Understanding Socket Internals Through a Series of CVE Fixes
It’s common to see the following code pattern in the release handlers of network protocols:
int XXX_release(struct socket *sock)
{
struct sock *sk = sock->sk;
// [...]
sock_orphan(sk); // if the network protocol supports transmission
// [...]
sock->sk = NULL;
sock_put(sk);
// [...]
return 0;
}
While unbinding the struct socket from its associated struct sock is a normal part of the resource cleanup process, a question arises: what happens if we forget to set sock->sk to NULL before returning, or accidentally omit the call to sock_orphan(sk)?
Would that lead to any issues in the subsequent execution? If so, under what circumstances would such problems be triggered?
This article takes a closer look at the significance of these two lines, referencing several historical CVEs and commits to highlight their importance.
1. Introduction
Let’s start by examining how a socket is implemented in a more recent version of the Linux kernel (v6.6.64).
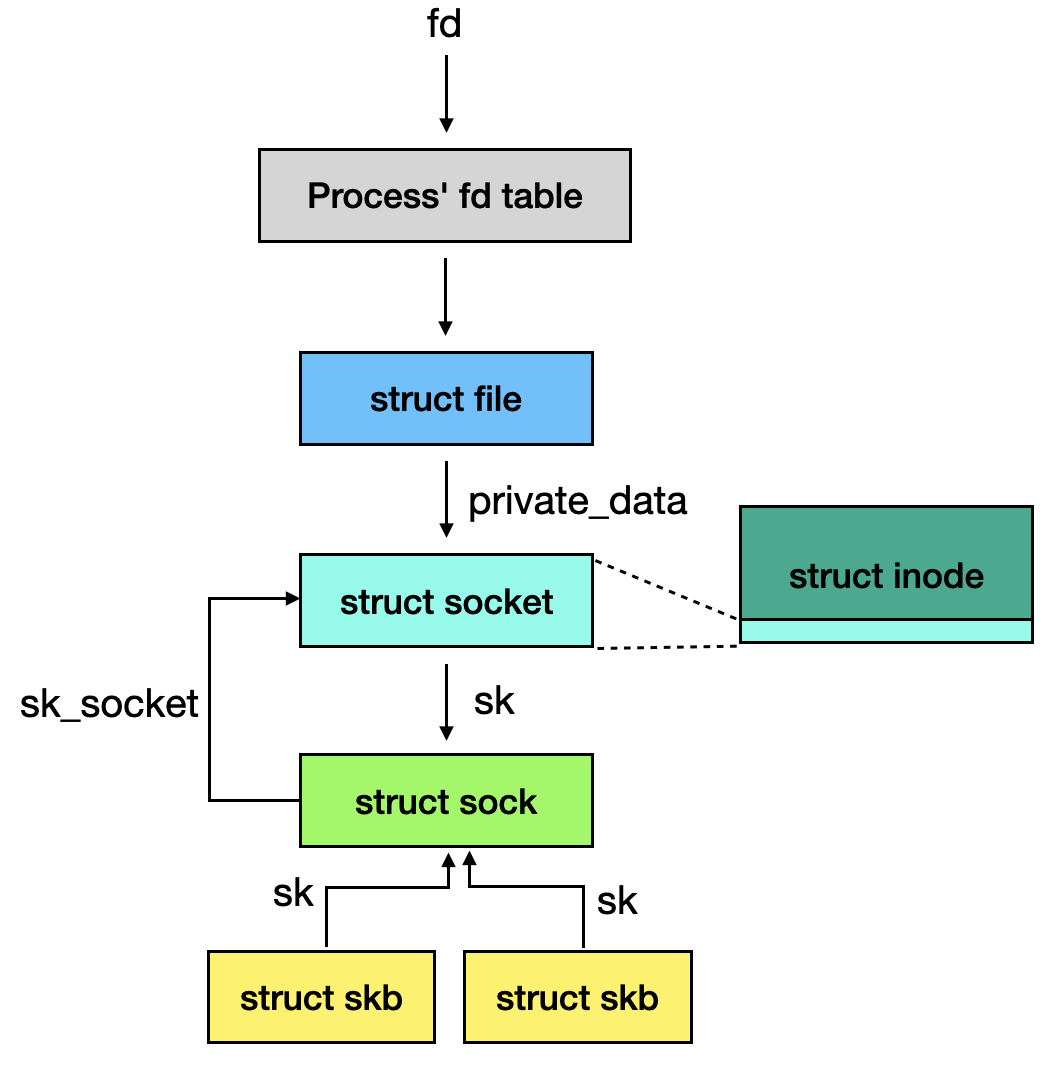
1.1. Allocation
The simplest way to create a socket is by calling the SYS_socket system call. This syscall first initializes a network socket [1], then allocates a struct file associated with a struct socket [2], and finally returns a fd to the calling process. The process can then interact with the socket using standard file operations.
