Docker Internal (2)
In the last post, we introduced the relationship between the components in the Docker system, and in this post, we’ll discuss the attack surfaces.
1. Pull an Image
Imagine you just run docker pull <image> and then you’ve been pwned (just an example 😝). Yeah, the first attack surface is quite straigtforward: when you download a malicious image which is published by an attacker, the Docker daemon parses the metadata, extract the compressed files, and save them into the filesystem. During this process, the crafted file may affect host data if bugs or vulnerabilities exist.
In this post, we’ll analyze how Docker pulls an image, parses the metadata, and extract the files. We’ll also explore potential attack surfaces in the end.
1.1. Setup Environment
To understand the image fetching process, we can run a proxy and intercept the HTTP request between the daemon and the registry server. Here, I use mitmproxy:
mitmproxy --listen-host 127.0.0.1 --listen-port 8080
And write the config below to /etc/systemd/system/docker.service.d/http-proxy.conf:
[Service]
Environment="HTTP_PROXY=http://127.0.0.1:8080"
Environment="HTTPS_PROXY=http://127.0.0.1:8080"
Then restart the dockerd daemon to reload the configuration:
sudo systemctl daemon-reload # reload config
sudo systemctl restart docker # restart dockerd
After that, you can read the intercepted HTTP request in mitmproxy’s TUI when you run docker pull ubuntu:24.04:

1.2. Auth & HEAD Manifest
Run docker pull ubuntu:24.04 and the docker-cli sends the following HTTP request to dockerd:
POST /v1.54/images/create?fromImage=docker.io%2Flibrary%2Fubuntu&tag=24.04
Host: api.moby.localhost
User-Agent: Docker-Client/29.5.2 (linux)
Content-Length: 0
X-Registry-Auth: e30=
The pull image request is handled by the "/images/create" endpoint of dockerd, whose handler is postImagesCreate().
// daemon/server/router/image/image.go
func (ir *imageRouter) initRoutes() {
ir.routes = []router.Route{
// [...]
router.NewPostRoute("/images/create", ir.postImagesCreate),
}
}
pullTag() is called internally, and it creates a resolver object [1] and pulls the target image [2].
// daemon/server/router/image/image_routes.go
func (ir *imageRouter) postImagesCreate(ctx context.Context, w http.ResponseWriter, r *http.Request, vars map[string]string) error {
// [...]
if img != "" {
// ref = "docker.io/library/ubuntu:24.04" in here
progressErr = ir.backend.PullImage(ctx, ref, pullOptions) // <--------
}
// [...]
}
// daemon/containerd/image_pull.go
func (i *ImageService) PullImage(ctx context.Context, baseRef reference.Named, options imagebackend.PullOptions) (retErr error) {
// [...]
if !reference.IsNameOnly(baseRef) { // "docker.io/library/ubuntu:24.04" has tag "24.04"
return i.pullTag(ctx, baseRef, platform, options.MetaHeaders, options.AuthConfig, out) // <--------
}
// [...]
}
func (i *ImageService) pullTag(ctx context.Context, ref reference.Named, platform *ocispec.Platform, metaHeaders map[string][]string, authConfig *registrytypes.AuthConfig, out progress.Output) error {
// [...]
resolver, _ := i.newResolverFromAuthConfig(ctx, authConfig, ref, metaHeaders) // [1]
opts = append(opts, containerd.WithResolver(resolver))
// [...]
img, err := i.client.Pull(ctx, ref.String(), opts...) // [2]
// [...]
}
The resolver object is allocated and initialized by newResolverFromAuthConfig(), and eventually a dockerResolver object is returned [3].
// daemon/containerd/resolver.go
func (i *ImageService) newResolverFromAuthConfig(ctx context.Context, authConfig *registrytypes.AuthConfig, ref reference.Named, metaHeaders http.Header) (remotes.Resolver, docker.StatusTracker) {
// [...]
/**
* i.registryHosts
* == (daemon/containerd/service.go) config.RegistryHosts
* == (daemon/daemon.go) d.RegistryHosts
* == (daemon/hosts.go) func (daemon *Daemon) RegistryHosts(host string)
*/
hosts := hostsWrapper(i.registryHosts, authConfig, ref)
// [...]
return docker.NewResolver(docker.ResolverOptions{ // <--------
Hosts: hosts, // hosts == a wraper function of RegistryHosts()
Tracker: tracker,
Headers: headers,
})
}
// vendor/github.com/containerd/containerd/v2/core/remotes/docker/resolver.go
func NewResolver(options ResolverOptions) remotes.Resolver {
// [...]
return &dockerResolver{ // [3]
hosts: options.Hosts,
header: options.Headers,
resolveHeader: resolveHeader,
tracker: options.Tracker,
}
}
Pull() calls c.fetch() to download the target image [4] and then persists the image to containerd’s image metadata store [5].
// vendor/github.com/containerd/containerd/v2/client/pull.go
func (c *Client) Pull(ctx context.Context, ref string, opts ...RemoteOpt) (_ Image, retErr error) {
// [...]
img, err := c.fetch(ctx, pullCtx, ref, 1) // [4]
// [...]
img, err = c.createNewImage(ctx, img) // [5]
// [...]
}
fetch() is the key function, and here we only focus on the rCtx.Resolver.Resolve() call. It takes the ref as a parameter, which is a string including the image name and the tag (in our case, "docker.io/library/ubuntu:24.04").
// vendor/github.com/containerd/containerd/v2/client/pull.go
func (c *Client) fetch(ctx context.Context, rCtx *RemoteContext, ref string, limit int) (images.Image, error) {
// [...]
name, desc, err := rCtx.Resolver.Resolve(ctx, ref)
// [...]
}
desc is the Descriptor object, which describes a media resource. This structure is important because it not only helps you understand the standard for describing a container, but also contains the information about external resources, which may be attacker-controllable.
// vendor/github.com/opencontainers/image-spec/specs-go/v1/descriptor.go
type Descriptor struct {
MediaType string `json:"mediaType"`
Digest digest.Digest `json:"digest"`
Size int64 `json:"size"`
URLs []string `json:"urls,omitempty"`
Annotations map[string]string `json:"annotations,omitempty"`
Data []byte `json:"data,omitempty"`
Platform *Platform `json:"platform,omitempty"`
ArtifactType string `json:"artifactType,omitempty"`
}
How does Resolve() return a descriptor? It first gets the registry host based on the reference name [6], then decides which which built-in paths to use [7]. It then iterates over the paths and hosts, constructing a HEAD request to the remote registry [8] and sending it [9] with a retry mechanism.
// vendor/github.com/containerd/containerd/v2/core/remotes/docker/resolver.go
func (r *dockerResolver) Resolve(ctx context.Context, ref string) (string, ocispec.Descriptor, error) {
/**
* resolveDockerBase() -> r.base(refspec) -> r.hosts(host) -> RegistryHosts(host)
* base = { schema: "https", host: "registry-1.docker.io", ... }
*/
base, err := r.resolveDockerBase(ref) // [6]
// [...]
else {
paths = append(paths, []string{"manifests", refspec.Object}) // [7]
caps |= HostCapabilityResolve
}
// [...]
hosts := base.filterHosts(caps)
// [...]
for _, u := range paths { // [5]
for i, host := range hosts {
req := base.request(host, http.MethodHead, u...) // [8]
// [...]
resp, err := req.doWithRetries(ctx, true) // [9], HEAD "registry-1.docker.io/manifests"
// [...]
}
}
// [...]
}
doWithRetries() internally calls r.do(), which tries to send the request [10] and checks whether the request needs to be sent again [11].
