Docker Internal (3)
In the third post, we’ll discuss how the container is loaded.
Since the vulnerability I found has not yet been patched 😢, I won’t discuss how the NVIDIA toolkit can work as a replacement runtime in this post. I’ll cover it in a future post once the bug has been fixed.
1. Load a Container
If you run docker run --rm -it ubuntu:24.04, dockerd will receive two HTTP requests. The first is to create a container, which is the same as executing docker create ubuntu:24.04.
POST /v1.54/containers/create HTTP/1.1
Host: api.moby.localhost
User-Agent: Docker-Client/29.5.2 (linux)
Content-Length: 1711
Content-Type: application/json
...
The second is to start the container, which is the same as executing docker start <container_id>.
POST /v1.54/containers/17b7029c5b5121a40ef71d91640fff00f20152df0b167a4464c02450c208b8a1/start HTTP/1.1
Host: api.moby.localhost
User-Agent: Docker-Client/29.5.2 (linux)
Content-Length: 0
dockerd’s initRoutes() defines both endpoint handlers, and we’ll read their implementation later.
// daemon/server/router/container/container.go
func (c *containerRouter) initRoutes() {
c.routes = []router.Route{
// [...]
router.NewPostRoute("/containers/create", c.postContainersCreate),
// [...]
router.NewPostRoute("/containers/{name:.*}/start", c.postContainersStart),
// [...]
}
}
1.1. Create
The request data is a JSON-formatted data that includes the container’s configuration. The actual data looks like:
{
"Hostname": "",
"Domainname": "",
"User": "",
"AttachStdin": false,
"AttachStdout": true,
"AttachStderr": true,
"Tty": false,
"OpenStdin": false,
"StdinOnce": false,
"Env": null,
"Cmd": null,
"Image": "ubuntu:24.04",
"Volumes": {},
"WorkingDir": "",
"Entrypoint": null,
"Labels": {},
"HostConfig": {
"Binds": null,
"ContainerIDFile": "",
"LogConfig": {
"Type": "",
"Config": {}
},
"NetworkMode": "default",
"PortBindings": {},
"RestartPolicy": {
"Name": "no",
"MaximumRetryCount": 0
},
"AutoRemove": false,
"VolumeDriver": "",
"VolumesFrom": null,
"ConsoleSize": [
50,
212
],
"CapAdd": null,
"CapDrop": null,
"CgroupnsMode": "",
"Dns": null,
"DnsOptions": [],
"DnsSearch": [],
"ExtraHosts": null,
"GroupAdd": null,
"IpcMode": "",
"Cgroup": "",
"Links": null,
"OomScoreAdj": 0,
"PidMode": "",
"Privileged": false,
"PublishAllPorts": false,
"ReadonlyRootfs": false,
"SecurityOpt": null,
"UTSMode": "",
"UsernsMode": "",
"ShmSize": 0,
"Isolation": "",
"CpuShares": 0,
"Memory": 0,
"NanoCpus": 0,
"CgroupParent": "",
"BlkioWeight": 0,
"BlkioWeightDevice": [],
"BlkioDeviceReadBps": [],
"BlkioDeviceWriteBps": [],
"BlkioDeviceReadIOps": [],
"BlkioDeviceWriteIOps": [],
"CpuPeriod": 0,
"CpuQuota": 0,
"CpuRealtimePeriod": 0,
"CpuRealtimeRuntime": 0,
"CpusetCpus": "",
"CpusetMems": "",
"Devices": [],
"DeviceCgroupRules": null,
"DeviceRequests": null,
"MemoryReservation": 0,
"MemorySwap": 0,
"MemorySwappiness": -1,
"OomKillDisable": false,
"PidsLimit": 0,
"Ulimits": [],
"CpuCount": 0,
"CpuPercent": 0,
"IOMaximumIOps": 0,
"IOMaximumBandwidth": 0,
"MaskedPaths": null,
"ReadonlyPaths": null
},
"NetworkingConfig": {
"EndpointsConfig": {
"default": {
"IPAMConfig": null,
"Links": null,
"Aliases": null,
"DriverOpts": null,
"GwPriority": 0,
"NetworkID": "",
"EndpointID": "",
"Gateway": "",
"IPAddress": "",
"MacAddress": "",
"IPPrefixLen": 0,
"IPv6Gateway": "",
"GlobalIPv6Address": "",
"GlobalIPv6PrefixLen": 0,
"DNSNames": null
}
}
}
}
postContainersCreate() first decodes the request into three different configs [1] and then creates a container based on these configs [2].
