_migratetype,
can_steal);
// [...]
return true;
}
The find_suitable_fallback() determines which migrate type to use for stealing pages from the free area based on the fallbacks[] array [6].
int find_suitable_fallback(struct free_area *area, unsigned int order,
int migratetype, bool only_stealable, bool *can_steal)
{
int i;
int fallback_mt;
if (area->nr_free == 0)
return -1;
*can_steal = false;
for (i = 0; i < MIGRATE_PCPTYPES - 1 ; i++) {
fallback_mt = fallbacks[migratetype][i]; // [6]
if (free_area_empty(area, fallback_mt))
continue;
if (can_steal_fallback(order, migratetype))
*can_steal = true;
// [...]
if (*can_steal)
return fallback_mt;
}
// [...]
}
Finally, the relationship between Zone, areas, and pages can be illustrated in the following diagram:
3. Zone vs. 3.5 GB
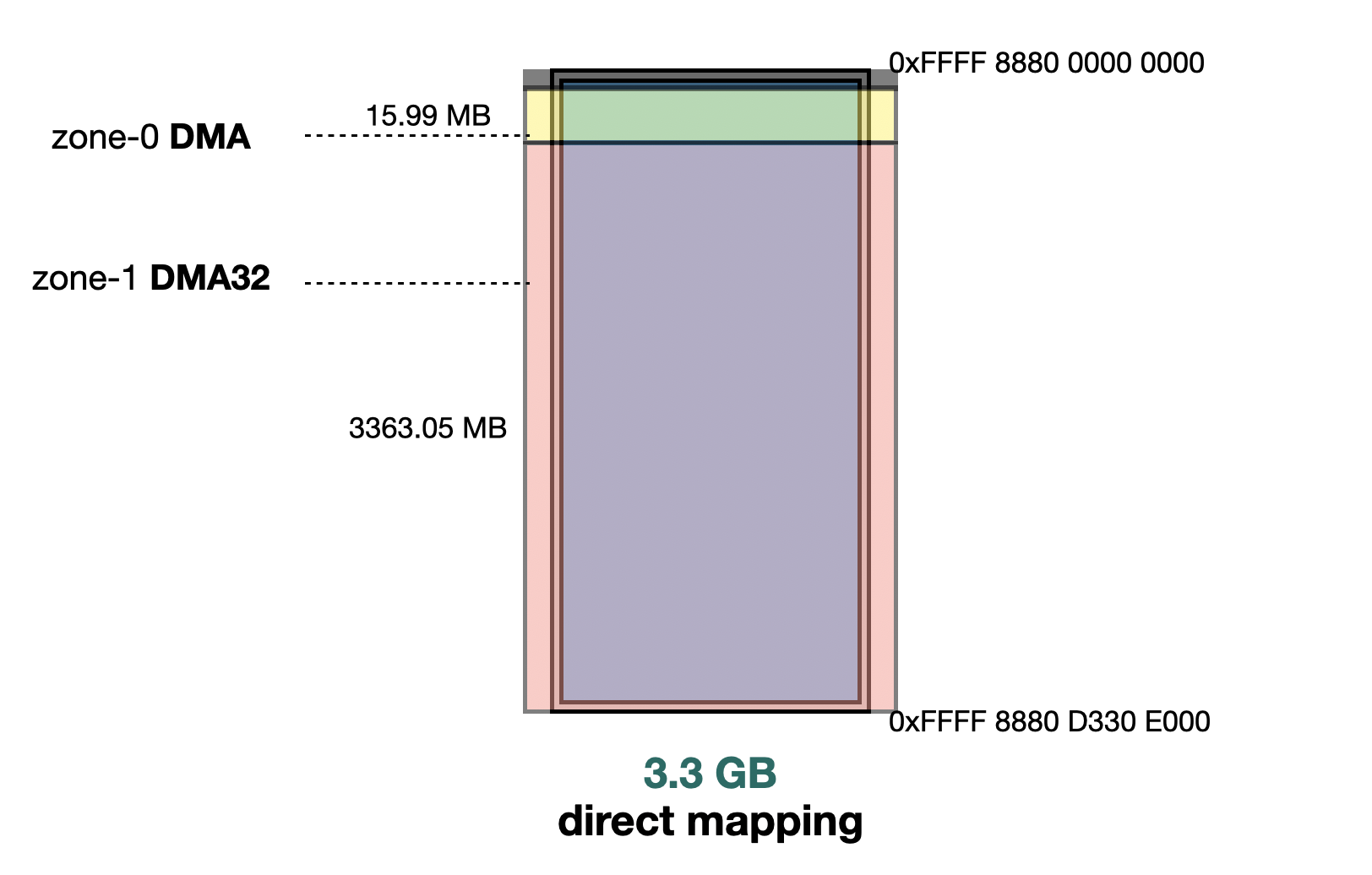
When RAM is < 3.5 GB, the kernel enables only two types of Zone: DMA and DMA32.