SYSCALL_DEFINE3(socket, int, family, int, type, int, protocol)
{
return __sys_socket(family, type, protocol);
}
int __sys_socket(int family, int type, int protocol)
{
struct socket *sock;
// [...]
sock = __sys_socket_create(family, type, // [1]
update_socket_protocol(family, type, protocol));
// [...]
return sock_map_fd(sock, flags & (O_CLOEXEC | O_NONBLOCK));
}
static int sock_map_fd(struct socket *sock, int flags)
{
struct file *newfile;
int fd = get_unused_fd_flags(flags);
// [...]
newfile = sock_alloc_file(sock, flags, NULL); // [2] set `newfile->private_data` to `sock` internally
fd_install(fd, newfile);
return fd;
}
During the socket initialization process, a corresponding network protocol (e.g., AF_ALG in this example) allocates a struct sock object [3]. Then, the internal functions establish the relationship between the struct socket and struct sock [4, 5].
static struct socket *__sys_socket_create(int family, int type, int protocol)
{
// [...]
retval = sock_create(family, type, protocol, &sock); // <-------------------
// [...]
}
int sock_create(int family, int type, int protocol, struct socket **res)
{
return __sock_create(current->nsproxy->net_ns, family, type, protocol, res, 0); // <-------------------
}
int __sock_create(struct net *net, int family, int type, int protocol,
struct socket **res, int kern)
{
struct socket *sock;
// [...]
sock = sock_alloc();
// [...]
pf = rcu_dereference(net_families[family]);
// [...]
err = pf->create(net, sock, protocol, kern);
// [...]
}
static int alg_create(struct net *net, struct socket *sock, int protocol,
int kern)
{
struct sock *sk;
// [...]
sk = sk_alloc(net, PF_ALG, GFP_KERNEL, &alg_proto, kern); // [3]
// [...]
sock_init_data(sock, sk);
// [...]
return 0;
}
void sock_init_data(struct socket *sock, struct sock *sk)
{
// [...]
sock_init_data_uid(sock, sk, uid);
}
void sock_init_data_uid(struct socket *sock, struct sock *sk, kuid_t uid)
{
// [...]
sk_set_socket(sk, sock);
// [...]
sock->sk = sk; // [5]
// [...]
}
static inline void sk_set_socket(struct sock *sk, struct socket *sock)
{
sk->sk_socket = sock; // [4]
}
One interesting detail is that the struct socket object isn’t simply allocated via kmalloc(); instead, it’s embedded as a private object within a struct inode.
struct socket *sock_alloc(void)
{
struct inode *inode;
struct socket *sock;
inode = new_inode_pseudo(sock_mnt->mnt_sb);
// [...]
sock = SOCKET_I(inode);
// [...]
return sock;
}
static inline struct socket *SOCKET_I(struct inode *inode)
{
return &container_of(inode, struct socket_alloc, vfs_inode)->socket;
}
If the network protocol supports data transmission, the kernel allocates struct skb objects to track each packet. For example, in the AF_UNIX family, the unix_stream_sendmsg() function handles sending packets through a UNIX socket. Internally, it calls skb_set_owner_w() to set skb->sk to the associated struct sock object [6].
static int unix_stream_sendmsg(struct socket *sock, struct msghdr *msg,
size_t len)
{
// [...]
skb = sock_alloc_send_pskb(sk, size - data_len, data_len, /*...*/); // <-------------------
// [...]
}
struct sk_buff *sock_alloc_send_pskb(struct sock *sk, unsigned long header_len,
unsigned long data_len, /*...*/)
{
// [...]
skb = alloc_skb_with_frags(header_len, data_len, max_page_order,
errcode, sk->sk_allocation);
// [...]
if (skb)
skb_set_owner_w(skb, sk); // <-------------------
return skb;
}
void skb_set_owner_w(struct sk_buff *skb, struct sock *sk)
{
// [...]
skb->sk = sk; // [6]
// [...]
refcount_add(skb->truesize, &sk->sk_wmem_alloc);
}
In short, the relationships among these kernel structures can be summarized as follows:
1.2. Release
When the refcount of a struct file drops to zero, the file’s release handler is invoked. For socket files, the release handler is sock_close().
static const struct file_operations socket_file_ops = {
// [...]
.release = sock_close,
// [...]
};
static int sock_close(struct inode *inode, struct file *filp)
{
__sock_release(SOCKET_I(inode), inode);
// [...]