// daemon/server/router/container/container_routes.go
func (c *containerRouter) postContainersCreate(ctx context.Context, w http.ResponseWriter, r *http.Request, vars map[string]string) error {
// [...]
req, err := runconfig.DecodeCreateRequest(rdr, c.backend.RawSysInfo())
config, hostConfig, networkingConfig := req.Config, req.HostConfig, req.NetworkingConfig // [1]
// [...]
ccr, err := c.backend.ContainerCreate(ctx, backend.ContainerCreateConfig{ // [2]
Name: name,
Config: config,
HostConfig: hostConfig,
NetworkingConfig: networkingConfig,
Platform: platform,
DefaultReadOnlyNonRecursive: defaultReadOnlyNonRecursive,
})
// [...]
}
Internally, newContainer() is called to create a container instance and set its root directory to /var/lib/docker/containers/<id> [3].
// daemon/container.go
func (daemon *Daemon) newContainer(name string, platform ocispec.Platform, config *containertypes.Config, hostConfig *containertypes.HostConfig, imgID image.ID, managed bool) (*container.Container, error) {
// [...]
base := container.NewBaseContainer(id, filepath.Join(daemon.repository, id)) // [3]
// [...]
base.Config = config
base.HostConfig = hostConfig
// [...]
return base
}
After the container has been set up, its metadata is saved into config.v2.json for later use [4]. The host configuration is also saved, but it is kept separately in another file, hostconfig.json [5].
// daemon/container/container.go
func (container *Container) CheckpointTo(ctx context.Context, store *ViewDB) error {
// [...]
deepCopy, err := container.toDisk()
// [...]
}
func (container *Container) toDisk() (*Container, error) {
// [...]
pth, err := container.ConfigPath() // config.v2.json
f, err := atomicwriter.New(pth, 0o600)
w := io.MultiWriter(&buf, f)
if err := json.NewEncoder(w).Encode(container); err != nil { // [4]
// [...]
}
var deepCopy Container
if err := json.NewDecoder(&buf).Decode(&deepCopy); err != nil {
// [...]
}
deepCopy.HostConfig, err = container.WriteHostConfig() // <--------
// [...]
}
func (container *Container) WriteHostConfig() (*containertypes.HostConfig, error) {
// [...]
pth, err := container.HostConfigPath() // hostconfig.json
f, err := atomicwriter.New(pth, 0o600)
w := io.MultiWriter(&buf, f)
if err := json.NewEncoder(w).Encode(&container.HostConfig); err != nil { // [5]
// [...]
}
// [...]
}
We can see these files in the corresponding directory.
root@aaa:~# ls -al /var/lib/docker/containers/2fa14c3b70546123aa4de5628bad07282085500fb48dee65adae4546b55b7128/
total 20
drwx--x--- 3 root root 4096 Jun 3 11:15 .
drwx--x--- 4 root root 4096 Jun 3 11:36 ..
drwx------ 2 root root 4096 Jun 3 11:15 checkpoints
-rw------- 1 root root 2462 Jun 3 11:15 config.v2.json
-rw------- 1 root root 1216 Jun 3 11:15 hostconfig.json
These configs are loaded and used from dockerd’s memory store [6], which is a mapping from container’s ID to the container object.
// daemon/daemon.go
type Daemon struct {
// [..]
containers container.Store // [6]
// [..]
}
// daemon/container/memory_store.go
type memoryStore struct {
s map[string]*Container
sync.RWMutex
}
Every time dockerd restarts, the initialization function NewDaemon() calls loadContainers() [7] to cache all of them into the memory store to avoid heavy disk access.
// daemon/daemon.go
func NewDaemon(ctx context.Context, config *config.Config, pluginStore *plugin.Store, authzMiddleware *authorization.Middleware) (_ *Daemon, retErr error) {
// [...]
containers, err := d.loadContainers(ctx) // [7]
// [...]
}
func (daemon *Daemon) loadContainers(ctx context.Context) (map[string]map[string]*container.Container, error) {
// [...]
dir, err := os.ReadDir(daemon.repository)
// [...]
for _, v := range dir {
// [...]
id := v.Name()
c, err := daemon.load(id)
containers[c.ID] = c // <--------
// [...]
}
}
1.2. Start
After the container is created, the container-starting request is sent to dockerd to run the container.
Inside ContainerStart(), the daemonCfg is created to hold the current daemon (dockerd) configuration [1]. daemon.GetContainer() is then called to retrieve the matching container object from the memory store [2]. Finally, containerStart() is called to start the container with these configurations [3].
// daemon/server/router/container/container_routes.go
func (c *containerRouter) postContainersStart(ctx context.Context, w http.ResponseWriter, r *http.Request, vars map[string]string) error {
// [...]
if err := c.backend.ContainerStart(ctx, vars["name"], r.Form.Get("checkpoint"), r.Form.Get("checkpoint-dir")); err != nil { // <--------
return err
}
// [...]
