CPU Speculation Vulnerabilities And Mitigations in the Linux Kernel
近期 CTF 比賽或是 exploit 分析時不斷接觸到 Spectre 與 Meltdown,而對於硬體類型的漏洞我一直都不是很熟,因此就趁這個機會追一下原理並記錄下來。雖然許多細節沒有深追,像硬體設計就直接以第二手的資料為主,完全沒參考 intel 的官方文件,但仍希望能給不想深追實作的人一些方向。
1. CPU Speculation Overview
CPU Speculation 是一種 CPU 先預測程式 branch 來提高效能的機制,Spectre 則是利用該機制產生的 side effect 來 leak 敏感資料的技巧。
最一開始時,CPU 被設計成 sequentially fetch instruction 並執行,也就是說在執行下一個 instruction 前,需要等目前的 instruction 執行完。後來 CPU 實作了 instruction pipelining 做到 Instruction Level Parallelism (ILP),該機制把一個 instruction 的執行拆成多個 stage (IF, ID, EX, MEM, WB, …),每個 stage 在彼此互不影響的情況下可以同步進行,大幅增加了執行效能。然而,該機制卻沒有辦法很好的處理 branch,因為最終的 branch condition 需要等前面的 instruction 都執行完才能確定,這讓 pipeline 被迫暫停。
為了解決該瓶頸,CPU 實作了分支預測 (branch prediction,也可稱作 speculative execution) 的機制,在遇到 branch 時就先猜最有可能走到的並繼續 pipelining,猜對的話就可以大幅增加執行效能,猜錯把執行結果捨棄掉,不會對後續執行有什麼影響。除了 branch 的預測之外,相同概念的實作還有包含了 data 與 instruction 的預測:
- 指令預取 (Instruction Prefetching) - 提前把未來可能需要的指令 load 到 cache
- 資料預取 (Data Prefetching) - 提前把未來可能需要的資料 load 到 cache
然而,這樣的優化機制也帶來了一些問題,最著名的就是 Spectre 系列和 Meltdown 漏洞。關於 Meltdown 可以參考之前的文章 Linux Kernel Meltdown Mitigation Analysis,而這篇文章會介紹 Spectre 一系列的漏洞,不過可以用一句話表示核心概念:「不正確的推測執行對 CPU 造成的影響會被恢復,但會對 cache 的影響不會」。
Linux user 可以看 /proc/cpuinfo 的 bugs 欄位看目前使用的 CPU 型號有什麼硬體問題,範例輸出如下:
aaa@debian:~$ cat /proc/cpuinfo | grep bugs
bugs : spectre_v1 spectre_v2 spec_store_bypass swapgs itlb_multihit mmio_stale_data eibrs_pbrsb gds
非常建議讀者可以看投影片 Spectre(v1 v2 v4) v.s. meltdown(v3),內容用許多圖表清楚呈現漏洞成因與利用流程,此外也包括非常多細節。Linux kernel 也有在文件中說明 Spectre 的 mitigation,不過對漏洞本身就有沒過多的介紹。
2. Spectre V1
在正常情況下,程式在存取 array 時會進行 bound check,確保在合法範圍內。但是在執行 bound check 時,CPU 可能會提前執行後續的存取 array 的指令,即使這些指令最終可能被視為是 invalid。透過這個特性,攻擊者可以先執行幾次合法的存取來 train CPU,讓其誤以為之後的幾次操作也會走相同的 branch。之後攻擊者給一個非法的 index,雖然軟體層的檢查會失敗而離開,但是硬體層卻會因為 speculative execution 推測性地以 bound 外的 index 來存取 array,即使存取的資料會被 discard,不過 memory access 影響的 cache 狀態卻不會被 rollback。而後,攻擊者可以透過測量 memory 存取的時間來判斷 target memory 是否在 cache 中,藉此 side channel 出 speculative execution 所存取的 data。
Linux kernel 官方文件 speculation.txt 對 Spectre V1 有做詳細的介紹,內文中以一個有問題的 code pattern 作為例子講解。Function load_array() 會先對 user 提供的 index 做 bound check,如果合法才會回傳 array element。
int load_array(int *array, unsigned int index)
{
if (index >= MAX_ARRAY_ELEMS)
return 0;
else
return array[index];
}
load_dependent_arrays() 會呼叫兩次 load_array(),第一次以 user provided index 來存取 array1 [1],而第二次以 array1 element 為 index 來存取 array2 [2]。
int load_dependent_arrays(int *arr1, int *arr2, int index)
{
int val1, val2,
val1 = load_array(arr1, index); // [1]
val2 = load_array(arr2, val1); // [2]
return val2;
}
然而,在 CPU mis-predict 發生的情況下,可以想成 load_array() 直接存取 array element,
int load_array(int *array, unsigned int index)
{
return array[index];
}
