ENOMEM In Linux Kernel
How to reliably make memory allocation related APIs return -ENOMEM in the linux kernel? You might initially think of using fault injection to achieve this, but only root users can access the exposed debugfs. Additionally, the OOM killer will terminate processes and reclaim objects from them whenever free memory falls below the threshold.
Theoretically, it is extremely challenging to precisely control the amount of free memory. However, the CVE-2023-2236, an UAF vulnerability, occurs when a kmalloc() call returns NULL for a small size allocation.
Suprisingly, this vulnerability was demonstrated to be exploitable in the kCTF, suggesting that it is possible to control whether kmalloc() succeeds or fails in some way.
In this article, I will explore the feasibility of precisely managing memory usage within the Linux kernel. Enjoy 🙂!
1. Allocate Pages
We can reliably allocate a page of memory using the system call SYS_mmap.
ptr = mmap(NULL, PAGE_SIZE, PROT_READ | PROT_WRITE, MAP_ANON | MAP_PRIVATE | MAP_POPULATE, -1, 0);
if (ptr == MAP_FAILED) perror_exit("mmap failed");
The backtrace from allocating a page to updating the allocation information in the zone state is as follows:
#0 zone_page_state_add
#1 __mod_zone_page_state
#2 rmqueue_bulk
#3 __rmqueue_pcplist
#4 rmqueue_pcplist
#5 rmqueue
#6 get_page_from_freelist
#7 __alloc_pages
#8 alloc_pages
#9 pagetable_alloc
#10 __pte_alloc_one
#11 pte_alloc_one
#12 __pte_alloc
#13 do_anonymous_page
#14 do_pte_missing
#15 handle_pte_fault
#16 __handle_mm_fault
#17 handle_mm_fault
#18 faultin_page
#19 __get_user_pages
#20 populate_vma_page_range
#21 __mm_populate
#22 mm_populate
#23 vm_mmap_pgoff
The function populate_vma_page_range() is called to populate a page. If the page is an anonymous page (i.e., mapped to RAM memory instead of a file), the function do_anonymous_page() will be internally invoked [1].
long populate_vma_page_range(struct vm_area_struct *vma,
unsigned long start, unsigned long end, int *locked)
{
// [...]
ret = __get_user_pages(mm, start, nr_pages, gup_flags, // <-----------------
NULL, locked ? locked : &local_locked);
// [...]
}
static long __get_user_pages(struct mm_struct *mm,
unsigned long start, unsigned long nr_pages,
unsigned int gup_flags, struct page **pages,
int *locked)
{
// [...]
do {
page = follow_page_mask(vma, start, foll_flags, &ctx);
if (!page || /* ... */) {
ret = faultin_page(vma, start, &foll_flags, // <-----------------
PTR_ERR(page) == -EMLINK, locked);
// [...]
}
// [...]
start += page_increm * PAGE_SIZE;
nr_pages -= page_increm;
} while (nr_pages);
// [...]
}
static int faultin_page(struct vm_area_struct *vma,
unsigned long address, unsigned int *flags, bool unshare,
int *locked)
{
// [...]
ret = handle_mm_fault(vma, address, fault_flags, NULL); // <-----------------
// [...]
}
vm_fault_t handle_mm_fault(struct vm_area_struct *vma, unsigned long address,
unsigned int flags, struct pt_regs *regs)
{
// [...]
ret = __handle_mm_fault(vma, address, flags); // <-----------------
// [...]
}
tatic vm_fault_t __handle_mm_fault(struct vm_area_struct *vma,
unsigned long address, unsigned int flags)
{
// [...]
return handle_pte_fault(&vmf); // <-----------------
}
static vm_fault_t handle_pte_fault(struct vm_fault *vmf)
{
// [...]
if (!vmf->pte)
return do_pte_missing(vmf); // <-----------------
// [...]
}
static vm_fault_t do_pte_missing(struct vm_fault *vmf)
{
if (vma_is_anonymous(vmf->vma)) // !vma->vm_ops
return do_anonymous_page(vmf); // [1]
// [...]
}
The function do_anonymous_page() first calls pte_alloc() [2]. If it detects that there is no PMD (Page Middle Directory), it invokes pagetable_alloc() [3] to allocate a page table. Then, it calls vma_alloc_zeroed_movable_folio() [4] to allocate a page for the PTE (Page Table Entry).
static vm_fault_t do_anonymous_page(struct vm_fault *vmf)
{
// [...]
pte_alloc(vma->vm_mm, vmf->pmd); // [2]
// [...]
folio = vma_alloc_zeroed_movable_folio(vma, vmf->address); // [4]
}
#define pte_alloc(mm, pmd) (unlikely(pmd_none(*(pmd))) && __pte_alloc(mm, pmd))
int __pte_alloc(struct mm_struct *mm, pmd_t *pmd)
{
pgtable_t new = pte_alloc_one(mm); // <-----------------
// [...]