}
// daemon/start.go
func (daemon *Daemon) ContainerStart(ctx context.Context, name string, checkpoint string, checkpointDir string) error {
daemonCfg := daemon.config() // [1]
// [...]
ctr, err := daemon.GetContainer(name) // [2]
// [...]
return daemon.containerStart(ctx, daemonCfg, ctr, checkpoint, checkpointDir, true) // [3]
}
// daemon/daemon.go
type configStore struct {
config.Config
Runtimes runtimes
}
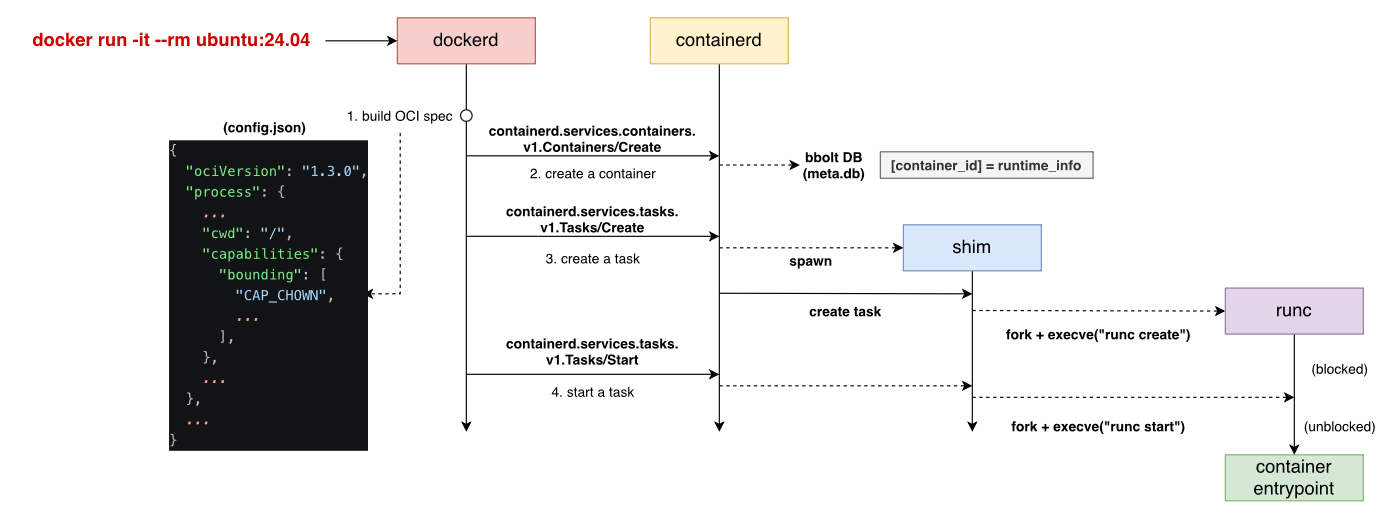
containerStart() does four things. First, it generates the container’s OCI spec [4], which determines the container’s runtime environment. Then it creates a container on the containerd side [5].
You may wonder why we still need to create another container even though we’ve already created it. Actually, these two creations are in different layers. The first is triggered by docker create ..., and it keeps metadata and config object in filesystem; it is for dockerd.
This time, the creation is for containerd-level container object. containerd inserts a record about the OCI spec and shim/runtime into the database.
After that, dockerd asks containerd to create a task [6]. A task is the containerd-level handle for the running container; creating it starts the shim daemon, which in turn creates the init process. At this point the task is created but stopped, waiting to be unblocked before it executes the entrypoint binary.
Later, it then calls tsk.Start() [7] to start the task, indirectly telling the shim daemon to unblock the init process, which finally executes the entrypoint binary and becomes the container.
// daemon/start.go
func (daemon *Daemon) containerStart(ctx context.Context, daemonCfg *configStore, container *container.Container, checkpoint string, checkpointDir string, resetRestartManager bool) (retErr error) {
// ... container setting
// 1. build OCI spec
spec, err := daemon.createSpec(ctx, daemonCfg, container, mnts) // [4]
// [...]
// 2. create a container (containerd.services.containers.v1.Containers/Create)
ctr, err := libcontainerd.ReplaceContainer(ctx, daemon.containerd, container.ID, spec, shim, createOptions, func(ctx context.Context, client *containerd.Client, c *containers.Container) error { // [5]
// [...]
is, ok := daemon.imageService.(*mobyc8dstore.ImageService)
img, err := is.ResolveImage(ctx, container.Config.Image)
// [...]
c.Image = img.Name
return nil
})
// [...]