因此在第一次 load_array() 時會回傳 OOB read 的 value,而第二次 load_array() 則會以該 value 為 index 存取 array2。在預測執行的過程中,兩次 array 的存取都會影響到 memory cache,所以攻擊者可以透過第一次 load_array() 時 OOB read 讀到 victim address 的資料,第二次 load_array() 以資料內容為 index 來更新 cache,之後就能看 array2 哪個 index 的存取速度比較快 side channel 出資料內容。
Linux kernel 實作了 array_index_nospec() 作為 Spectre V1 的 mitigation,該 function 會對 index 做 mask,因此就算預測發生,index 一樣會執行 mask 操作,確保不會發生 OOB access。
#define array_index_nospec(index, size) \
({ \
typeof(index) _i = (index); \
typeof(size) _s = (size); \
unsigned long _mask = array_index_mask_nospec(_i, _s); \
\
BUILD_BUG_ON(sizeof(_i) > sizeof(long)); \
BUILD_BUG_ON(sizeof(_s) > sizeof(long)); \
\
(typeof(_i)) (_i & _mask); \
})
如果要避免 load_array() 發生 Spectre V1 的漏洞,只需要在存取 array element 前加一行 array_index_nospec() 來限制 index 即可 [3]。
int load_array(int *array, unsigned int index)
{
if (index >= MAX_ARRAY_ELEMS)
return 0;
else {
index = array_index_nospec(index, MAX_ARRAY_ELEMS); // [3]
return array[index];
}
}
2.1 corCTF 2024 - Its Just a Dos Bug Bro
參考: https://www.willsroot.io/2024/08/just-a-dos-bug.html
VM 執行環境的 rootfs 為 initramfs,boot parameter 中比較重要的是 "clearcpuid=smap pti=on",也就是沒開 SMAP 但有開 SMEP (default) 以及 PTI。
題目新增了兩個 syscall,其中一個有 Spectre V1 pattern 的 syscall。idx1 為 user space 提供的值,會以此 value 作為 index 來讀 kernel data corctf_note[],因此可以任意讀 [1]。讀完之後再下方才檢查 idx1 是否合法 [2],如果合法就會複製資料到 user space [3]。
SYSCALL_DEFINE4(corctf_read_note, char *, addr, uint64_t, idx1, uint64_t, idx2, uint64_t, stride)
{
uint64_t off = corctf_note[idx1]; // [1]
if (strlen(corctf_note) > idx1 && strlen(corctf_note) > idx2) { // [2]
return copy_to_user(addr + (off << stride), corctf_note + idx2, 1); // [3]
}
// [...]
}
由於先讀再檢查,所以可以先 OOB read 任意位址的 1 byte 到 off,而題目又是 host 在 i5-8250U 上,為受到 Spectre 影響的 CPU 型號,還能假設 train 好的 CPU 會無視 off 的檢查 [2],預先執行 copy_to_user() [3]。
ramfs 的 file 會放在 memory 內,所以我們可以透過 side channel 的方式 leak,從 memory 中 leak /flag 內容,步驟如下:
- 用 EntryBleed Leak KASLR,取得
corctf_note[]的位址 - 利用 Spectre V1 leak
page_offset_base內容取得 physical mappings address - Spectre V1 heuristically scan physmap,找出 flag pattern
corctf{ ... }
參考作者附上的 exploit。一開始會先用另一個 syscall corctf_write_note 初始化 corctf_note[] 成 tlb_smart_write[],並且後續 corctf_write_note 都會以 7 為 stride size。
#define STRIDE_SHIFT 7
#define STRIDE (1 << STRIDE_SHIFT)
uint8_t tlb_smart_write[0x10] = "\x01\x21\x41\x61\x81\xa1\xc1\xe1skibidi";
Function spectre() 負責做 side channel attack,第一個 for loop [4] 負責把 buffer 載入到 TLB 內,因為 TLB 為 page granularity,才會以每 0x20 為一個 range 來存取 (0x20 « 7 為 0x1000)。第二個 for loop [5] 用來 train CPU predictor,讓 CPU 在接下來執行 syscall corctf_read_note 時遇到 branch 時會預測執行 copy_to_user()。因為要測量存取速度的時間差,所以我們還需要在 access 前把 buffer 從 L1-L3 cache line 中 flush 掉 [6],最後以目標 address 的 idx 呼叫 syscall [7],並測量時間差來判斷 [8]。
static inline uint64_t spectre(char *buffer, off_t offset, uint64_t idx, uint64_t train, uint64_t bound) {
// ============== [4] ==============
for (int i = 0; i < strlen(tlb_smart_write) /* 15 */; i++) {
// access &buf[0x80], &buf[0x1080], ...