// vendor/github.com/containerd/containerd/v2/core/remotes/docker/resolver.go
func (r *request) doWithRetries(ctx context.Context, lastHost bool, checks ...doChecks) (resp *http.Response, err error) {
resp, err = r.doWithRetriesInner(ctx, nil, lastHost) // <--------
// [...]
return resp
}
func (r *request) doWithRetriesInner(ctx context.Context, responses []*http.Response, lastHost bool) (*http.Response, error) {
resp, err := r.do(ctx) // [10]
if err != nil {
return nil, err
}
responses = append(responses, resp)
retry, err := r.retryRequest(ctx, responses, lastHost) // [11]
// [...]
if retry {
// [...]
return r.doWithRetriesInner(ctx, responses, lastHost) // call itself again if retry == true
}
}
If the status code of the HTTP response is 401 [12], the authorizer registers a new auth handler [13] based on the authenication information extracted from response header.
// vendor/github.com/containerd/containerd/v2/core/remotes/docker/resolver.go
func (r *request) retryRequest(ctx context.Context, responses []*http.Response, lastHost bool) (bool, error) {
// [...]
last := responses[len(responses)-1]
switch last.StatusCode {
case http.StatusUnauthorized: // [12]
// [...]
if r.host.Authorizer != nil {
if err := r.host.Authorizer.AddResponses(ctx, responses); err == nil { // <--------
true, nil // true -> retry
}
// [...]
}
// [...]
}
}
// vendor/github.com/containerd/containerd/v2/core/remotes/docker/authorizer.go
func (a *dockerAuthorizer) AddResponses(ctx context.Context, responses []*http.Response) error {
for _, c := range auth.ParseAuthHeader(last.Header) {
if c.Scheme == auth.BearerAuth {
/**
* the response header is like:
* www-authenticate: Bearer realm="https://auth.docker.io/token",service="registry.docker.io",scope="repository:library/ubuntu:pull"
* so next time authorizer will first do authorization and then send the request
*/
// [...]
a.handlers[host] = newAuthHandler(a.client, a.header, c.Scheme, common) // [13]
return nil
}
// [...]
}
}
Since retry is equal to true, r.do(ctx) is called again. This time the auth handler is assigned, so it has to authorize against the realm host, auth.docker.io in this case, to get the auth token. Here, the Bearer authentication is used [14].
// vendor/github.com/containerd/containerd/v2/core/remotes/docker/resolver.go
func (r *request) do(ctx context.Context) (*http.Response, error) {
// [...]
if err := r.authorize(ctx, req); err != nil { // <--------
// [...]
}
// [...]
resp, err := client.Do(req) // actually send the request
// [...]
}
func (r *request) authorize(ctx context.Context, req *http.Request) error {
if r.host.Authorizer != nil {
if err := r.host.Authorizer.Authorize(ctx, req); err != nil { // <--------
// [...]
}
}
return nil
}
// vendor/github.com/containerd/containerd/v2/core/remotes/docker/authorizer.go
func (a *dockerAuthorizer) Authorize(ctx context.Context, req *http.Request) error {
// [...]
ah := a.getAuthHandler(req.URL.Host)
// [...]
auth, refreshToken, err := ah.authorize(ctx) // <--------
// [...]
}
func (ah *authHandler) authorize(ctx context.Context) (string, string, error) {
switch ah.scheme {
// [...]
case auth.BearerAuth:
return ah.doBearerAuth(ctx) // [14]
// [...]
}
}
req.doWithRetries() returns the HTTP response data to its caller, Resolve(), and the "Docker-Content-Digest" header is extracted [15] from the headers. In the end, the Resolve() wraps the response data into a descripbtor [16] and returns.
// vendor/github.com/containerd/containerd/v2/core/remotes/docker/resolver.go
func (r *dockerResolver) Resolve(ctx context.Context, ref string) (string, ocispec.Descriptor, error) {
// [...]
for _, u := range paths {
for i, host := range hosts {
// [...]
resp, err := req.doWithRetries(ctx, i == len(hosts)-1)
if dgst == "" {
dgstHeader := digest.Digest(resp.Header.Get("Docker-Content-Digest")) // [15]
dgst = dgstHeader
}
// [...]
desc := ocispec.Descriptor{ // [16], for ubuntu:24.04
Digest: dgst, // "sha256:c4a8d5503dfb2a3eb8ab5f807da5bc69a85730fb49b5cfca2330194ebcc41c7b"
MediaType: contentType, // "application/vnd.oci.image.index.v1+json"
Size: size, // 6688
}
return ref, desc, nil
}
}
}
Now we know how dockerd handles the response if the registry server returns 401, and what the first request looks like when you are pulling a image.
The flow is as follows:
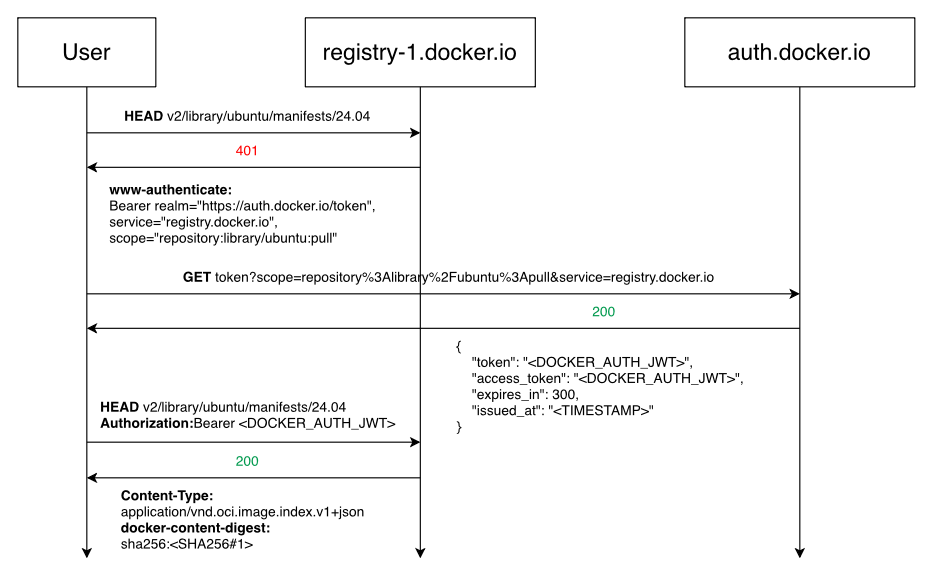
1.3. GET Image Index
Once we get the first descriptor, we can start to fetch the raw data from the registry server.
The fetching pipeline is built in two layers: handlers and decorators. A handler works as a hook function [1], and a handler may have several decorators. For example childrenHandler has at most five decorators [2], all chained together into the final handler.
When images.Dispatch() [3] is called, the handlers are invoked following the sequence of registration.
// vendor/github.com/containerd/containerd/v2/client/pull.go
func (c *Client) fetch(ctx context.Context, rCtx *RemoteContext, ref string, limit int) (images.Image, error) {
// [...]
name, desc, err := rCtx.Resolver.Resolve(ctx, ref)
// returned desc = { Digest: sha256:c4a8...1c7b, MediaType: <type>, Size: N }
// [...]
// ============ fetching pipeline ============
store := c.ContentStore()
// [...]
fetcher, err := rCtx.Resolver.Fetcher(ctx, name)
// [...]
childrenHandler := images.ChildrenHandler(store)
// [...]
// [2]
childrenHandler = images.SetReferrers(rCtx.ReferrersProvider, childrenHandler)
childrenHandler = images.SetChildrenMappedLabels(store, childrenHandler, rCtx.ChildLabelMap)
childrenHandler = remotes.FilterManifestByPlatformHandler(childrenHandler, rCtx.PlatformMatcher)
childrenHandler = images.FilterPlatforms(childrenHandler, rCtx.PlatformMatcher)
childrenHandler = images.LimitManifests(childrenHandler, rCtx.PlatformMatcher, limit)
// [...]
convertibleHandler := images.HandlerFunc(
func(_ context.Context, desc ocispec.Descriptor) ([]ocispec.Descriptor, error) {
if desc.MediaType == docker.LegacyConfigMediaType {
isConvertible = true
}
return []ocispec.Descriptor{}, nil
},
)
// [...]
appendDistSrcLabelHandler, err := docker.AppendDistributionSourceLabel(store, ref)
// [...]
handlers := append( // [1]
rCtx.BaseHandlers,
remotes.FetchHandler(store, fetcher),
convertibleHandler,
childrenHandler,
appendDistSrcLabelHandler,
)
handler = images.Handlers(handlers...)