// 3. create a task (containerd.services.tasks.v1.Tasks/Create)
tsk, err := ctr.NewTask(/* ... */) // [6]
// [...]
// 4. start the task (containerd.services.tasks.v1.Tasks/Start)
if err := tsk.Start(context.WithoutCancel(ctx)); err != nil { // [7]
// [...]
}
}
1.2.1. Create the OCI spec
createSpec() generates the OCI spec. It first gets the default spec [1] and registers config-parsing callbacks [2]. Later, the callbacks are invoked to modify the OCI spec [3].
// daemon/oci_linux.go
func (daemon *Daemon) createSpec(ctx context.Context, daemonCfg *configStore, c *container.Container, mounts []container.Mount) (retSpec *specs.Spec, _ error) {
var (
opts []coci.SpecOpts
s = oci.DefaultSpec() // [1]
)
opts = append(opts,
withCommonOptions(daemon, &daemonCfg.Config, c), // [2]
// [...]
)
// set options callback
return &s, coci.ApplyOpts(ctx, daemon.containerdClient, &containers.Container{ // <--------
ID: c.ID,
Snapshotter: snapshotter,
SnapshotKey: snapshotKey,
}, &s, opts...)
}
func ApplyOpts(ctx context.Context, client Client, c *containers.Container, s *Spec, opts ...SpecOpts) error {
for _, o := range opts {
if err := o(ctx, client, c, s); err != nil { // [3]
return err
}
}
return nil
}
Most fields described by the default spec [4] are the same as the finally generated JSON config if you don’t pass additional options.
// daemon/pkg/oci/defaults.go
func DefaultSpec() specs.Spec {
// [...]
return DefaultLinuxSpec()
}
func DefaultLinuxSpec() specs.Spec {
return specs.Spec{ // [4]
// [...]
Process: &specs.Process{
Capabilities: &specs.LinuxCapabilities{
Bounding: caps.DefaultCapabilities(),
Permitted: caps.DefaultCapabilities(),
Effective: caps.DefaultCapabilities(),
},
},
// [...]
}
}
1.2.2. Save Container Metadata into DB
The .ReplaceContainer() call is internally wrapped into a "/containerd.services.containers.v1.Containers/Create" request and sent to containerd [1].
// daemon/internal/libcontainerd/replace.go
func ReplaceContainer(ctx context.Context, client types.Client, id string, spec *specs.Spec, shim string, runtimeOptions any, opts ...containerd.NewContainerOpts) (types.Container, error) {
newContainer := func() (types.Container, error) {
return client.NewContainer(ctx, id, spec, shim, runtimeOptions, opts...)
}
ctr, err := newContainer() // <--------
// [...]
}
// vendor/github.com/containerd/containerd/api/services/containers/v1/containers_grpc.pb.go
func (c *containersClient) Create(ctx context.Context, in *CreateContainerRequest, opts ...grpc.CallOption) (*CreateContainerResponse, error) {
out := new(CreateContainerResponse)
err := c.cc.Invoke(ctx, "/containerd.services.containers.v1.Containers/Create", in, out, opts...) // [1]
// [...]
}
On the containerd side, _Containers_Create_Handler() is called to save the container object into the boltdb (/var/lib/containerd/io.containerd.metadata.v1.bolt/meta.db) [2].
bbolt is an embedded key/value database for Go, and here it is used as a metadata store by containerd.
// api/services/containers/v1/containers_grpc.pb.go
func _Containers_Create_Handler(srv interface{}, ctx context.Context, dec func(interface{}) error, interceptor grpc.UnaryServerInterceptor) (interface{}, error) {
// [...]
info := &grpc.UnaryServerInfo{
Server: srv,
FullMethod: "/containerd.services.containers.v1.Containers/Create",
}
handler := func(ctx context.Context, req interface{}) (interface{}, error) {
return srv.(ContainersServer).Create(ctx, req.(*CreateContainerRequest)) // <--------
}
// [...]
}
// plugins/services/containers/local.go
func (l *local) Create(ctx context.Context, req *api.CreateContainerRequest, _ ...grpc.CallOption) (*api.CreateContainerResponse, error) {
// [...]
if err := l.withStoreUpdate(ctx, func(ctx context.Context) error { // [2]
container := containerFromProto(req.Container)
// [...]
created, err := l.Store.Create(ctx, container)
resp.Container = containerToProto(&created)
// [...]
return nil
})
}
The container object here is different from dockerd’s. containerd’s container object is a runtime metadata record (ID, Runtime, Snapshotter, Image, Spec, Labels, …). They are persisted independently in different stores.