corctf_read(buffer, i);
}
// ============== [5] ==============
for (int i = 0; i < train; i++){
corctf_read(buffer, 0xd);
}
// ============== [6] ==============
flush_buffer((void *)buffer, MAP_SIZE);
asm volatile ("mfence;");
// ============== [7] ==============
corctf_read(buffer, idx);
// ============== [8] ==============
return get_time(buffer, offset);
}
預測執行存取到的位置會被載入到 cache,下次存取時就能快速取得資料,也就代表存取時間較短。文章 TLB and cache 有一張圖清楚地呈現存取 virtual address 時硬體的執行流程。
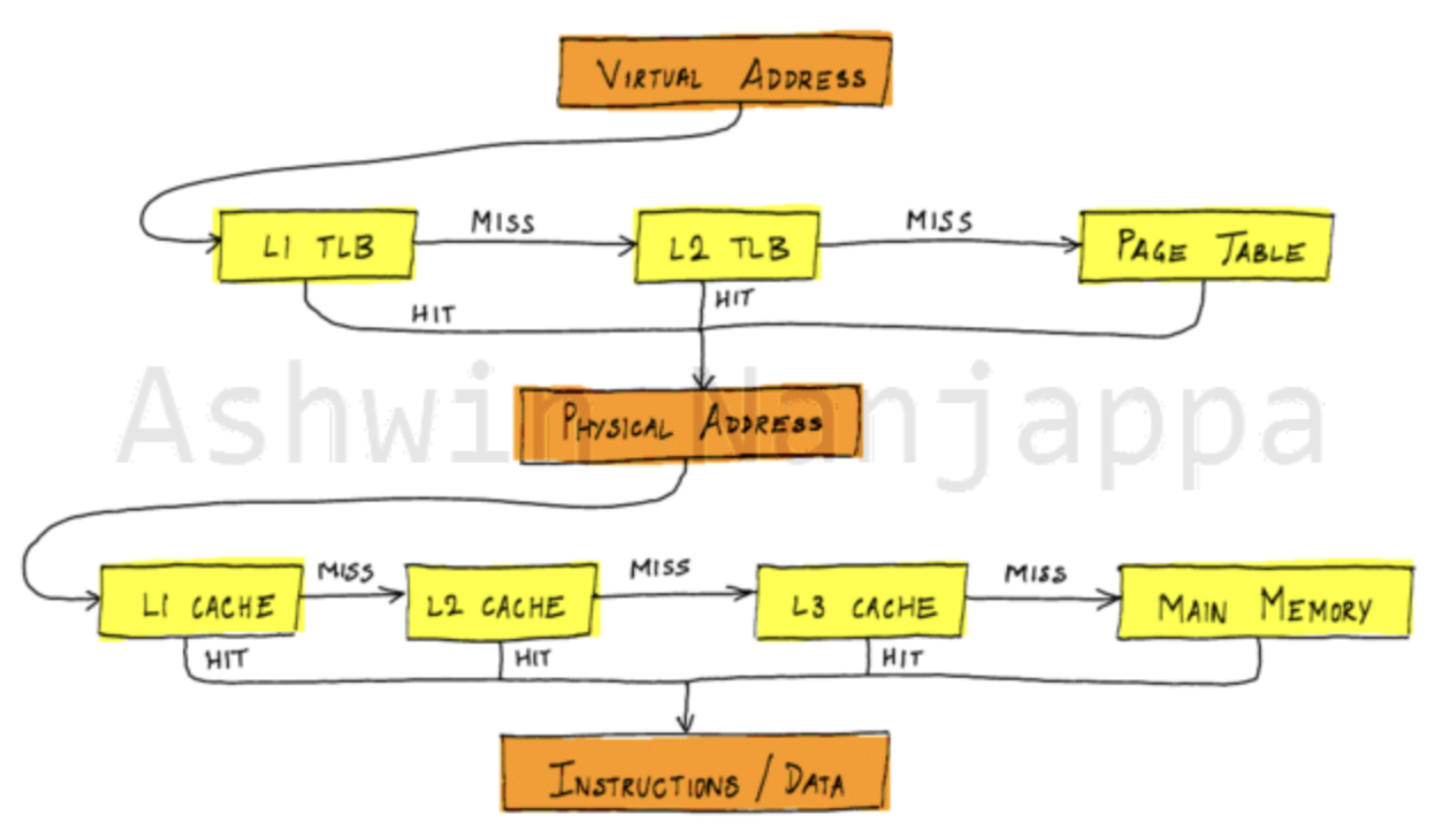
用於 flush cache 的 function flush_buffer() 會以 cache line (64 bytes) [9] 為單位執行 instruction clflush,該 instruction 會在每個 cache level 都 invalidate 傳入的 address,也就意味著從 cache 清空。
#define LINE_SIZE 64
void flush_buffer(void *addr, size_t size) {
for (off_t i = 0; i < size; i += LINE_SIZE) { // [9]
clflush(addr + i);
}
}
void clflush(void *addr) {
asm volatile(INTEL(
"clflush [%[addr]];"
)::[addr]"r"(addr):);
}
不過為什麼會需要關閉 SMAP 呢?作者提到 copy_{from,to}_user() 會執行的 instruction stac 與 clac 有 speculative barrier 的功能,因此才需要 disable SMAP,這部分我們在下個 section 也會提到。
2.2 CVE-2023-0458 - Linux Kernel Spectre-v1 gadgets
https://github.com/google/security-research/security/advisories/GHSA-m7j5-797w-vmrh
該 CVE 是發生在 Linux kernel 6.1.8 以前的 Spectre-v1 code,syscall getrlimit 會呼叫 kernel function do_prlimit(),而該 function 一開始會有一個 resource value 的 bound check [1],之後以 resource 為 offset [2],將對應目標位址的內容複製到 old_rlim [3]。雖然只有 dereference kernel pointer,並不能 leak kernel data,但還是可以 side-channel 出該 pointer 的位址。