}
pgtable_t pte_alloc_one(struct mm_struct *mm)
{
return __pte_alloc_one(mm, __userpte_alloc_gfp); // <-----------------
}
static inline pgtable_t __pte_alloc_one(struct mm_struct *mm, gfp_t gfp)
{
struct ptdesc *ptdesc;
ptdesc = pagetable_alloc(gfp, 0); // [3]
// [...]
}
static inline struct ptdesc *pagetable_alloc(gfp_t gfp, unsigned int order)
{
struct page *page = alloc_pages(gfp | __GFP_COMP, order);
// [...]
}
The function vma_alloc_zeroed_movable_folio() calls __alloc_pages() [5] to allocate a page for the PTE. It then wraps the allocated page into a folio interface and returns it to the caller [6].
#define vma_alloc_zeroed_movable_folio(vma, vaddr) \
vma_alloc_folio(GFP_HIGHUSER_MOVABLE | __GFP_ZERO, 0, vma, vaddr, false)
struct folio *vma_alloc_folio(gfp_t gfp, int order, struct vm_area_struct *vma,
unsigned long addr, bool hugepage)
{
// [...]
folio = __folio_alloc(gfp, order, preferred_nid, nmask);
// [...]
return folio;
}
struct folio *__folio_alloc(gfp_t gfp, unsigned int order, int preferred_nid,
nodemask_t *nodemask)
{
struct page *page = __alloc_pages(gfp | __GFP_COMP, order, // [5]
preferred_nid, nodemask);
return page_rmappable_folio(page); // [6]
}
Some details of __alloc_pages() are omitted here. It internally calls __rmqueue_pcplist() to request additional pages from the buddy system and store them in the per-CPU cache [7]. Subsequent requests can then directly return pages from this cache.
The number of preallocated pages is determined by pcp->batch, but it is adjusted based on the request size. When the request is for a single page (i.e., order = 0), this value is 31.
static inline
struct page *__rmqueue_pcplist(struct zone *zone, unsigned int order,
int migratetype,
unsigned int alloc_flags,
struct per_cpu_pages *pcp,
struct list_head *list)
{
struct page *page;
do {
if (list_empty(list)) {
int batch = READ_ONCE(pcp->batch /* 31 */);
// [...]
alloced = rmqueue_bulk(zone, order, // [7]
batch, list,
migratetype, alloc_flags);
}
}
}
After rmqueue_bulk() requests memory from the buddy system, it calls __mod_zone_page_state() [8] to update the zone state, adjusting the recorded number of free pages [9].
static int rmqueue_bulk(struct zone *zone, unsigned int order,
unsigned long count, struct list_head *list,
int migratetype, unsigned int alloc_flags)
{
for (i = 0; i < count; ++i) {
struct page *page = __rmqueue(zone, order, migratetype,
alloc_flags);
// [...]
}
__mod_zone_page_state(zone, NR_FREE_PAGES, -(i << order)); // [8]
// [...]
}
static inline void __mod_zone_page_state(struct zone *zone,
enum zone_stat_item item, long delta)
{
zone_page_state_add(delta, zone, item);
}
static inline void zone_page_state_add(long x, struct zone *zone,
enum zone_stat_item item)
{
atomic_long_add(x, &zone->vm_stat[item]); // [9]
atomic_long_add(x, &vm_zone_stat[item]);
}
2. Out Of Memory
2.1. OOM Killer
When memory is insufficient, the function get_page_from_freelist() fails to retrieve an available page and returns NULL [1]. In this case, __alloc_pages_slowpath() is invoked [2] to handle the allocation failure.
struct page *__alloc_pages(gfp_t gfp, unsigned int order, int preferred_nid,
nodemask_t *nodemask)
{
struct page *page;
// [...]
alloc_gfp = gfp;
// [...]
page = get_page_from_freelist(alloc_gfp, order, alloc_flags, &ac); // [1]
if (likely(page))
goto out;
// [...]
page = __alloc_pages_slowpath(alloc_gfp, order, &ac); // [2]
// [...]
}
The function __alloc_pages_may_oom() calls itself and may trigger the OOM killer. If a page is successfully allocated, it means OOM did not occur. Otherwise, after the OOM handler has finished processing, the function will attempt to allocate memory again [3].
static inline struct page *
__alloc_pages_slowpath(gfp_t gfp_mask, unsigned int order,
struct alloc_context *ac)
{
// [...]
retry:
// [...]
page = __alloc_pages_may_oom(gfp_mask, order, ac, &did_some_progress);
if (page)
goto got_pg;
// [...]
if (did_some_progress) {
no_progress_loops = 0;
goto retry; // [3]
}
}
The function __alloc_pages_may_oom() calls out_of_memory() [4] to trigger the OOM killer when a page allocation request fails.
static inline struct page *
__alloc_pages_may_oom(gfp_t gfp_mask, unsigned int order,
const struct alloc_context *ac, unsigned long *did_some_progress)
{
// [...]
page = get_page_from_freelist((gfp_mask | __GFP_HARDWALL) &
~__GFP_DIRECT_RECLAIM, order,
ALLOC_WMARK_HIGH|ALLOC_CPUSET, ac);
// [...]
if (out_of_memory(&oc) /* ... */) { // [4]
*did_some_progress = 1;
// [...]