// core/containers/containers.go
type Container struct {
// [...]
Spec typeurl.Any
// [...]
}
If you are interested in how the DB entry looks, you can first install the bbolt CLI:
go install go.etcd.io/bbolt/cmd/bbolt@latest
It allows you to view the entry content from meta.db.
# [Check database file integrity]
bbolt check meta.db
## Response: OK
# [List the bucket]
bbolt buckets meta.db
## Response: v1
# [List and get keys]
bbolt keys meta.db v1
## Response:
## moby
## moby_history
## version
##
## PS. moby and moby_history are sub-buckets
bbolt keys meta.db v1 moby containers
## Response:
## db58127f96bd2c5655eb53f516ba7efeafac3c7335c5f2389e2b8a329e034b11
bbolt keys meta.db v1 moby containers db58127f96bd2c5655eb53f516ba7efeafac3c7335c5f2389e2b8a329e034b11 spec
## Response:
## 0a3674797065732e636f6e7461...(lots hex value)
## decoded: .. "ociVersion":"1.3.0","process":{"terminal":true,"consoleSize":{"height":50,"width":212}, ...
1.2.3. Create Bundle & Spawn shim Daemon
ctr.NewTask() ends up as a "/containerd.services.tasks.v1.Tasks/Create" request to containerd.
The handler Create() first gets the container object from the boltdb meta.db [1] and sets up the create options [2]. Finally, rtime.Create() is called with these options [3].
// plugins/services/tasks/local.go
func (l *local) Create(ctx context.Context, r *api.CreateTaskRequest, _ ...grpc.CallOption) (*api.CreateTaskResponse, error) {
container, err := l.getContainer(ctx, r.ContainerID) // [1]
// [...]
opts := runtime.CreateOpts{ // [2]
Spec: container.Spec,
IO: runtime.IO{
Stdin: r.Stdin,
Stdout: r.Stdout,
Stderr: r.Stderr,
Terminal: r.Terminal,
},
// [...]
Runtime: container.Runtime.Name,
// [...]
}
// [...]
rtime := l.v2Runtime
c, err := rtime.Create(ctx, r.ContainerID, opts) // [3]
// [...]
}
Inside Create(), NewBundle() is called to create the runtime container directories and files [4]. Later, m.manager.Start() [5] spawns a containerd-shim-runc-v2 process as the container shim daemon. Finally, shimTask.Create() sends a CreateTaskRequest to the shim daemon, which in turn executes the command run create --bundle <bundle_dir>.
// core/runtime/v2/task_manager.go
func (m *TaskManager) Create(ctx context.Context, taskID string, opts runtime.CreateOpts) (_ runtime.Task, retErr error) {
// [...]
bundle, err := NewBundle(ctx, m.root, m.state, taskID, opts.Spec) // [4]
shim, err := m.manager.Start(ctx, taskID, bundle, opts) // [5]
shimTask, err := newShimTask(shim)
// [...]
t, err := func() (runtime.Task, error) {
t, err := shimTask.Create(ctx, opts) // [6]
// [...]
}()
}
The OCI config file is created in NewBundle() with the path "/run/containerd/io.containerd.runtime.v2.task/<namespace>/<id>/config.json" [7].
// core/runtime/v2/bundle.go
func NewBundle(ctx context.Context, root, state, id string, spec typeurl.Any) (b *Bundle, err error) {
// [...]
ns, err := namespaces.NamespaceRequired(ctx) // ns == "moby"
b = &Bundle{
ID: id,
Path: filepath.Join(state, ns, id), // state == "/run/containerd/io.containerd.runtime.v2.task/"
// id == "<container id>"
// [...]
}
// [...]
if spec != nil {
if spec := spec.GetValue(); spec != nil {
// [...]
specPath := filepath.Join(b.Path, oci.ConfigFilename)
err = os.WriteFile(specPath, spec, 0666) // [7]
}
}
// [...]
}
The actual command for spawning a shim process looks like:
/usr/bin/containerd-shim-runc-v2 \
-namespace moby \
-address /run/containerd/containerd.sock \
-publish-binary /usr/bin/containerd \
-id 636494bd4a69bdaa80604b4ac2f7a0fee7bcdd58cb8f5884c2101666fbb24dd5 \
start
The arguments of the command executed by the shim daemon to create a container consist of the global part (before create) and the sub-command part (after create).