// [...]
if err := images.Dispatch(ctx, handler, limiter, desc); err != nil { // [3]
// [...]
}
// [...]
}
Dispatch() calls handler.Handle() to walk through the chained handlers and invoke them [4]. If the composed handler returns more descriptors, Dispatch() is called recursively [5].
// vendor/github.com/containerd/containerd/v2/core/images/handlers.go
func Dispatch(ctx context.Context, handler Handler, limiter *semaphore.Weighted, descs ...ocispec.Descriptor) error {
for _, desc := range descs {
eg.Go(func() error {
desc := desc
// [...]
// .Handle() is defined in vendor/github.com/containerd/containerd/v2/core/images/handlers.go
children, err := handler.Handle(ctx2, desc) // [4]
// [...]
if len(children) > 0 {
return Dispatch(ctx2, handler, limiter, children...) // [5]
}
})
}
}
The flow is like:
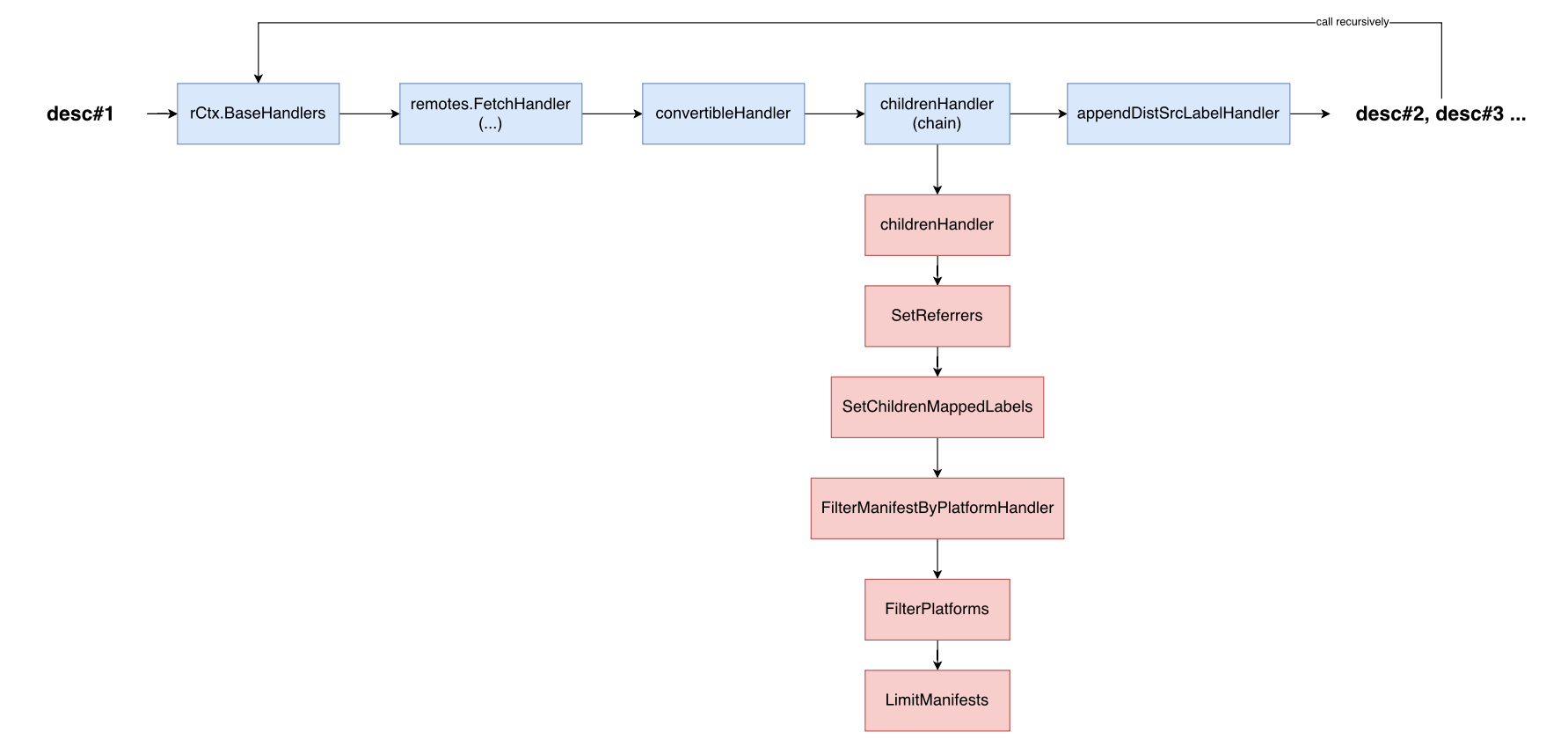
We first analyze FetchHandler(), the handler that fetches data from the remote. The call flow ends up at Fetch() in fetcher.go [6].
// vendor/github.com/containerd/containerd/v2/core/remotes/handlers.go
func FetchHandler(ingester content.Ingester, fetcher Fetcher) images.HandlerFunc {
return func(ctx context.Context, desc ocispec.Descriptor) ([]ocispec.Descriptor, error) {
// [...]
err := Fetch(ctx, ingester, fetcher, desc) // <--------
// [...]
}
}
func Fetch(ctx context.Context, ingester content.Ingester, fetcher Fetcher, desc ocispec.Descriptor) error {
// [...]
rc, err := fetcher.Fetch(ctx, desc) // [6]
// [...]
return content.Copy(ctx, cw, rc, desc.Size, desc.Digest)
}
This function calls r.open() to fetch image data from three sources: external URLs [7], the "manifests" endpoint [8] if the type is index or manifest, and the "blob" endpoint [9] for the rest of the types.
// vendor/github.com/containerd/containerd/v2/core/remotes/docker/fetcher.go
func (r dockerFetcher) Fetch(ctx context.Context, desc ocispec.Descriptor) (io.ReadCloser, error) {
// [...]
return newHTTPReadSeeker(desc.Size, func(offset int64) (io.ReadCloser, error) {
// [7] firstly try fetch via external urls
for _, us := range desc.URLs {
// [...]
rc, _, err := r.open(ctx, req, desc.MediaType, offset, false)
}
// [8] Try manifests endpoints for manifests types
if images.IsManifestType(desc.MediaType) || images.IsIndexType(desc.MediaType) {
for i, host := range r.hosts {
req := r.request(host, http.MethodGet, "manifests", desc.Digest.String())
//[...]
//[...]
rc, _, err := r.open(ctx, req, desc.MediaType, offset, i == len(r.hosts)-1)
}
return nil, firstErr
}
//[9] Finally use blobs endpoints
for i, host := range r.hosts {
req := r.request(host, http.MethodGet, "blobs", desc.Digest.String())
// [...]
rc, _, err := r.open(ctx, req, desc.MediaType, offset, i == len(r.hosts)-1)
// [...]
}
// [...]
})
}
open() calls req.doWithRetries(), which is the function that authenticates and sends the request.
func (r dockerFetcher) open(ctx context.Context, req *request, mediatype string, offset int64, lastHost bool) (_ io.ReadCloser, _ int64, retErr error) {
// [...]
resp, err := req.doWithRetries(ctx, lastHost, withErrorCheck, withOffsetCheck(offset, parallelism))
// [...]
}
If you’re curious about what the response data looks like, you can find out in the next section.
1.4. Download Manifest & Blob
The next handler is ChildrenHandler(), and its job is to parse the returned JSON data.
If the descriptor type is a manifest, it expects the JSON to be unmarshalled into ocispec.Manifest structure [1], and turns the Config and Layers fields to descriptors [2]; if the type is an index, the data is unmarshalled to ocispec.Index structure [3], and the Manifests field is extracted and returned as descriptors [4].