}
}
If the global variable oom_killer_disabled is true [5], the OOM killer will not be triggered. By default, this variable is false.
When the OOM killer is triggered, it first calls select_bad_process() to choose a process to kill. Then, it invokes oom_kill_process() to terminate the selected process and free up memory.
bool out_of_memory(struct oom_control *oc)
{
unsigned long freed = 0;
if (oom_killer_disabled) // [5]
return false;
// [...]
if (!(oc->gfp_mask & __GFP_FS) && !is_memcg_oom(oc))
return true;
oc->constraint = constrained_alloc(oc);
if (oc->constraint != CONSTRAINT_MEMORY_POLICY)
oc->nodemask = NULL;
// [...]
check_panic_on_oom(oc); // panic if panic_on_oom == true
// [...]
select_bad_process(oc);
// [...]
if (oc->chosen && oc->chosen != (void *)-1UL)
oom_kill_process(oc, "Out of memory");
return !!oc->chosen;
}
The function select_bad_process() iterates each process and calls oom_evaluate_task() to evaluate a score for each one. This score determines which process is the best candidate to be killed by the OOM killer.
static void select_bad_process(struct oom_control *oc)
{
oc->chosen_points = LONG_MIN;
struct task_struct *p;
rcu_read_lock();
for_each_process(p)
if (oom_evaluate_task(p, oc))
break;
rcu_read_unlock();
}
The function oom_evaluate_task() first skips processes that cannot be killed. It then calls oom_badness() [6] to evaluate a score based on the process’s memory usage and other factors. The process with the highest score is selected to be killed.
static int oom_evaluate_task(struct task_struct *task, void *arg)
{
struct oom_control *oc = arg;
long points;
if (oom_unkillable_task(task))
goto next;
if (!is_memcg_oom(oc) && !oom_cpuset_eligible(task, oc))
goto next;
// [...]
if (!is_sysrq_oom(oc) && tsk_is_oom_victim(task)) {
if (test_bit(MMF_OOM_SKIP, &task->signal->oom_mm->flags))
goto next;
goto abort;
}
// [...]
points = oom_badness(task, oc->totalpages); // [6]
if (points == LONG_MIN || points < oc->chosen_points)
goto next;
select:
if (oc->chosen)
put_task_struct(oc->chosen);
get_task_struct(task);
oc->chosen = task;
oc->chosen_points = points;
next:
return 0;
abort:
if (oc->chosen)
put_task_struct(oc->chosen);
oc->chosen = (void *)-1UL;
return 1;
}
After selecting the victim process, the function oom_kill_process() first logs its process information into the kernel buffer [7]. Then, it calls __oom_kill_process(), which sends a kill process request to the OOM reaper thread [8].
static void oom_kill_process(struct oom_control *oc, const char *message)
{
// [...]
if (__ratelimit(&oom_rs))
dump_header(oc, victim); // [7]
// [...]
__oom_kill_process(victim, message); // <-----------------
}
static void __oom_kill_process(struct task_struct *victim, const char *message)
{
// [...]
if (can_oom_reap) // true
queue_oom_reaper(victim); // <-----------------
// [...]
}
#define OOM_REAPER_DELAY (2*HZ)
static void queue_oom_reaper(struct task_struct *tsk)
{
// [...]
timer_setup(&tsk->oom_reaper_timer, wake_oom_reaper, 0);
tsk->oom_reaper_timer.expires = jiffies + OOM_REAPER_DELAY;
add_timer(&tsk->oom_reaper_timer); // [8]
}
The output log information is as follows:
[ 687.142364] enomem-1 invoked oom-killer: gfp_mask=0x140dca(GFP_HIGHUSER_MOVABLE|__GFP_COMP|__GFP_ZERO), order=0, oom_score_adj=0
...
[ 687.142841] Call Trace:
[ 687.142898] <TASK>
[ 687.142987] dump_stack_lvl+0x43/0x60
[ 687.143149] dump_header+0x4a/0x240
[ 687.143312] oom_kill_process+0x101/0x190
[ 687.143500] out_of_memory+0x242/0x590
[ 687.143560] __alloc_pages_slowpath.constprop.0+0xaaf/0xe90
...