static int do_prlimit(unsigned int resource, /* ... */)
{
if (resource >= RLIM_NLIMITS) // [1]
return -EINVAL;
// [...]
rlim = tsk->signal->rlim + resource; // [2]
// [...]
if (!retval) {
if (old_rlim)
*old_rlim = *rlim; // [3]
// [...]
}
}
Patch 則是對 resource 加上 array_index_nospec 的操作來限制範圍。
if (resource >= RLIM_NLIMITS)
return -EINVAL;
+ resource = array_index_nospec(resource, RLIM_NLIMITS);
另外該 CVE 的敘述中還提到了另一個漏洞 CVE-2023-0459,漏洞成因是 copy_from_user() 沒有加上 speculation barrier,導致 access_ok(from, n) 可以被 mis-speculated,而 pointer from 又是使用者可控,因此會有 Spectre 的問題;相反地,copy_to_user() 不會有問題是因為使用者沒辦法控 source pointer,沒有辦法影響到 cache。
Patch 則是在 raw copy 之前加上 barrier_nospec(),也就是 instruction lfence (load fence)。根據文件敘述,該 instruction 可以確保不會有任何在 lfence 後面的 instruction 偷偷先被執行,即使 CPU 發生預測執行,也會因為執行到該 instruction 而不會往下執行到會影響 cache 的 raw_copy_from_user()。
if (!should_fail_usercopy() && likely(access_ok(from, n))) {
+ /*
+ * Ensure that bad access_ok() speculation will not
+ * lead to nasty side effects *after* the copy is
+ * finished:
+ */
+ barrier_nospec();
instrument_copy_from_user_before(to, from, n);
res = raw_copy_from_user(to, from, n);
我們在 section “2.1 corCTF 2024 - Its Just a Dos Bug Bro” 的結尾有提到 instruction stac 與 clac 都可以當作 speculative barrier,原因是他們都屬於 serializing instruction,在執行後 CPU 會確保在此之前的 instruction 都會執行完。CVE-2023-0458 的作者也有在 exploit 的過程中發現這個特性,並在 CVE description 的 section “SMAP Effects on Exploitation” 詳述了實驗過程。
The gadgets we found are still exploitable on systems that do not enable SMAP.