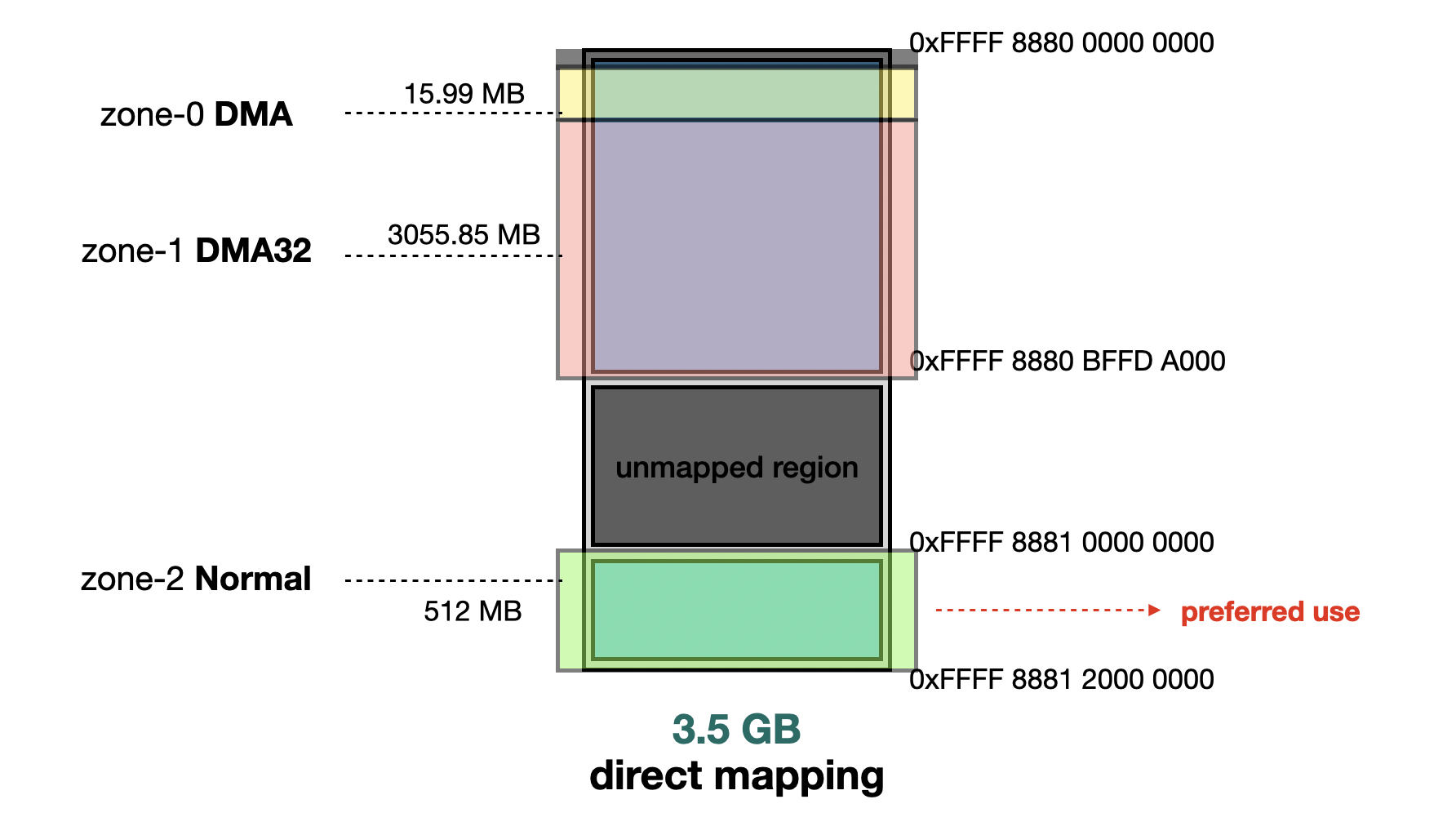
However, when RAM ≥ 3.5 GB, the kernel additionally enables the Normal Zone, and unless specific GFP flags (Get Free Pages) are provided, pages are allocated from the Normal Zone by default.
The current usage status of Zone can be obtained from the pseudo file /proc/zoneinfo, which may be particularly useful for heap spraying.
Node 0, zone DMA32
pages free 742675
boost 0
min 14557
low 18196
high 21835
spanned 1044480
present 782298
managed 753589
cma 0
protection: (0, 0, 448, 448, 448)
nr_free_pages 742675
[...]
[...]
start_pfn: 4096
Node 0, zone Normal
pages free 92373
boost 0
min 2262
low 2827
high 3392
spanned 131072
present 131072
managed 114861
cma 0
protection: (0, 0, 0, 0, 0)
nr_free_pages 92373
[...]
[...]
start_pfn: 1048576