[ 687.143617] populate_vma_page_range+0x74/0xb0
[ 687.143617] __mm_populate+0x11b/0x1a0
[ 687.143617] vm_mmap_pgoff+0x14c/0x1b0
[ 687.143617] do_syscall_64+0x5d/0x90
...
[ 687.143617] </TASK>
[ 687.147143] Mem-Info:
...
[ 687.152814] Tasks state (memory values in pages):
[ 687.152894] [ pid ] uid tgid total_vm rss pgtables_bytes swapents oom_score_adj name
[ 687.153155] [ 175] 1000 175 2715 192 69632 0 0 nsjail
[ 687.153529] [ 178] 1000 178 1065 128 53248 0 0 bash
[ 687.153635] [ 185] 1000 185 830068 829792 6705152 0 0 enomem-1
[ 687.153765] oom-kill:constraint=CONSTRAINT_NONE,nodemask=(null),cpuset=/,mems_allowed=0,global_oom,task_memcg=/,task=enomem-1,pid=185,uid=1000
[ 687.154225] Out of memory: Killed process 185 (enomem-1) total-vm:3320272kB, anon-rss:3319168kB, file-rss:0kB, shmem-rss:0kB, UID:1000 pgtables:6548kB oom_score_adj:0
Finally, when __alloc_pages_slowpath() detects that the parameter did_some_progress is set to true, it attempts to allocate memory again — this time, it succeeds.