3. Spectre V2
Spectre V2 雖然最後一樣是透過 data access time 來 side channel 出 data,但原理與利用方式與 V1 有很大的不同。
Spectre V2,又稱 Branch Target Injection (BTI),主要 CPU 執行 indirect jump 有關,當 jump-related instruction 如 call 或 jmp 被呼叫時,CPU 會去更新 Indirect Branch Predictor (IBP) 內的 Branch History Buffer (BHB) 與 Indirect Branch Target Buffer (IBTB),這兩個 buffer 會紀錄過去 indirect branch 的跳轉狀況與目標。
攻擊者透過不斷執行相同的程式碼來 train IBP,讓 IBP 誤以為執行到 instruction A 時,indirect jump 有很高的機率會跳去 B 執行。但實際上在其他 process 的 memory mapping 的 B 其實是另外一段程式碼 B’,或者不同的 control flow 走到 A 一定不會執行到 B。因為他們都使用同一個 CPU 來執行,所以共享了 CPU 的執行狀態,導致 CPU 發生錯誤預測並提前執行。根據情況以及挑選的 gadget 不同,target address 的 data 會以 memory 的方式被 cache 起來,最後用與存取速度差,也就是與 V1 相同的方式來 leak。
以 Spectre(v1 v2 v4) v.s. meltdown(v3) 內的投影片為例,該 PoC 透過 Spectre V2,從 Guest VM side-channel 來 leak Host kernel 的 core_pattern[] 內容。
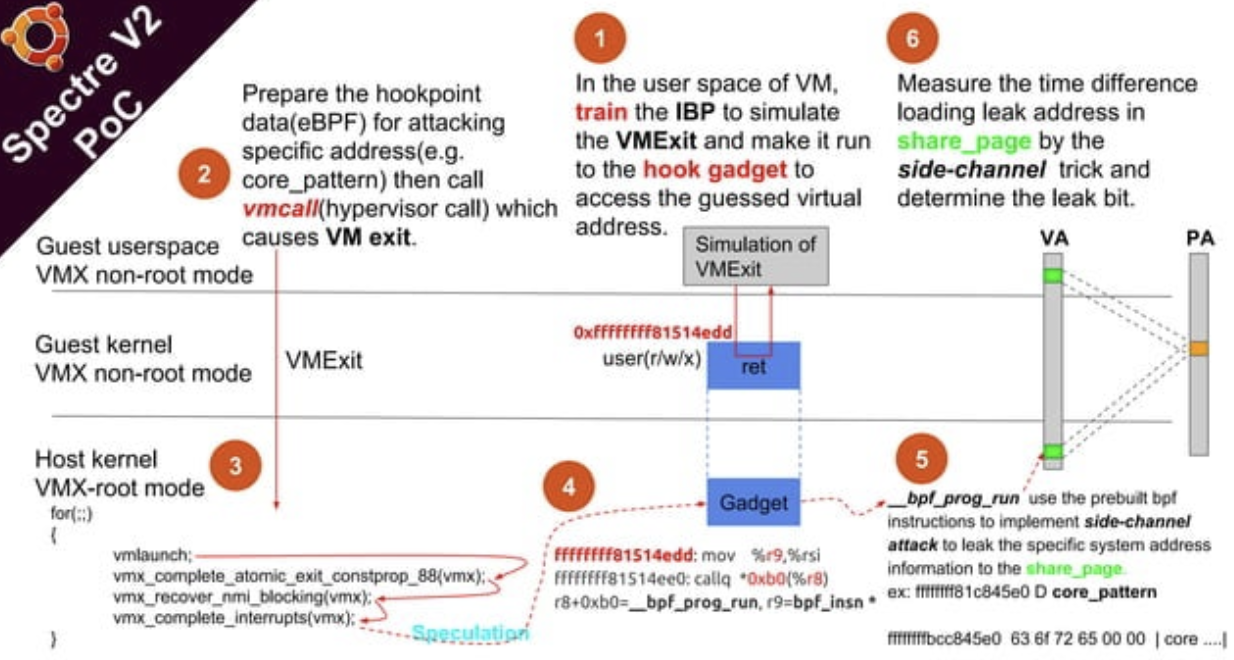
- 一開始要 train IBP,先在 user space 模擬 Host VMExit 的處理流程,並且在模擬完後執行到 address
0xffffffff81514edd,該位址在 VM 只會是一個 instructionret,但在 Host 是執行 eBPF program 的 hook gadget。Train 完後,IBP 就會認為 VMExit 跑完後就要跳去執行0xffffffff81514edd - 準備 eBPF instructions 在 share data 或是其他可控的地方,而 instructions 會去 load
core_pattern[]data,並以 side channel 方式存取 memory。 - Guest 執行 VMExit 後 trap 到 Host kernel,由於我們在步驟一 train IBP 的關係,CPU 會預先執行到 hook gadget
0xffffffff81514edd - Hook gadget 會去執行
__bpf_prog_run(insns) - 這些 eBPF instructions 會 side-channel data 到與 Guest VM share 的 memory region
- Host 處理完 trap 後,Guest VM 就可以用存取時間差來 leak 資料內容
如果要解決 Spectre V2 的問題,大致可以分成兩種做法:直接操控 CPU 對於 speculation 處理 (硬體) 或間接控制 speculation 行為 (軟體),前者需要透過 update microcode 或是 register,後者則以效能為代價讓 indirect jump 多一些檢查,細節可以參考官方文件 Retpoline: A Branch Target Injection Mitigation。Retpoline (return + trampoline) 則是一種 hybrid 的做法,除了更新 microcode 讓 speculation 更可以預測,也在軟體層用不會有問題的方式完成 indirect jump。