}
The __sock_release() function handles the actual cleanup. While holding the inode lock, it calls the protocol-specific release handler [1].
static void __sock_release(struct socket *sock, struct inode *inode)
{
const struct proto_ops *ops = READ_ONCE(sock->ops);
// [...]
if (inode)
inode_lock(inode);
ops->release(sock); // [1]
sock->sk = NULL;
if (inode)
inode_unlock(inode);
// [...]
iput(SOCK_INODE(sock));
return;
}
For example, in the AF_ALG protocol, the release handler drops the reference to the underlying struct sock [2] object and clears the sock->sk [3] pointer.
int af_alg_release(struct socket *sock)
{
if (sock->sk) {
sock_put(sock->sk); // [2]
sock->sk = NULL; // [3]
}
return 0;
}
2. CVE-2018-12232: socket: close race condition between sock_close() and sockfs_setattr()
The first case we’ll look at is CVE-2018-12232. The analysis here is based on the latest kernel.
The SYS_fchownat system call allows modifying an inode’s ownership without requiring a reference to a struct file. Internally, it invokes the inode’s setattr handler while holding the inode lock [1].
SYSCALL_DEFINE5(fchownat, int, dfd, const char __user *, filename, uid_t, user,
gid_t, group, int, flag)
{
return do_fchownat(dfd, filename, user, group, flag); // <---------------
}
int do_fchownat(int dfd, const char __user *filename, uid_t user, gid_t group,
int flag)
{
// [...]
retry:
error = user_path_at(dfd, filename, lookup_flags, &path); // inc inode refcount
// [...]
error = chown_common(&path, user, group); // <---------------
// [...]
path_put(&path); // dec inode refcount
// [...]
out:
return error;
}
int chown_common(const struct path *path, uid_t user, gid_t group)
{
struct inode *inode = path->dentry->d_inode;
// [...]
inode_lock(inode);
// [...]
error = notify_change(idmap, path->dentry, &newattrs, // <---------------
&delegated_inode);
// [...]
inode_unlock(inode);
// [...]
}
int notify_change(struct mnt_idmap *idmap, struct dentry *dentry,
struct iattr *attr, struct inode **delegated_inode)
{
// [...]
if (inode->i_op->setattr)
error = inode->i_op->setattr(idmap, dentry, attr); // [1]
// [...]
}
Since struct socket is embedded in the inode’s private data, the sockfs filesystem’s setattr handler (sockfs_setattr()) retrieves the struct socket object from the inode [2], then updates the underlying struct sock’s sk_uid field [3].
static const struct inode_operations sockfs_inode_ops = {
// [...]
.setattr = sockfs_setattr,
};
static int sockfs_setattr(struct mnt_idmap *idmap,
struct dentry *dentry, struct iattr *iattr)
{
int err = simple_setattr(&nop_mnt_idmap, dentry, iattr);
if (!err && (iattr->ia_valid & ATTR_UID)) {
struct socket *sock = SOCKET_I(d_inode(dentry)); // [2]
if (sock->sk)
sock->sk->sk_uid = iattr->ia_uid; // [3]
// [...]
}
}
However, prior to the patch, the socket release handler didn’t account for scenarios where the struct file reference count had dropped to zero - yet other access paths (like through the inode) still existed. Depending on the network protocol’s implementation, this could lead to a NULL pointer dereference or even a UAF vulnerability.
As part of the fix, the patch added an inode_lock() before invoking the socket’s release handler:
+static void __sock_release(struct socket *sock, struct inode *inode)
// [...]
+ if (inode)
+ inode_lock(inode);
sock->ops->release(sock);
+ if (inode)
+ inode_unlock(inode);
Additionally, the sockfs_setattr() checks for a NULL sock->sk now. If sock->sk is already released, the handler just returns an error:
@@ -541,7 +541,10 @@ static int sockfs_setattr(struct dentry *dentry, struct iattr *iattr)
// [...]
- sock->sk->sk_uid = iattr->ia_uid;
+ if (sock->sk)
+ sock->sk->sk_uid = iattr->ia_uid;
+ else
+ err = -ENOENT;
Although this patch seems to resolve the immediate race condition, it does not fully eliminate the underlying risk.
3. CVE-2019-8912: net: crypto set sk to NULL when af_alg_release
Although the commit for CVE-2018-12232 successfully eliminates the race condition, the socket release handler itself cannot guarantee that the underlying protocol-specific release handler properly frees all associated objects.
CVE-2019-8912 is a direct result of this limitation. In the AF_ALG implementation, the protocol release handler forgot to set sock->sk to NULL. As a consequence, after __sock_release() unlocked the inode, it was still possible to invoke SYS_fchownat and write to sock->sk->sk_uid. However, at that point, the sock->sk object had already been freed, leading to a UAF vulnerability.