2.2. Disable OOM Killer
The variable oom_killer_disabled is set to true by the function oom_killer_disable(), which is indirectly called by the Linux hibernation subsystem. However, in the kernelCTF environment, hibernation is not supported.
bool oom_killer_disable(signed long timeout)
{
signed long ret;
// [...]
oom_killer_disabled = true;
// [...]
ret = wait_event_interruptible_timeout(oom_victims_wait,
!atomic_read(&oom_victims), timeout);
if (ret <= 0) {
oom_killer_enable();
return false;
}
pr_info("OOM killer disabled.\n");
return true;
}
As long as the OOM killer can be disabled, memory allocation failures will return NULL when memory is lacking.
However, since there is no known way to disable the OOM killer, it is unlikely to reliably trigger a -ENOMEM error currently.
3. Memory Monitoring
The system’s memory usage status can be obtained from the files /proc/zoneinfo and /proc/meminfo. The implementation of both files retrieves data from the variable vm_zone_stat[].
static int __init proc_meminfo_init(void)
{
struct proc_dir_entry *pde;
pde = proc_create_single("meminfo", 0, NULL, meminfo_proc_show); // <-----------------
// [...]
}
static int meminfo_proc_show(struct seq_file *m, void *v)
{
struct sysinfo i;
// [...]
si_meminfo(&i); // <-----------------
// [...]
show_val_kb(m, "MemFree: ", i.freeram);
// [...]
}
void si_meminfo(struct sysinfo *val)
{
// [...]
val->freeram = global_zone_page_state(NR_FREE_PAGES); // <-----------------
// [...]
}
static inline unsigned long global_zone_page_state(enum zone_stat_item item)
{
long x = atomic_long_read(&vm_zone_stat[item]); // <-----------------
return x;
}
enum zone_stat_item {
NR_FREE_PAGES,
// [...]
NR_ZONE_ACTIVE_ANON,
// [...]
};
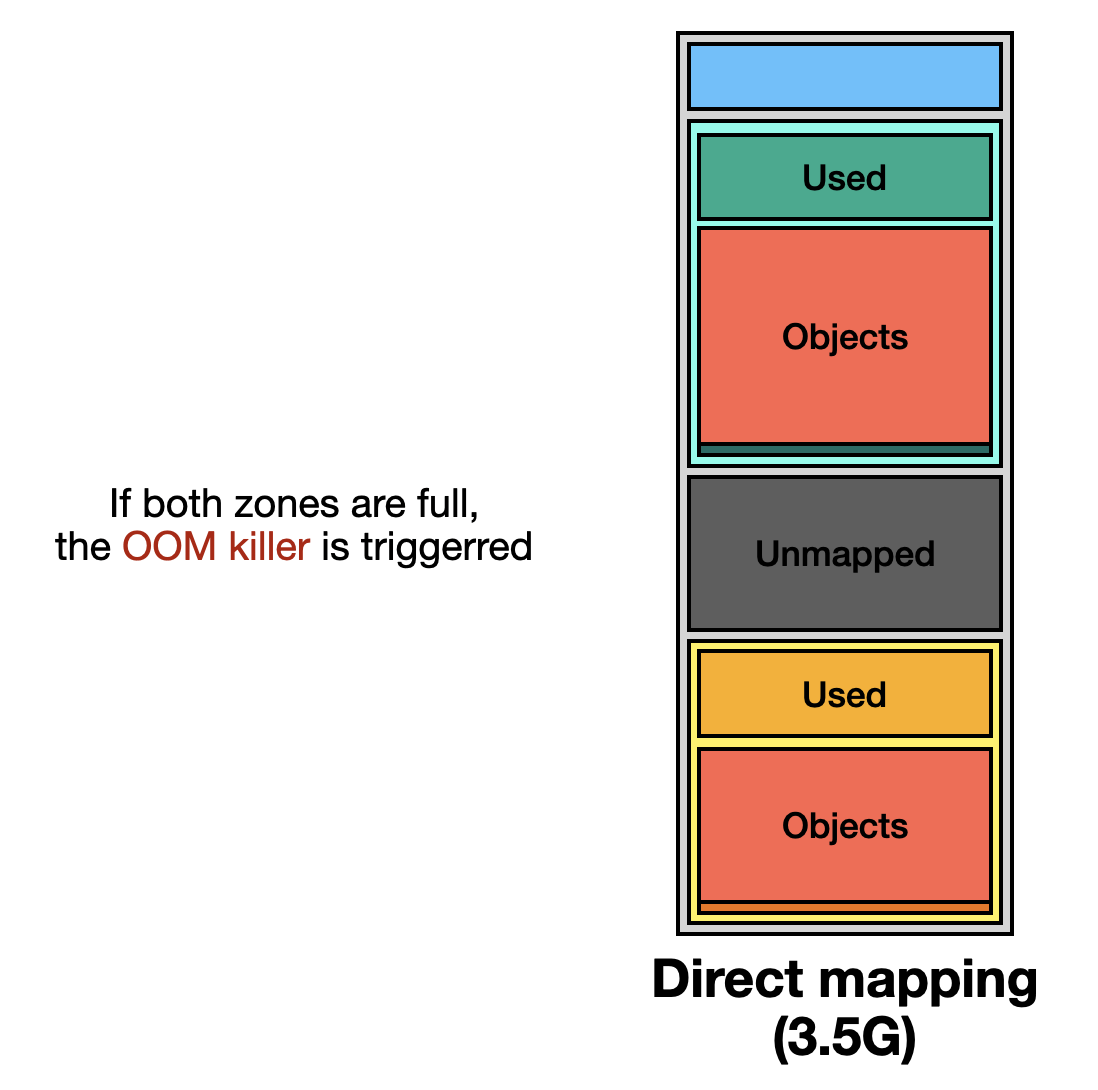
The data obtained from both files is mostly the same, but /proc/zoneinfo provides more detailed information on the memory usage of individual zones. For an introduction to Zones, you can refer to previous article How Does Linux Direct Mapping Work?. The environment discussed in this article has 3.5 GB of RAM.