/usr/bin/runc \
--root /var/run/docker/runtime-runc/moby \
--log /run/containerd/io.containerd.runtime.v2.task/moby/636494bd4a69bdaa80604b4ac2f7a0fee7bcdd58cb8f5884c2101666fbb24dd5/log.json \
--log-format json \
--systemd-cgroup \
create \
--bundle /run/containerd/io.containerd.runtime.v2.task/moby/636494bd4a69bdaa80604b4ac2f7a0fee7bcdd58cb8f5884c2101666fbb24dd5 \
--pid-file /run/containerd/io.containerd.runtime.v2.task/moby/636494bd4a69bdaa80604b4ac2f7a0fee7bcdd58cb8f5884c2101666fbb24dd5/init.pid \
636494bd4a69bdaa80604b4ac2f7a0fee7bcdd58cb8f5884c2101666fbb24dd5
1.2.4. Enter the Container
In the final step, tsk.Start() is called to send a "/containerd.services.tasks.v1.Tasks/Start" request to containerd, whose handler is Start() in local.go.
This function first looks up the running task [1] and then sends a StartRequest to the shim daemon to start the container [2].
// plugins/services/tasks/local.go
func (l *local) Start(ctx context.Context, r *api.StartRequest, _ ...grpc.CallOption) (*api.StartResponse, error) {
t, err := l.getTask(ctx, r.ContainerID) // [1]
// [...]
p := runtime.Process(t)
// [...]
if err := p.Start(ctx); err != nil { // <--------
// [...]
}
// [...]
}
// core/runtime/v2/shim.go
func (s *shimTask) Start(ctx context.Context) error {
_, err := s.task.Start(ctx, &task.StartRequest{ // [2]
ID: s.ID(),
})
// [...]
}
On the shim daemon side, the command runc start <id> is executed to unblock the init process that runc create left parked just before execve().
The actual command line looks like:
/usr/bin/runc \
--root /var/run/docker/runtime-runc/moby \
--log /run/containerd/io.containerd.runtime.v2.task/moby/636494bd4a69bdaa80604b4ac2f7a0fee7bcdd58cb8f5884c2101666fbb24dd5/log.json \
--log-format json \
--systemd-cgroup \
start \
636494bd4a69bdaa80604b4ac2f7a0fee7bcdd58cb8f5884c2101666fbb24dd5
2. Runc Internal
Here, we try to understand how runc loads the container by reviewing the source code.
2.1. Cmd: create
The command “create” handler is startContainer(). It indirectly calls start(), which in turn calls createExecFifo() [1] to create a FIFO file and builds the init command by calling newParentProcess() [2]. Finally, parent.start() is called to execute runc init [3].
// create.go
var createCommand = &cli.Command{
Name: "create",
Action: func(_ context.Context, cmd *cli.Command) error {
// [...]
status, err := startContainer(cmd, CT_ACT_CREATE, nil) // <--------
// [...]
},
}
// libcontainer/container_linux.go
func (c *Container) start(process *Process) (retErr error) {
if process.Init {
// [...]
if err := c.createExecFifo(); err != nil { // [1]
return err
}
// [...]
}
// [...]
parent, err := c.newParentProcess(process) // [2]
if err := parent.start(); err != nil { // [3]
// [...]
}
}
newParentProcess() prepares the command line for /proc/self/fd/<runc_fd> init. The command and process information are wrapped into an initProcess object and returned [4].
// libcontainer/container_linux.go
func (c *Container) newParentProcess(p *Process) (parentProcess, error) {
else {
// [...]
safeExe, err = exeseal.CloneSelfExe(c.stateDir)
// [...]
exePath = "/proc/self/fd/" + strconv.Itoa(int(safeExe.Fd()))
// [...]
}
cmd := exec.Command(exePath, "init")
cmd.Args[0] = os.Args[0]
// [...]
if p.Init {
// [...]
return c.newInitProcess(p, cmd, comm) // [4]
}
}
parent.start() is then called to fork a child process and execve runc init [5].
Now there are two processes. The child (runc init) is the one that enters the new namespaces and sets up the container environment from the inside, such as mounting the filesystem and applying seccomp rules. It is the same process that will later execve the user’s command.
The parent stays on the host as a privileged helper, doing the things the child can’t do once it’s inside the namespaces: applying cgroups, providing the uid/gid maps, and running host-side hooks.
The two coordinate over a sync socket p.comm.syncSockParent [6]. Once the child is ready, the parent will receive the procReady event [7] and exit.
// libcontainer/process_linux.go
func (p *initProcess) start() (retErr error) {
// [...]
err := p.cmd.Start() // [5]
// [...]
if err := p.manager.Apply(p.pid()) // set up cgroups
if err := p.createNetworkInterfaces(); err != nil {
// [...]
}
if err := p.setupNetworkDevices(); err != nil {
// [...]