// vendor/github.com/containerd/containerd/v2/core/images/handlers.go
func ChildrenHandler(provider content.Provider) HandlerFunc {
return func(ctx context.Context, desc ocispec.Descriptor) ([]ocispec.Descriptor, error) {
return Children(ctx, provider, desc) // <--------
}
}
// vendor/github.com/containerd/containerd/v2/core/images/image.go
func Children(ctx context.Context, provider content.Provider, desc ocispec.Descriptor) ([]ocispec.Descriptor, error) {
if IsManifestType(desc.MediaType) {
// [...]
p, err := content.ReadBlob(ctx, provider, desc)
var manifest ocispec.Manifest // [1]
if err := json.Unmarshal(p, &manifest); err != nil {
// [...]
}
// [...]
return append([]ocispec.Descriptor{manifest.Config}, manifest.Layers...), nil // [2]
} else if IsIndexType(desc.MediaType) {
// [...]
p, err := content.ReadBlob(ctx, provider, desc)
var index ocispec.Index
if err := json.Unmarshal(p, &index); err != nil { // [3]
return nil, err
}
// [...]
return append([]ocispec.Descriptor{}, index.Manifests...), nil // [4]
}
}
These structures with ocispec prefix are defined in the opencontainers repository, and they are based on OCI (Open Container Initiative), a set of open standards that define how containers and container images should be formatted and run so that tools from different vendors can interoperate.
// vendor/github.com/opencontainers/image-spec/specs-go/v1/index.go
type Index struct {
specs.Versioned
MediaType string `json:"mediaType,omitempty"`
ArtifactType string `json:"artifactType,omitempty"`
Manifests []Descriptor `json:"manifests"`
Subject *Descriptor `json:"subject,omitempty"`
Annotations map[string]string `json:"annotations,omitempty"`
}
// vendor/github.com/opencontainers/image-spec/specs-go/v1/manifest.go
type Manifest struct {
specs.Versioned
MediaType string `json:"mediaType,omitempty"`
ArtifactType string `json:"artifactType,omitempty"`
Config Descriptor `json:"config"`
Layers []Descriptor `json:"layers"`
Subject *Descriptor `json:"subject,omitempty"`
Annotations map[string]string `json:"annotations,omitempty"`
}
Other handlers or decorations are not so much complicated and important — for example, they filter out useless descriptors, only keep the image matching the host architecture — so we skip them here.
One thing is worth to mentioning: you may notice there are two entries for the amd64 image in the index JSON. Actually, only the first one is the real image data (cdb…eff). The second one is the attestation (01a…169) of the first entry, which is signed metadata that makes a verifiable claim about an artifact.
{
"manifests": [
{
"annotations": {
"com.docker.official-images.bashbrew.arch": "amd64",
"org.opencontainers.image.base.name": "scratch",
"org.opencontainers.image.created": "2026-04-10T00:00:00Z",
"org.opencontainers.image.revision": "a17a2429ff85ab773e86c558a75ae62053ef9936",
"org.opencontainers.image.source": "https://git.launchpad.net/cloud-images/+oci/ubuntu-base",
"org.opencontainers.image.url": "https://hub.docker.com/_/ubuntu",
"org.opencontainers.image.version": "24.04"
},
"digest": "sha256:cdb5fd928fced577cfecf12c8966e830fcdf42ee481fb0b91904eeddc2fe5eff",
"mediaType": "application/vnd.oci.image.manifest.v1+json",
"platform": {
"architecture": "amd64",
"os": "linux"
},
"size": 424
},
{
"annotations": {
"com.docker.official-images.bashbrew.arch": "amd64",
"vnd.docker.reference.digest": "sha256:cdb5fd928fced577cfecf12c8966e830fcdf42ee481fb0b91904eeddc2fe5eff",
"vnd.docker.reference.type": "attestation-manifest"
},
"digest": "sha256:01a14a568a5c77390e74eefc7a2106206f4605338cb7e86e8bf06a18452b5169",
"mediaType": "application/vnd.oci.image.manifest.v1+json",
"platform": {
"architecture": "unknown",
"os": "unknown"
},
"size": 562
}
...
]
}
The attestation blob is a pretty large JSON file, and I have no idea about how it’s generated and how to use it 😆. I’ll just leave part of the content below.
{"_type":"https://in-toto.io/Statement/v0.1","predicateType":"https://spdx.dev/Document","subject":[],"predicate":{"spdxVersion":"SPDX-2.3","dataLicense":"CC0-1.0","SPDXID":"SPDXRef-DOCUMENT","name":"sbom","documentNamespace":"https://docker.com/docker-scout/fs/sbom-6b8f300a-23d8-42b3-9f97-0882a7efe944","creationInfo":{"creators":["Organization: Docker, Inc","Tool: docker-scout-1.18.1","Tool: buildkit-0.16.0-tianon"],"created":"2026-04-15T20:02:39Z"},"packages":[{"name":"sbom","SPDXID":"SPDXRef-DocumentRoot","supplier":"NOASSERTION","downloadLocation":"NOASSERTION","filesAnalyzed":false,"licenseConcluded":"NOASSERTION","licenseDeclared":"NOASSERTION","primaryPackagePurpose":"FILE"},{"name":"acl","SPDXID":"SPDXRef-Package-45b9051d819bf7a6bd6a86b0eba5bc45","versionInfo":"2.3.2-1build1.1","supplier":"Person: Ubuntu Developers \\u003cubuntu-devel-discuss@lists.ubuntu.com\\u003e","originator":"Person: Ubuntu Developers \\u003cubuntu-devel-discuss@lists.ubuntu.com\\u003e","downloadLocation":"NOASSERTION","filesAnalyzed":true,"licenseConcluded":"NOASSERTION","licenseDeclared":"GPL-2.0-only OR GPL-2.0-or-later OR LGPL-2.0-or-later OR LGPL-2.1-only","description":"access control list - shared library\n This package contains the shared library containing the POSIX 1003.1e\n draft standard 17 functions for manipulating access control lists.","externalRefs":[{"referenceCategory":"PACKAGE-MANAGER","referenceType":"purl","referenceLocator":"pkg:deb/ubuntu/acl@2.3.2-1build1.1?os_distro=noble\u0026os_name=ubuntu\u0026os_version=24.04"}]} ...] ...} ...}
1.5. Save The File
Now we know the download flow, but when is the data saved into the filesystem?
After fetching the data, content.Copy() is called [1] with the writer cw, the data size desc.Size, and the hash desc.Digest.
// vendor/github.com/containerd/containerd/v2/core/remotes/handlers.go
func Fetch(ctx context.Context, ingester content.Ingester, fetcher Fetcher, desc ocispec.Descriptor) error {
// [...]
cw, err := content.OpenWriter(ctx, ingester, content.WithRef(MakeRefKey(ctx, desc)), content.WithDescriptor(desc))
// [...]
rc, err := fetcher.Fetch(ctx, desc)
// [...]
return content.Copy(ctx, cw, rc, desc.Size, desc.Digest) // [1]
}
The writer object is allocated by OpenWriter(), which evetually returns a remoteWriter object [2] with a client backed by a TTRPC stream to containerd.
// vendor/github.com/containerd/containerd/v2/core/content/helpers.go
func OpenWriter(ctx context.Context, cs Ingester, opts ...WriterOpt) (Writer, error) {
var (
cw Writer
err error
retry = 16
)
for {
cw, err = cs.Writer(ctx, opts...) // <--------
// [...]
}
// [...]
}
// vendor/github.com/containerd/containerd/v2/core/content/proxy/content_store.go
func (pcs *proxyContentStore) Writer(ctx context.Context, opts ...content.WriterOpt) (content.Writer, error) {
// [...]
wrclient, offset, err := pcs.negotiate(ctx, wOpts.Ref, wOpts.Desc.Size, wOpts.Desc.Digest)
// [...]
return &remoteWriter{ // [2]
ref: wOpts.Ref,
client: wrclient,
offset: offset,
}, nil
}
Copy() writes file by calling copyWithBuffer() and saves file by calling cw.Commit(). Both two functions send the request with data content to containerd. Take copyWithBuffer() as an example: it sends action WriteAction_WRITE with data attached [3] in the end.