We can obtain the runtime status of each zone from /proc/zoneinfo:
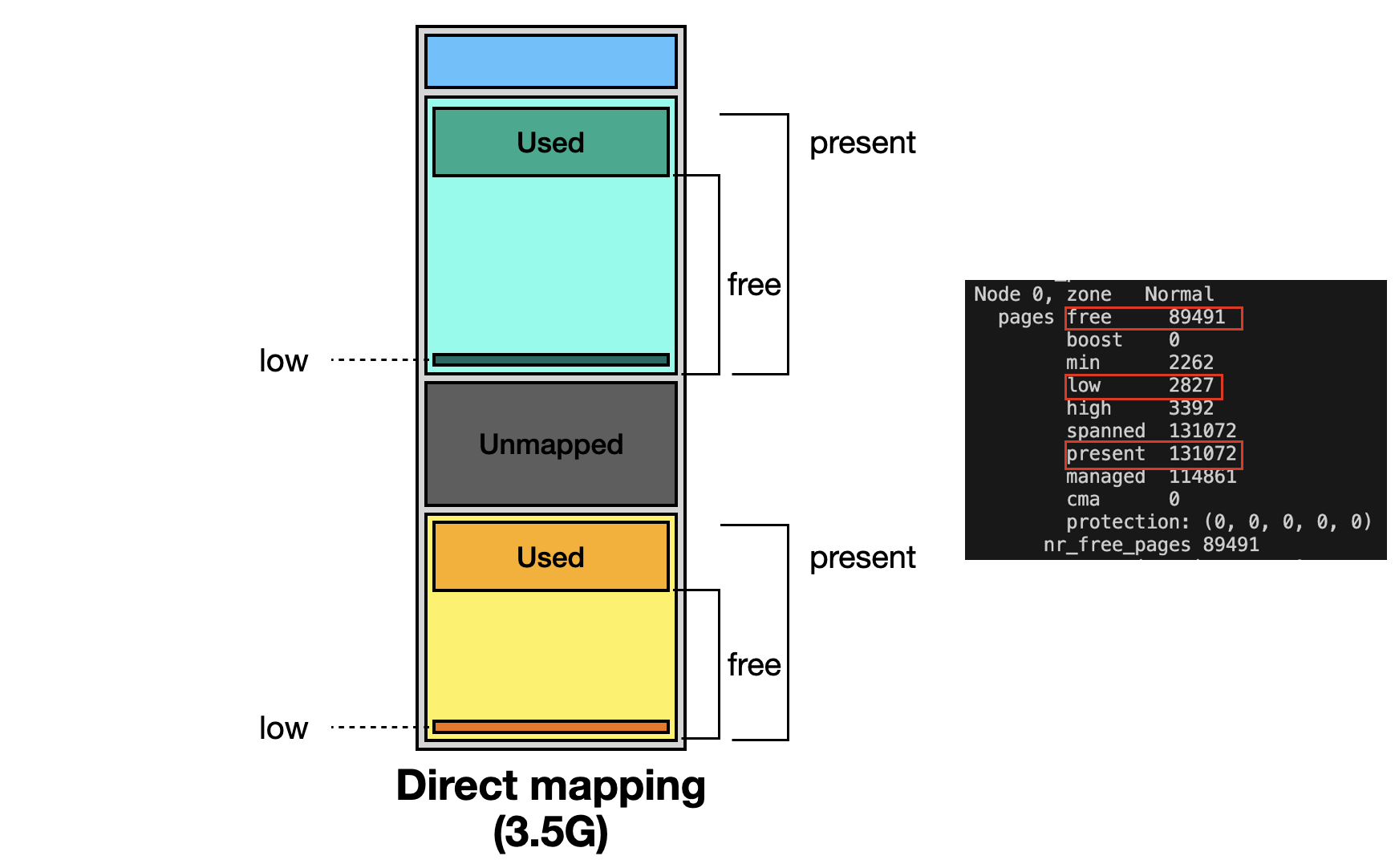
present: Indicates the total number of pages available in the zone.free: Represents the number of free pages still available for allocation.low: Defines the free page threshold — the minimum number of free pages required in the zone.
Node 0, zone DMA32
pages free 480429
[...]
low 18196
[...]
present 782298
[...]
Node 0, zone Normal
pages free 87384
[...]
low 2827
[...]
present 131072
[...]
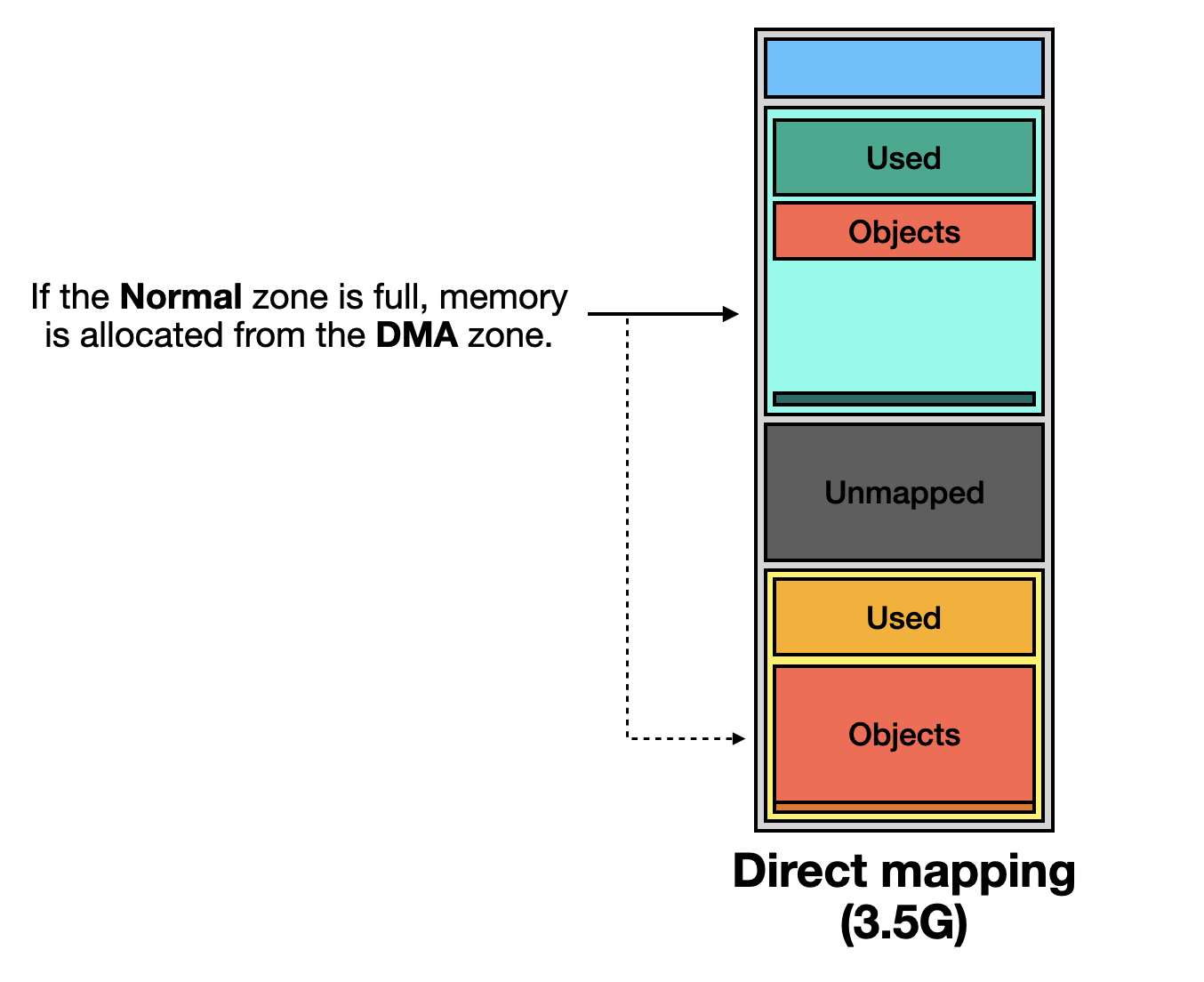
If the number of free pages falls below the low threshold, subsequent memory requests will be handled by other zones instead.
4. Summary
I will use illustrations to explain the entire flow, as it will make the concepts easier to understand.
First, we assume the machine has 3.5 of RAM.
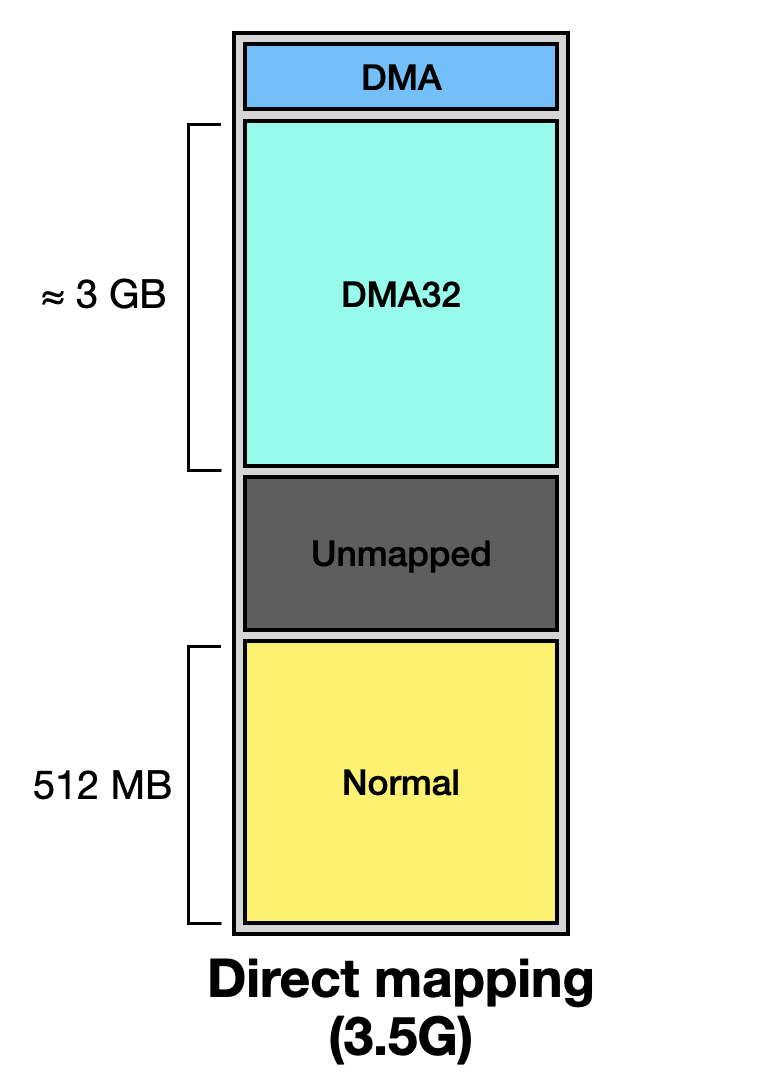
Next, we map the zone fields of /proc/zoneinfo to direct mapping.