Retpoline 實際上是利用了 Return Stack Buffer (RSB) 預測方式的特性,當執行一個 direct call 時,下一個 instruction 的位置除了會被放到 memory stack 上,也會存一份到硬體 RSB。在 CPU 預測執行時,會取出 RSB 最上面的位址 (stack is FIFO) 做為先執行的 instruction address。因為預測位址是由 RSB 拿,每次 call 時都會 push next instruction 到 RSB,因此不會受到 train 好的 predictor 影響,只需要看當預測執行 next instruction 時會不會有 side effect。
以下方為例,當使用 indirect jump 時就有會有 Spectre V2 的問題,像是 jmp 到 register derefence 出來的位址。
jmp *%rax
同樣目的若用 retpoline 的機制完成的話,就會被拆成多個步驟:
call load_label
capture_ret_spec:
pause ; LFENCE
jmp capture_ret_spec
load_label:
mov %rax, (%rsp)
RET
- 直接呼叫 label
load_label,下個 instruction 被放到 RSB 最上方 - Label
load_label把[rax]放到[rsp],也就是覆蓋掉 return address - 執行
retinstruction return 到上個 function frame,也就是跳到[rax]
在步驟 3,如果 ret instruction 被預測執行,[rsp] 會處於沒有被更新的狀態,所以會跳去 label capture_ret_spec,但是該 label 執行到的卻是負責 Spin Loop Hint 的 instruction pause,因此 speculation 就不會繼續下去。
另一種常見的 pattern 則是 indirect call,
call *%rax
雖然大致上是用一樣的做法,但因為原本的 instruction 是 call,需要紀錄 return address,因此才多 call 一層。
jmp label2
label0:
call label1
capture_ret_spec:
pause ; LFENCE
jmp capture_ret_spec
label1:
mov %rax, (%rsp)
RET
label2:
call label0
; ...
Linux kernel 一共實作 3 種 type 以及與 17 個不同 register 的 retpoline helper。Type 可以分成通用、call 以及 jump,通用同時可以處理 indirect call 以及 indirect jmp;register 則是取決於目標位址被放在哪個 register。
# (type) (register)
__x86_indirect_{,call,jump}_thunk_{array,r10,...,rsi,rsp}
下方為 __x86_indirect_thunk_array() 為例,assembly 看起來長得跟先前提到處理 indirect jmp 的範例程式碼很像,不過這邊不是用 pause 而是 int3,應該也能作為一種 fence instruction (?)
<__x86_indirect_thunk_array>: call 0xffffffff82437aa6 <__x86_indirect_thunk_array+6>
<__x86_indirect_thunk_array+5>: int3
<__x86_indirect_thunk_array+6>: mov QWORD PTR [rsp],rax
<__x86_indirect_thunk_array+10>: ret