// vendor/github.com/containerd/containerd/v2/core/content/helpers.go
func Copy(ctx context.Context, cw Writer, or io.Reader, size int64, expected digest.Digest, opts ...Opt) error {
// [...]
copied, err := copyWithBuffer(cw, r) // <--------
// [...]
if err := cw.Commit(ctx, size, expected, opts...); err != nil {
// [...]
}
}
func copyWithBuffer(dst io.Writer, src io.Reader) (written int64, err error) {
// [...]
for {
nr, er := io.ReadAtLeast(src, buf, len(buf)) // read from src
if nr > 0 {
nw, ew := dst.Write(buf[0:nr]) // <-------- write to dst
// [...]
}
}
}
// vendor/github.com/containerd/containerd/v2/core/content/proxy/content_writer.go
func (rw *remoteWriter) Write(p []byte) (n int, err error) {
const maxBufferSize = defaults.DefaultMaxSendMsgSize >> 1
for data := range slices.Chunk(p, maxBufferSize) {
offset := rw.offset
resp, err := rw.send(&contentapi.WriteContentRequest{
Action: contentapi.WriteAction_WRITE, // [3]
Offset: offset,
Data: data,
})
// [...]
}
return n, nil
}
On the containerd side, the content server’s Write() handles both WRITE and COMMIT actions. If the request is a COMMIT action, wr.Commit() is called [4] to save data into the filesystem.
// vendor/github.com/containerd/containerd/v2/plugins/services/content/contentserver/contentserver.go
func (s *service) Register(server *grpc.Server) error {
api.RegisterContentServer(server, s) // <--------
return nil
}
// vendor/github.com/containerd/containerd/api/services/content/v1/content_grpc.pb.go
func RegisterContentServer(s grpc.ServiceRegistrar, srv ContentServer) {
s.RegisterService(&Content_ServiceDesc, srv) // <--------
}
var Content_ServiceDesc = grpc.ServiceDesc{
// [...]
Streams: []grpc.StreamDesc{
// [...]
{
StreamName: "Write",
Handler: _Content_Write_Handler, // <--------
ServerStreams: true,
ClientStreams: true,
},
},
// [...]
}
func _Content_Write_Handler(srv interface{}, stream grpc.ServerStream) error {
return srv.(ContentServer).Write(&contentWriteServer{stream}) // <--------
}
// vendor/github.com/containerd/containerd/v2/plugins/services/content/contentserver/contentserver.go
func (s *service) Write(session api.Content_WriteServer) (err error) {
// [...]
wr, err := s.store.Writer(ctx,
content.WithRef(ref),
content.WithDescriptor(ocispec.Descriptor{Size: total, Digest: expected}))
// [...]
for {
msg.Action = req.Action
switch req.Action {
// [...]
case api.WriteAction_WRITE, api.WriteAction_COMMIT:
// [...]
if req.Action == api.WriteAction_COMMIT {
// [...]
if err := wr.Commit(ctx, total, expected, opts...); err != nil { // [4]
// [...]
}
}
// [...]
}
}
}
The data being written is kept in a temporary file in the "ingest/" directory, and when receiving a COMMIT action, Commit() renames it to the destination path [5], which is inside the "blobs/" directory.
// vendor/github.com/containerd/containerd/v2/plugins/content/local/writer.go
func (w *writer) Commit(ctx context.Context, size int64, expected digest.Digest, opts ...content.Opt) error {
// [...]
dgst := w.digester.Digest()
// [...]
var (
ingest = filepath.Join(w.path, "data") // ingest/<hash(ref)>/data
target, _ = w.s.blobPath(dgst) // blobs/sha256/<dgst>
)
// [...]
if err := os.Rename(ingest, target); err != nil { // [5]
// [...]
}
// [...]
}
The writer object (w) decides the root directory in which to save the file, and it is initialized in writer() [6].
// vendor/github.com/containerd/containerd/v2/plugins/content/local/store.go
func (s *store) Writer(ctx context.Context, opts ...content.WriterOpt) (content.Writer, error) {
// [...]
w, err := s.writer(ctx, wOpts.Ref, wOpts.Desc.Size, wOpts.Desc.Digest) // <--------
// [...]
return w, nil
}
func (s *store) writer(ctx context.Context, ref string, total int64, expected digest.Digest) (content.Writer, error) {
// [...]
path, refp, data := s.ingestPaths(ref)
// [...]
return &writer{ // [6]
// [...]
ref: ref,
path: path,
// [...]
}, nil
}
To get the full path, we have to look at the containerd source code.
containerd decouples functionalities into different plugin objects. A plugin’s init() function defines its ID and initialization callback. Here, the ID of the content plugin is "content" [7], and its callback function internally sets the root directory property as its store root [8].
// plugins/content/local/plugin/plugin.go
func init() {
registry.Register(&plugin.Registration{
Type: plugins.ContentPlugin,
ID: "content", // [7]
InitFn: func(ic *plugin.InitContext) (any, error) {
root := ic.Properties[plugins.PropertyRootDir]
ic.Meta.Exports["root"] = root
return local.NewStore(root) // <--------
},
})
}
// vendor/github.com/containerd/containerd/v2/plugins/content/local/store.go
func NewStore(root string) (content.Store, error) {
return NewLabeledStore(root, nil) // <--------
}
func NewLabeledStore(root string, ls LabelStore) (content.Store, error) {
// [...]
s := &store{
root: root, // [8]
// [...]
}
// [...]
}
So where is plugins.PropertyRootDir defined? When starting the containerd daemon, New() iterates through the loaded plugins [9]. It further creates a context for each plugin object and sets plugins.PropertyRootDir [10]. By default, config.Root is set to /var/lib/containerd, and id is from the URL() function.
// cmd/containerd/server/server.go
func New(ctx context.Context, config *srvconfig.Config) (*Server, error) {
// [...]
loaded, err := LoadPlugins(ctx, config)
// [...]
for _, p := range loaded { // [9]
id := p.URI()
// [...]
initContext := plugin.NewContext(
ctx,
initialized,
map[string]string{
plugins.PropertyRootDir: filepath.Join(config.Root, id), // [10]
// [...]
},
)
// [...]
}
}
// defaults/defaults_unix.go
const (
// [...]
DefaultRootDir = "/var/lib/containerd"
// [...]
)
URL() concatenates the plugin’s type string, which is "io.containerd.content.v1" here, and its ID, which is "content" here. So finally, we know those image files are stored inside the directory /var/lib/containerd/io.containerd.content.v1.content.
// vendor/github.com/containerd/plugin/plugin.go
func (r *Registration) URI() string {
// r.Type.String() == "io.containerd.content.v1"
// r.ID
return r.Type.String() + "." + r.ID
}
// plugins/types.go
const (
// [...]
ContentPlugin plugin.Type = "io.containerd.content.v1"
// [...]
)
List the directory and you’ll find the image blobs.
root@aaa:~# ls -al /var/lib/containerd/io.containerd.content.v1.content/
total 16
drwxr-xr-x 4 root root 4096 May 27 11:47 .
drwx------ 13 root root 4096 Apr 9 14:51 ..
drwxr-xr-x 3 root root 4096 Apr 9 14:51 blobs
drwxr-xr-x 2 root root 4096 May 28 10:49 ingest
2. Unpack an Image
2.1. dockerd side
The unpacker is used as a wrapper of chained image handlers [1], so it is triggered before handles run. When triggered, the unpacker.Unpack() is called [2].
// vendor/github.com/containerd/containerd/v2/client/pull.go
func (c *Client) Pull(ctx context.Context, ref string, opts ...RemoteOpt) (_ Image, retErr error) {
if pullCtx.Unpack {
// [...]
unpacker, err = unpack.NewUnpacker(ctx, c.ContentStore(), uopts...)