}
if p.config.Config.HasHook(configs.CreateContainer, configs.StartContainer) {
// [...]
}
ierr := parseSync(p.comm.syncSockParent /* [6] */, func(sync *syncT) error {
case procMountPlease:
// [...]
case procSeccomp:
// [...]
case procReady: // [7]
// [...]
case procHooks:
// [...]
// [...]
})
// [...]
return nil
}
Let’s see how runc init works.
2.2. Cmd: init
Before looking at the “init” implementation, we have to talk about the nsexec() constructor.
A Golang binary can use cgo to refer to C functions. Here, the nsexec() function works as a C constructor, so it is triggered before main().
// libcontainer/nsenter/nsenter.go
/*
#cgo CFLAGS: -Wall
extern void nsexec();
void __attribute__((constructor)) init(void) {
nsexec();
}
*/
import "C"
It does nothing if there is no pipe [1], but for runc init, because its parent process (runc create) sets up this environment variable for it, it passes the check and continues to run. The comment also implies the same thing.
// libcontainer/nsenter/nsexec.c
void nsexec(void)
{
// [...]
pipenum = getenv_int("_LIBCONTAINER_INITPIPE");
if (pipenum < 0) { // [1]
/* We are not a runc init. Just return to go runtime. */
return;
}
// [...]
}
This env is set to one side of the init socket pair [2] when runc create is preparing the command line of the init process.
// libcontainer/container_linux.go
func (c *Container) newParentProcess(p *Process) (parentProcess, error) {
// [...]
cmd.ExtraFiles = append(cmd.ExtraFiles, comm.initSockChild) // [2]
cmd.Env = append(cmd.Env,
"_LIBCONTAINER_INITPIPE="+strconv.Itoa(stdioFdCount+len(cmd.ExtraFiles)-1),
)
// [...]
}
Going back to nsexec(), we can see that it holds a complex stage machine to set up the isolated environment.
// libcontainer/nsenter/nsexec.c
void nsexec(void)
{
// [...]
switch (setjmp(env)) {
case STAGE_PARENT:
// [...]
case STAGE_CHILD:
// [...]
case STAGE_INIT:
// [...]
}
}
The diagram below may help you understand the whole flow.
stage-0 (STAGE_PARENT) // in host namespaces
| parse netlink bootstrap (cloneflags, uid/gid maps...)
(child)|
+------| clone_parent(&env, STAGE_CHILD)
| |
| | stage-1 >> SYNC_USERMAP_PLS
| | write /proc/<stage-1>/uid_map, gid_map
| | stage-1 << SYNC_USERMAP_ACK
| |
| |
| | stage-1 >> SYNC_RECVPID_PLS
| | receives stage-2 pid, forwards up to Go
| | stage-1 << SYNC_RECVPID_ACK
| | stage-1 >> SYNC_CHILD_FINISH
| + exit(0)
|
|
|
+-> stage-1 (STAGE_CHILD) // inside several new namespaces
| setns(provided namespaces)
|
| try_unshare(CLONE_NEWUSER)
| SYNC_USERMAP_PLS >> stage-0
| (waiting...)
| SYNC_USERMAP_ACK << stage-0
|
| try_unshare(config.cloneflags)
+------| clone_parent(&env, STAGE_INIT)
| |
| | SYNC_RECVPID_PLS >> stage-0
| | (waiting...)
| | SYNC_RECVPID_ACK << stage-0
| | SYNC_CHILD_FINISH >> stage-0
| + exit(0)
|
|
|
+-> stage-2 (STAGE_INIT) // inside ALL new namespaces, PID 1 in new pidns
| final cleanup
+ return (and continue)
The stage-1 child is required because unshare(CLONE_NEWPID) doesn’t move itself into the new PID namespace. That is why after the stage-1 process calls setns() and unshare() all namespaces, it has to fork the stage-2 child process, whose pid is 1 in the new namespace.
In fact, init() works as initializer for init package, but this function covers all init command handling, and main() won’t be executed later. Internally, startInitialization() is called to recover file descriptors, reconstruct the init configuration, and synchronize status with its parent process, runc create.
// init.go
func init() {
if len(os.Args) > 1 && os.Args[1] == "init" {
libcontainer.Init() // <--------
}
}
// libcontainer/init_linux.go
func Init() {
// [...]
if err := startInitialization(); err != nil { // <--------
// [...]
}
// [...]