The patch addressing this issue is straightforward: explicitly clear sock->sk in the AF_ALG release handler:
int af_alg_release(struct socket *sock)
{
- if (sock->sk)
+ if (sock->sk) {
sock_put(sock->sk);
+ sock->sk = NULL;
+ }
return 0;
}
It’s why we need to clear sock->sk to NULL immediately after releasing the associated struct sk object 🙂.
4. net: socket: set sock->sk to NULL after calling proto_ops::release()
https://web.git.kernel.org/pub/scm/linux/kernel/git/stable/linux.git/commit/?id=ff7b11aa481f
With more and more network protocols being added, it became easy to miss clearing sock->sk in one of them - and that’s all it takes to bring back a UAF.
To address this more robustly, the maintainer finally decided to reset sock->sk directly within __sock_release(), ensuring that the pointer is cleared regardless of how the underlying protocol handles its own cleanup.
@@ -577,6 +577,7 @@ static void __sock_release(struct socket *sock, struct inode *inode)
if (inode)
inode_lock(inode);
sock->ops->release(sock);
+ sock->sk = NULL;
if (inode)
inode_unlock(inode);
5. CVE-2024-26625: llc: call sock_orphan() at release time
After the sock->sk issue was addressed, a new vulnerability - CVE-2024-26625 - emerged in early 2024. This time, the root cause was a missing call to sock_orphan() in the AF_LLC protocol’s release handler, which again led to a UAF.
The fix was minimal - just two lines - but the key was the addition of a sock_orphan() call.
@@ -226,6 +226,8 @@ static int llc_ui_release(struct socket *sock)
}
netdev_put(llc->dev, &llc->dev_tracker);
sock_put(sk);
+ sock_orphan(sk);
+ sock->sk = NULL;
The sock_orphan() function not only updates the internal socket state but also clears the sk->sk_socket pointer and resets the associated workqueue. By default, this workqueue pointer is initialized to point to the struct socket’s wq field when the struct sock is set up [1].
static inline void sock_orphan(struct sock *sk)
{
write_lock_bh(&sk->sk_callback_lock);
sock_set_flag(sk, SOCK_DEAD);
sk_set_socket(sk, NULL); // sk->sk_socket = NULL
sk->sk_wq = NULL;
write_unlock_bh(&sk->sk_callback_lock);
}
void sock_init_data_uid(struct socket *sock, struct sock *sk, kuid_t uid)
{
// [...]
RCU_INIT_POINTER(sk->sk_wq, &sock->wq); // [1]
// [...]
}
So what happens if sock_orphan() isn’t called?
In protocols that support packet transmission, the struct sock can be referenced not only by the struct socket but also by queued packets (struct skb). This means the struct socket object can be freed before the struct sock object.
Packets pending in the transmit queue are processed by softirq handlers. One handler called internally is napi_consume_skb(), which eventually releases unsent packets:
void napi_consume_skb(struct sk_buff *skb, int budget)
{
// [...]
skb_release_all(skb, SKB_CONSUMED, !!budget); // <---------------
// [...]
}
static void skb_release_all(struct sk_buff *skb, enum skb_drop_reason reason,
bool napi_safe)
{
skb_release_head_state(skb); // <---------------
// [...]
}
void skb_release_head_state(struct sk_buff *skb)
{
// [...]
// `skb->destructor` is set to `sock_wfree()` in `__ip_append_data()`
if (skb->destructor) {
skb->destructor(skb); // <---------------
}
// [...]
}
The packet destructor - typically sock_wfree() - is responsible for adjusting the reference count on the associated struct sock [2] and waking up any waiting processes. However, if the struct socket has already been freed, accessing the socket’s workqueue (i.e., the wq field) [3] results in a UAF.
void sock_wfree(struct sk_buff *skb)
{
struct sock *sk = skb->sk;
unsigned int len = skb->truesize;
bool free;
if (!sock_flag(sk, SOCK_USE_WRITE_QUEUE)) {
if (sock_flag(sk, SOCK_RCU_FREE) &&
sk->sk_write_space == sock_def_write_space) {
// [...]
free = refcount_sub_and_test(len, &sk->sk_wmem_alloc); // [2]
sock_def_write_space_wfree(sk);
// [...]
return;
}
// [...]
}
// [...]
}
static void sock_def_write_space_wfree(struct sock *sk)
{
// [...]
if (sock_writeable(sk)) {
struct socket_wq *wq = rcu_dereference(sk->sk_wq);
// [...]
if (wq && waitqueue_active(&wq->wait)) { // [3]
// [...]
}
}
// [...]
}
As a result, if a network protocol supports packet transmission, it must call sock_orphan() in its release handler. Otherwise, it risks triggering a UAF when the workqueue is accessed by late-arriving or pending skb objects.