// [...]
pullCtx.HandlerWrapper = func(h images.Handler) images.Handler {
// [...]
return unpacker.Unpack(h) // [2]
}
}
// [...]
img, err := c.fetch(ctx, pullCtx, ref, 1)
// [...]
}
func (c *Client) fetch(ctx context.Context, rCtx *RemoteContext, ref string, limit int) (images.Image, error) {
// [...]
handler = images.Handlers(handlers...)
// [...]
if rCtx.HandlerWrapper != nil {
handler = rCtx.HandlerWrapper(handler) // [1]
}
if err := images.Dispatch(ctx, handler, limiter, desc); err != nil {
// [...]
}
// [...]
}
After the handlers finish, Unpack() gets the sub-descriptors [3]. If the descriptor is a manifest [4], it splits sub-descriptors to two types: layer and non-layer. Later, the layer list is assigned to the non-layer sub-descriptor [5].
For a config descriptor, the layers are retrieved and unpacked [6].
One thing that should be mentioned is that the returned children of a manifest descriptor only contain non-layer sub-descriptors [7], so these layers are not downloaded until u.unpack() is called.
// vendor/github.com/containerd/containerd/v2/core/unpack/unpacker.go
func (u *Unpacker) Unpack(h images.Handler) images.Handler {
// [...]
return images.HandlerFunc(func(ctx context.Context, desc ocispec.Descriptor) ([]ocispec.Descriptor, error) {
// [...]
children, err := h.Handle(ctx, desc) // [3]
// [...]
if images.IsManifestType(desc.MediaType) { // [4]
for i, child := range children {
// [...]
if images.IsLayerType(child.MediaType) || layerTypes[child.MediaType] {
manifestLayers = append(manifestLayers, child)
} else {
nonLayers = append(nonLayers, child)
}
}
for _, nl := range nonLayers {
layers[nl.Digest] = manifestLayers // [5]
}
children = nonLayers // [7]
} else if images.IsConfigType(desc.MediaType) || configTypes[desc.MediaType] {
// "application/vnd.docker.container.image.v1+json" or "application/vnd.oci.image.config.v1+json"
// [...]
l := layers[desc.Digest]
// [...]
if len(l) > 0 {
u.eg.Go(func() error {
return u.unpack(h, desc, l) // [6]
})
}
}
})
}
We take one of the manifest data from pulling a Ubuntu:24.04 image as an example. When getting the JSON response below, unpack() gets two sub-descriptors: a config and a layer, so children will be like [config, layer1, ... (if any)]. It first assigns layers[0b1...b27] = [b40...081 (layer sub-descriptor)] [5], and the next round the config descriptor is processed and layers[0b1...b27] is unpacked [6].
{
"schemaVersion": 2,
"mediaType": "application/vnd.oci.image.manifest.v1+json",
"config": {
"mediaType": "application/vnd.oci.image.config.v1+json",
"size": 2051,
"digest": "sha256:0b1ebe5dd42682bb8eda97ecf10a09f70f18d2d4af35f82b9271badac5dbeb27"
},
"layers": [
{
"mediaType": "application/vnd.oci.image.layer.v1.tar+gzip",
"size": 29732978,
"digest": "sha256:b40150c1c2717d324cdb17278c8efdfa4dfcd2ffe083e976f0bcedf31115f081"
}
]
}
unpack() first unmarshals the config descriptor into i [8] and later calls u.fetch() [9] to download the layer data. After it’s downloaded, a.Apply() is called to the unpack compressed layer [10].
// vendor/github.com/containerd/containerd/v2/core/unpack/unpacker.go
func (u *Unpacker) unpack(
h images.Handler,
config ocispec.Descriptor,
layers []ocispec.Descriptor,
) error {
// [...]
p, err := content.ReadBlob(ctx, u.content, config)
// [...]
var i unpackConfig
if err := json.Unmarshal(p, &i); err != nil { // [8]
// [...]
}
// [...]
topHalf := func(i int, desc ocispec.Descriptor, span *tracing.Span, startAt time.Time) (<-chan *unpackStatus, error) {
key = fmt.Sprintf(snapshots.UnpackKeyFormat, uniquePart(), chainID)
mounts, err = sn.Prepare(ctx, key, parent, opts...) // call s.createSnapshot() -> mounts := s.buildMounts()
// [...]
go func(i int) {
err := u.fetch(ctx, h, layers[i:], fetchC) // [9]
}(i)
// [...]
diff, err := a.Apply(ctx, desc, mounts, unpack.ApplyOpts...) // [10]
// [...]
}
// [...]
for i, desc := range layers {
// [...]
statusCh, err := topHalf(i, desc, layerSpan, unpackLayerStart)
// [...]
}
// [...]
}
The config is represented as the unpackConfig structure.
// vendor/github.com/containerd/containerd/v2/core/unpack/unpacker.go
type unpackConfig struct {
ocispec.Platform
RootFS ocispec.RootFS `json:"rootfs"`
}
The config JSON blob looks like:
{
"architecture": "amd64",
"config": {
"Hostname": "",
"Domainname": "",
"User": "",
"AttachStdin": false,
"AttachStdout": false,
"AttachStderr": false,
"Tty": false,
"OpenStdin": false,
"StdinOnce": false,
"Env": [
"PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin"
],
"Cmd": [
"/bin/bash"
],
"Image": "sha256:337382923f7584f260a9a67e7625aaf9d42c24784c6e92731c29fa3912ae5c47",
"Volumes": null,
"WorkingDir": "",
"Entrypoint": null,
"OnBuild": null,
"Labels": {
"org.opencontainers.image.version": "24.04"
}
},
"container": "824f27add47a9b8b83f4296fcbd9772627dd3ab13c39c889306a30cd4e2e1fc1",
"container_config": {
"Hostname": "824f27add47a",
"Domainname": "",
"User": "",
"AttachStdin": false,
"AttachStdout": false,
"AttachStderr": false,
"Tty": false,
"OpenStdin": false,
"StdinOnce": false,
"Env": [
"PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin"
],
"Cmd": [
"/bin/sh",
"-c",
"#(nop) ",
"CMD [\"/bin/bash\"]"
],
"Image": "sha256:337382923f7584f260a9a67e7625aaf9d42c24784c6e92731c29fa3912ae5c47",
"Volumes": null,
"WorkingDir": "",
"Entrypoint": null,
"OnBuild": null,
"Labels": {
"org.opencontainers.image.version": "24.04"
}
},
"created": "2026-04-10T06:49:18.133477895Z",
"docker_version": "26.1.3",
"history": [
{
"created": "2026-04-10T06:49:15.45210454Z",
"created_by": "/bin/sh -c #(nop) ARG RELEASE",
"empty_layer": true
},
{
"created": "2026-04-10T06:49:15.493474875Z",
"created_by": "/bin/sh -c #(nop) ARG LAUNCHPAD_BUILD_ARCH",
"empty_layer": true
},
{
"created": "2026-04-10T06:49:15.521658623Z",
"created_by": "/bin/sh -c #(nop) LABEL org.opencontainers.image.version=24.04",
"empty_layer": true
},
{
"created": "2026-04-10T06:49:17.706887224Z",
"created_by": "/bin/sh -c #(nop) ADD file:8ce1caf246e7c778bca84c516d02fd4e83766bb2c530a0fffa8a351b560a2728 in / "
},
{
"created": "2026-04-10T06:49:18.133477895Z",
"created_by": "/bin/sh -c #(nop) CMD [\"/bin/bash\"]",
"empty_layer": true
}
],
"os": "linux",
"rootfs": {
"type": "layers",
"diff_ids": [
"sha256:538812a4b9bd45adaac2b5e5b967daa6999aa44eb110aa32ae7c69702b906475"
]
}
}
fetch() calls h.Handle(ctx2, desc) with the layer’s descriptor [11], which calls chained handler, including the download handler — .FetchHandler().
// vendor/github.com/containerd/containerd/v2/core/unpack/unpacker.go
func (u *Unpacker) fetch(ctx context.Context, h images.Handler, layers []ocispec.Descriptor, done []chan struct{}) error {
eg.Go(func() error {
for i, desc := range layers {
// [...]