}
func startInitialization() (retErr error) {
// [...]
envInitPipe := os.Getenv("_LIBCONTAINER_INITPIPE")
initPipeFd, err := strconv.Atoi(envInitPipe)
initPipe := os.NewFile(uintptr(initPipeFd), "init") // use as Go file object
// [...]
var config initConfig
if err := json.NewDecoder(initPipe).Decode(&config); err != nil {
return err
}
// [...]
return containerInit(it, &config, syncPipe, consoleSocket, pidfdSocket, fifoFile, logPipe)
}
containerInit() handles two init types. If a new container is being created, the init type will be initStandard [1]; otherwise, when attaching to an already-running container, initSetns is used [2].
// libcontainer/init_linux.go
func containerInit(t initType, config *initConfig, pipe *syncSocket, consoleSocket, pidfdSocket, fifoFile, logPipe *os.File) error {
switch t {
case initSetns: // [2]
i := &linuxSetnsInit{
// [...]
}
return i.Init()
case initStandard: // [1]
i := &linuxStandardInit{
// [...]
}
return i.Init()
}
}
runc init now is still root and has full privileges inside the namespaces. It sets up the environment inside the container, such as network routing [3] and the filesystem [4]. Later, it calls finalizeNamespace() [5] to drop capabilities, change the working directory, and close all leaked file descriptors.
Before executing the entrypoint binary [6], it reopens the FIFO file with only write permission [7], and this behavior causes runc init to be blocked until someone opens the same FIFO file with read permission.
// libcontainer/standard_init_linux.go
func (l *linuxStandardInit) Init() error {
// [...]
if err := setupNetwork(l.config); err != nil { // [3]
return err
}
// [...]
err := prepareRootfs(l.pipe, l.config) // [4]
// [...]
if err := finalizeNamespace(l.config); err != nil { // [5]
return err
}
// [...]
fifoFile, err := pathrs.Reopen(l.fifoFile, unix.O_WRONLY|unix.O_CLOEXEC) // [7]
// [...]
name, err := exec.LookPath(l.config.Args[0])
// [...]
return linux.Exec(name, l.config.Args, l.config.Env) // [6]
}
You can probably guess who the reader is. That’s right, it’s runc start!
2.3. Cmd: start
runc init is blocked and waiting for a reader, and now the status of the container is Created.
The shim handles the start-container request by executing runc start, and the action callback calls container.Exec() [1] when the status of the container is Created [2].
// start.go
var startCommand = &cli.Command{
Name: "start",
Action: func(_ context.Context, cmd *cli.Command) error {
// [...]
container, err := getContainer(cmd)
// [...]
switch status {
case libcontainer.Created: // [2]
// [...]
if err := container.Exec(); err != nil { // [1]
// [...]
}
// [...]
}
// [...]
}
}
Exec() finally calls handleFifo() [3] to open the FIFO file with read permission, which allows runc init to continue running and enter the container.
// libcontainer/container_linux.go
func (c *Container) Exec() error {
// [...]
return c.exec() // <--------
}
func (c *Container) exec() error {
path := filepath.Join(c.stateDir, execFifoFilename)
if err := handleFifo(path, c.initProcess.pid()); err != nil { // [3]
// [...]
}
return c.postStart() // run Poststart hook
}
2.4. Others
If you want to test these behaviors directly by runc, you can follow the steps below.
First, create a bundle directory to save the root filesystem and config.json.
mkdir container_bundle
cd container_bundle
Then extract the root filesystem from a docker image into the rootfs directory.
docker create --name temp ubuntu:24.04
mkdir rootfs
docker export temp | tar -C rootfs -xvf -
docker rm temp
The runc “spec” command can generate a default OCI spec config.json.
runc spec
Modify config.json to update the entry command.
{
"ociVersion": "1.2.1",
"process": {
...
+ "terminal": false,
- "terminal": true,
"args": [
- "sh"
+ "/usr/bin/sleep", "3600"
]
Now you can create a container based on the bundle.
sudo runc create --bundle . my_container_id
View the status of all containers, and our container is created.
sudo runc list
ID PID STATUS BUNDLE CREATED OWNER
my_container_id 63886 created /tmp/container_bundle 2026-06-04T03:54:00.492598105Z root
If you list the fds of this container, you can find that there is a FIFO file.
ls -al /proc/63886/fd/
# [...]
l--------- 1 root root 64 Jun 4 11:55 7 -> /run/runc/my_container_id/exec.fifo
# [...]
After starting the container, you can see our entry command sleep 3600 is running now!
sudo runc start my_container_id
ps aux | grep sleep
root 64268 0.0 0.0 2704 1688 ? Ss 12:05 0:00 /usr/bin/sleep 3600
3. Summary
This post covers the process of loading a container, including the implementation of runc. In the next post, I will analyze runtime replacement and the hook interfaces exposed by Docker, using the NVIDIA Toolkit as an example.