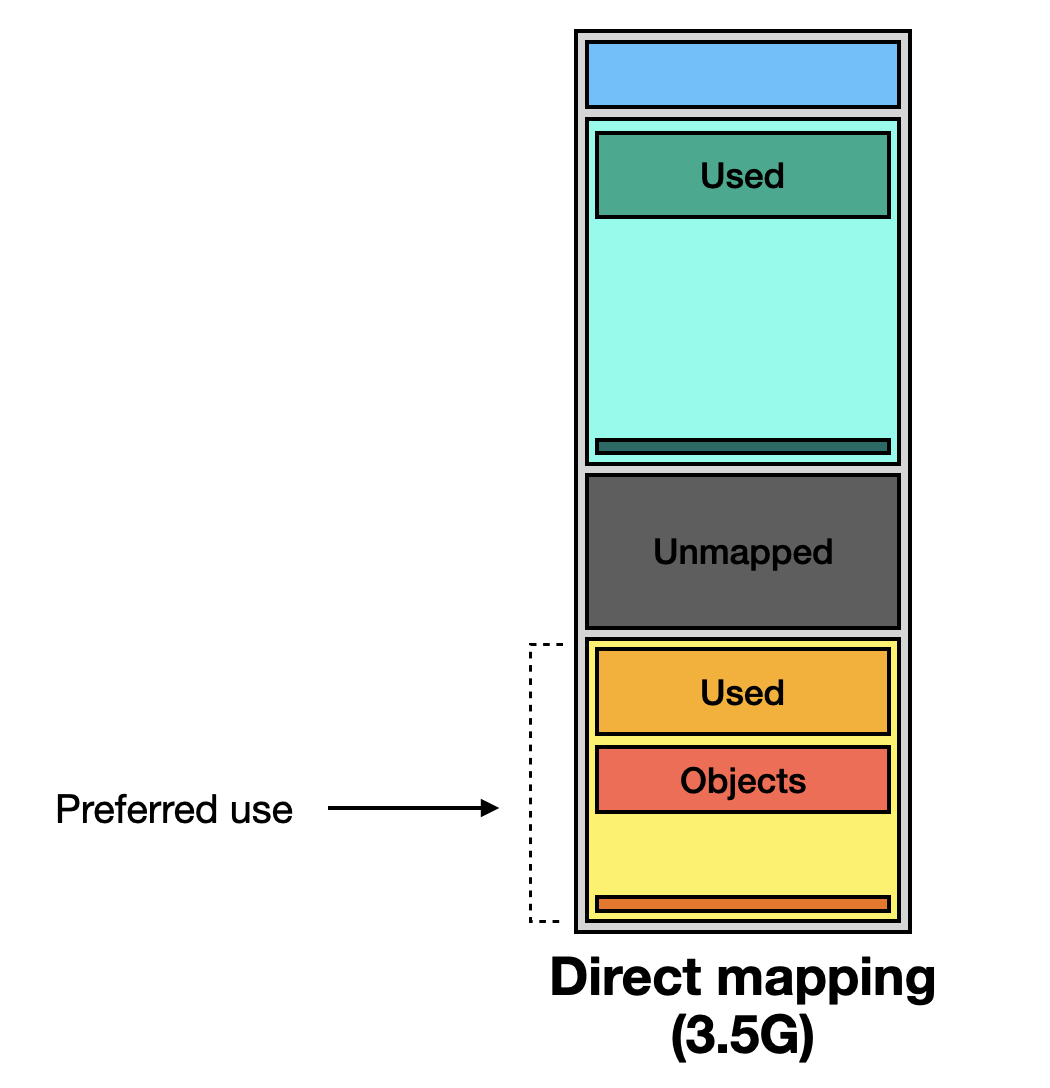
The Normal zone is the preferred memory zone for the kernel.
Once free page usage reaches the low threshold, the kernel selects another zone for memory allocation.
If no memory is available, the OOM killer selects a process to kill and frees its memory.
5. Others
Assuming we are operating within a cgroup and have the ability to create subgroups, we can configure memory limits and the OOM killer as follows:
# Mount the memory cgroup
mount -t cgroup -o memory cgroup_memory /tmp
# Create a subgroup
mkdir /tmp/aaa
# Set memory usage limit
echo $((500 * 1024)) > /tmp/aaa/memory.limit_in_bytes
# Add the current process to the cgroup
echo $$ > /tmp/aaa/cgroup.procs
# Enable the OOM killer (enabled by default)
## echo 0 > /tmp/aaa/memory.oom_control
# Trigger an OOM condition
./poc
# Disable the OOM killer — the process will hang when memory is insufficient
echo 1 > /tmp/aaa/memory.oom_control
When memory allocation fails, the kernel returns a NULL pointer instead of killing the process:
kmalloc(32, GFP_KERNEL_ACCOUNT)
[...]
=> slab_alloc_node() <------ return NULL
=> slab_pre_alloc_hook() <------ return false
=> memcg_slab_pre_alloc_hook()
=> obj_cgroup_charge()
=> try_charge_memcg()
=> mem_cgroup_out_of_memory()
=> out_of_memory() <------ trigger OOM