_, err = h.Handle(ctx2, desc) // [11]
// [...]
}
})
}
Apply() sends an apply request to containerd [12] with the layer descriptor.
// vendor/github.com/containerd/containerd/v2/core/diff/proxy/differ.go
func (r *diffRemote) Apply(ctx context.Context, desc ocispec.Descriptor, mounts []mount.Mount, opts ...diff.ApplyOpt) (ocispec.Descriptor, error) {
// [...]
req := &diffapi.ApplyRequest{
Diff: oci.DescriptorToProto(desc),
Mounts: mount.ToProto(mounts),
Payloads: payloads,
SyncFs: config.SyncFs,
}
// [...]
resp, err := r.client.Apply(ctx, req) // <--------
// [...]
}
// vendor/github.com/containerd/containerd/api/services/diff/v1/diff_grpc.pb.go
func (c *diffClient) Apply(ctx context.Context, in *ApplyRequest, opts ...grpc.CallOption) (*ApplyResponse, error) {
out := new(ApplyResponse)
err := c.cc.Invoke(ctx, "/containerd.services.diff.v1.Diff/Apply", in, out, opts...) // [12]
// [...]
}
By now we know that the unpack operations are performed by containerd, not dockerd.
2.2. Create A Snapshot
Before delving into the unpacking implementation of containerd, let’s take a look at the snapshot mechanism.
A snapshot is a saved state of a filesystem layer, and it also defines how to mount these layers.
In unpack(), sn.Prepare() is called to create a snapshot [1].
// vendor/github.com/containerd/containerd/v2/core/unpack/unpacker.go
func (u *Unpacker) unpack(
h images.Handler,
config ocispec.Descriptor,
layers []ocispec.Descriptor,
) error {
// [...]
topHalf := func(i int, desc ocispec.Descriptor, span *tracing.Span, startAt time.Time) (<-chan *unpackStatus, error) {
// [...]
var (
key string
mounts []mount.Mount
opts = append(unpack.SnapshotOpts, snapshots.WithLabels(snapshotLabels))
)
// [...]
key = fmt.Sprintf(snapshots.UnpackKeyFormat, uniquePart(), chainID)
mounts, err = sn.Prepare(ctx, key, parent, opts...) // [1]
// [...]
}
}
Snapshot preparation ends up sending a PrepareSnapshotRequest [2] request to containerd.
// vendor/github.com/containerd/containerd/v2/core/snapshots/proxy/proxy.go
func (p *proxySnapshotter) Prepare(ctx context.Context, key, parent string, opts ...snapshots.Opt) ([]mount.Mount, error) {
// [...]
resp, err := p.client.Prepare(ctx, &snapshotsapi.PrepareSnapshotRequest{ // [2]
Snapshotter: p.snapshotterName, // by default "overlayfs"
Key: key,
Parent: parent,
Labels: local.Labels,
})
// [...]
return mount.FromProto(resp.Mounts), nil
}
containerd’s handler internally creates snapshot-related files and directories [3], and then calls o.mounts(s, info) to generate overlayfs mounting options [4].
// plugins/services/snapshots/service.go
// from _Snapshots_Prepare_Handler()
func (s *service) Prepare(ctx context.Context, pr *snapshotsapi.PrepareSnapshotRequest) (*snapshotsapi.PrepareSnapshotResponse, error) {
// [...]
sn, err := s.getSnapshotter(pr.Snapshotter) // "overlayfs"
// [...]
mounts, err := sn.Prepare(ctx, pr.Key, pr.Parent, opts...) // <--------
// [...]
return &snapshotsapi.PrepareSnapshotResponse{
Mounts: mount.ToProto(mounts),
}, nil
}
// core/metadata/snapshot.go
func (s *snapshotter) Prepare(ctx context.Context, key, parent string, opts ...snapshots.Opt) ([]mount.Mount, error) {
mounts, err := s.createSnapshot(ctx, key, parent, false, opts) // <--------
// [...]
return mounts, nil
}
func (s *snapshotter) createSnapshot(ctx context.Context, key, parent string, readonly bool, opts []snapshots.Opt) ([]mount.Mount, error) {
// [...]
m, err = s.Snapshotter.Prepare(ctx, bkey, bparent, bopts...) // <--------
// [...]
}
// plugins/snapshots/overlay/overlay.go
func (o *snapshotter) Prepare(ctx context.Context, key, parent string, opts ...snapshots.Opt) ([]mount.Mount, error) {
return o.createSnapshot(ctx, snapshots.KindActive, key, parent, opts) // <--------
}
// plugins/snapshots/overlay/overlay.go
func (o *snapshotter) createSnapshot(ctx context.Context, kind snapshots.Kind, key, parent string, opts []snapshots.Opt) (_ []mount.Mount, err error) {
// [...]
_, info, _, err = storage.GetInfo(ctx, key)
// [...]
snapshotDir := filepath.Join(o.root, "snapshots")
td, err = o.prepareDirectory(ctx, snapshotDir, kind)
// [...]
path = filepath.Join(snapshotDir, s.ID)
if err = os.Rename(td, path); err != nil { // [3]
// [...]
}
// [...]
return o.mounts(s, info), nil
}
func (o *snapshotter) mounts(s storage.Snapshot, info snapshots.Info) []mount.Mount {
// [...]
return []mount.Mount{ // [4]
{
Type: "overlay", // or "bind" ...
Source: "overlay",
Options: options,
},
}
}
So, before unpacking the layer, sn.Prepare() creates the snapshot directories that will hold the extracted layers.
2.3. containerd Apply Handling
The apply request is sent from dockerd to containerd.
On the containerd side, Apply() is called to handle the request, and it internally iterates through registered processors [1] and wraps them to a chained processor. Later, apply() is called with the wrapped IO stream [2], which triggers the processor callback in the end.
// plugins/services/diff/local.go
func (l *local) Apply(ctx context.Context, er *diffapi.ApplyRequest, _ ...grpc.CallOption) (*diffapi.ApplyResponse, error) {
for _, differ := range l.differs {
// [...]
ocidesc, err = differ.Apply(ctx, desc, mounts, opts...) // <--------
// [...]
}
}
// core/diff/apply/apply.go
func (s *fsApplier) Apply(ctx context.Context, desc ocispec.Descriptor, mounts []mount.Mount, opts ...diff.ApplyOpt) (d ocispec.Descriptor, err error) {
// [...]
var processors []diff.StreamProcessor
for {
if processor, err = diff.GetProcessor(ctx, processor, config.ProcessorPayloads); err != nil { // [1]
// [...]
}
processors = append(processors, processor)
if processor.MediaType() == ocispec.MediaTypeImageLayer {
break
}
}
// [...]
rc := &readCounter{
r: io.TeeReader(processor, digester.Hash()),
}
if err := apply(ctx, mounts, rc, config.SyncFs); err != nil { // [2]
// [...]
}
// [...]
}
How does GetProcessor() decide which decoder to used? It calls all registered handlers until returns success [3]. By default, there is at least one processor: compressedHandler [4].
// core/diff/stream.go
func GetProcessor(ctx context.Context, stream StreamProcessor, payloads map[string]typeurl.Any) (StreamProcessor, error) {
// [...]
for i := len(handlers) - 1; i >= 0; i-- {
processor, ok := handlers[i](ctx, stream.MediaType()) // [3]
if ok {
return processor(ctx, stream, payloads)
}
}
return nil, ErrNoProcessor
}
func init() {
RegisterProcessor(compressedHandler) // [4]
}
func RegisterProcessor(handler Handler) {
handlers = append(handlers, handler)
}
compressedHandler() calls DiffCompression() to verify the compression type [5] and returns a nested function, which finds the matching streaming decoder [6] and returns it.
// core/diff/stream.go
func compressedHandler(ctx context.Context, mediaType string) (StreamProcessorInit, bool) {
compressed, err := images.DiffCompression(ctx, mediaType) // [5]
// [...]
if compressed != "" {
return func(ctx context.Context, stream StreamProcessor, payloads map[string]typeurl.Any) (StreamProcessor, error) {
ds, err := compression.DecompressStream(stream) // [6]
// [...]
return &compressedProcessor{
rc: ds,
}, nil
}, true
}
// [...]
}
Going back to Apply(), the processor is wrapped as an IO stream and then passed to platform-specified apply().
In Linux implementation, apply() in apply_linux.go decides which directory is used to save the extracted files. For overlayfs, the upper directory is used [7, 8], which is the actual path "snapshots/<id>/fs" [9].
// core/diff/apply/apply_linux.go
func apply(ctx context.Context, mounts []mount.Mount, r io.Reader, sync bool) (retErr error) {
switch {
case len(mounts) == 1 && mounts[0].Type == "overlay":
// [...]
path, parents, err := getOverlayPath(mounts[0].Options) // [7]
// [...]
_, err = archive.Apply(ctx, path, r, opts...) // <--------
// [...]
return err
// [...]
}
}
func getOverlayPath(options []string) (upper string /* [8] */, lower []string, err error) {
// [...]
}
// plugins/snapshots/overlay/overlay.go
func (o *snapshotter) upperPath(id string) string {
return filepath.Join(o.root, "snapshots", id, "fs") // [9]
}
Eventually, applyNaive() [9] is called to untar a diff.
// pkg/archive/tar.go
func Apply(ctx context.Context, root string, r io.Reader, opts ...ApplyOpt) (int64, error) {
root = filepath.Clean(root)
// [...]
options.applyFunc = applyNaive
// [...]
return options.applyFunc(ctx, root, r, options) // [9]
}
Here, I want to explain more about two terms: “diff” and “layer”, since they are basically the same thing but in different states.
The raw tar data we download from the remote registry is the layer, kept in the content store. To unpack it, the layer (a compressed tar+gzip file) is decompressed into a diff — a stream of the uncompressed tar. That diff stream is then read and untarred, and the extracted files are saved into an isolated directory (named by snapshot ID) kept in the snapshot plugin.
2.4. untar
applyNaive() is the key function because it covers almost all of the tar extraction logic. It reads an entry from the tar file [1] and gets the file path [2]. It then calls createTarFile() to parse the entry [3].
// pkg/archive/tar.go
func applyNaive(ctx context.Context, root string, r io.Reader, options ApplyOptions) (size int64, err error) {
// [...]
root = filepath.Clean(root)
// [...]
for {
// [...]
hdr, err := tr.Next() // [1]
// [...]
ppath, base := filepath.Split(hdr.Name)
ppath, err = fs.RootPath(root, ppath)
path := filepath.Join(ppath, filepath.Join("/", base)) // [2]
// [...]
srcData := io.Reader(tr)
srcHdr := hdr
if err := createTarFile(ctx, path, root, srcHdr, srcData, options.NoSameOwner); err != nil { // [3]
// [...]
}
// [...]
}
}
createTarFile() is a custom tar handler. It parses the tar entry header to determine the file type, and then performs the corresponding file operation to extract the file. For example, if the entry is a directory [4], the mkdir is called to create the target directory [5].
// pkg/archive/tar.go
func createTarFile(ctx context.Context, path, extractDir string, hdr *tar.Header, reader io.Reader, noSameOwner bool) error {
switch hdr.Typeflag {
case tar.TypeDir: // [4]
// [...]
if fi, err := os.Lstat(path); err != nil || !fi.IsDir() {
if err := mkdir(path, hdrInfo.Mode()); err != nil { // [5]
return err
}
}
// [...]
}
}
3. Attack Surfaces
From the pull flow, the following two operations directly access attack-controllable data:
- Manifest/Index JSON parsing (
fetch()) - Tar extraction (
applyNaive()/createTarFile())
The threat model here is that the attacker compromises the registry server, or the attacker publishes a crafted image manifest or image tar file, which is then downloaded by the victim.
3.1. Parse JSON
Basically, the descriptor is fetched from the remote, so most of desc.XXXX is controllable by the attacker. However, I didn’t find anything useful or vulnerable. Its use is very limited 😢.
3.2. Tar Extraction
When it comes to tar extraction, the tar slip attack is the first technique that comes to my mind, but Docker does a pretty good job of mitigating this kind of problem.
hdr.Name is the path name extracted from the tar entry. It is first split into two parts: directory and filename. For example, "../../../a" becomes "../../../" and "a". Later, the directory part is passed to .RootPath() to resolve the full path.
// pkg/archive/tar.go
func applyNaive(ctx context.Context, root string, r io.Reader, options ApplyOptions) (size int64, err error) {
// [...]
ppath, base := filepath.Split(hdr.Name)
ppath, err = fs.RootPath(root, ppath)
path := filepath.Join(ppath, filepath.Join("/", base))
// [...]
}
So fs.RootPath() has to make sure the resolved ppath is inside the root directory — and how does it do that?
We won’t trace the real code here because it’s unnecessary. Just two points to know for safe path resolution:
- Clamp every
".."at the root: it callsfilepath.Join("/", path)so"/.."is restricted inside the root. - Manaully resolve the softlink: it calls
lstatto get the target path and re-bounds it to the root.
4. Past Vulnerability
When I was looking for past vulnerabilities, there weren’t that many, but CVE-2025-47290 caught my eye — a vulnerability that makes containerd overwrite host filesystem files when pulling an image.
This vulnerability was found by researcher Tõnis Tiigi, and the advisory is here.
In the older version containerd, the cachedRootPath structure is used as a cache for path resolution.
type cachedRootPath struct {
root string
cache map[string]string
}
func newCachedRootPath(root string) *cachedRootPath {
return &cachedRootPath{
root: root,
cache: make(map[string]string),
}
}
func (c *cachedRootPath) get(path string) (string, error) {
if hit, ok := c.cache[path]; ok {
return hit, nil
}
p, err := fs.RootPath(c.root, path)
if err != nil {
return "", err
}
c.cache[path] = p
return p, nil
}
For example, if multiple tar entries are in the same directory, only the first call to rootPath.get() enters the real file resolution fs.RootPath(), and the following entries can just read the path from the cache. Since fs.RootPath(c.root, path) ensures the resolved path is inside the root, it looks like there’s no problem.
ppath, base := filepath.Split(hdr.Name)
ppath, err = rootPath.get(ppath)
However, the tar supports entries with the same name, and how this case is handled depends on the client side. Here, containerd handles them according to the following two rules:
- dir-over-dir: merge. Existing is a directory and new header is also TypeDir -> keep the directory, just re-apply metadata.
- everything else: remove + replace. Any other combination (file-over-file, file-over-dir, dir-over-file, symlink, etc.) ->
os.RemoveAll(path)wipes the old entry first.
Suppose we first create a new file in /a/b, making the /a cache loaded.
"/a" -> "/host/root/a"
Later, we do a dir-over-symlink, replacing /a directory with a symlink pointing to /etc. Then we create another new file /a/c. The actual path should be resolved to /host/root/etc by fs.RootPath().
"/a" -> "/host/root/a" # cached
"/a" -> "/host/root/a" --symlink--> "/etc" # actual
However, because of the cache mechanism, the /a still points to /host/root/a, which is a symlink to the host’s /etc, and the file finally ends up in /etc/c.
"/a/c" -> "/host/root/a/c" # expected
-> "/etc/c" # actual
It sounds like a pretty critical vulnerability — why don’t more people know about it?
Because it was introduced on Mar 8, 2025 (file diff) and later reverted on May 21, 2025 (revert commit), which means this bug was only alive for about two weeks, within a single sub-version (2.1.0 -> 2.1.1).
5. Summary
In this post, we’ve covered the pull flow and discussed the attack surfaces. In the next post, we’ll analyze how Docker uses runc to load a container, and take the NVIDIA toolkit as an example to understand how vendors bridge or customize their implementation within the Docker system.